基于BDOS发布图数据库应用,分析数据背后的关联关系
简介
在科技业,数据库是一个整体规模不大但专业度极高的领域,传统数据库时代还诞生了许多行业巨头;但在新一波数字技术革命下,大数据、人工智能应用的兴起,人们对于数据库的期待已经不再是数据的分类、存储和查询等,而是如何洞察数据内在的联系。
传统的数据库虽然在名称上被称为“关系型数据库”,但在处理数据关系上并不擅长。在大数据、人工智能大行其道的今天,一种新型的数据库开始崛起——图数据库。据了解,图数据库源起欧拉图理论,也可称为面向/基于图的数据库,它是以“图”这种数据结构存储和查询数据,而不是存储图片的数据库。相比较传统的数据库,图数据库的数据模型主要是以节点和关系(边)来体现,可以快速解决复杂的关系问题。
传统的关系型数据库和图数据库有以下三大区别:
- 第一,存储模型不一样。关系型数据库的数学模型是表格,但这并不是表示关系的最好方法。比如,一个人拥有很多的个人信息,身份证号、学校、住址等等,但这些信息往往又被存到不同的表格中,真正想全面得到一个人的信息就必须将不同表中的信息拼凑起来;但图数据库并非如此,身份证号和学校等都是一个个节点,这些节点是天然连接在一起的。
第二,计算模型不一样。关系型数据库的计算模型是扫描、拼凑,这就导致数据的计算量很大,但效率很低;而图数据库不同,它从节点出发,只寻找与节点相关的数据,这样的效率更好。
第三,数据的查询方式不同。在关系型数据库中,数据的查询指标往往比较单一,但在人工智能、机器学习时代,人们要挖掘数据更深层次的关系,并实现动态、实时的查询,图数据库所表达出的数据之间的关系则更为全面。
事实上,数据库技术的进化很大程度上也源于算法、算力的提升。过去,大数据算法并不成熟,计算机的性能也不够强大,没有多核、没有并行能力,这些限制在很大程度上制约了图数据库的发展,但今天,这样的基础已经具备。
创立于2012年的TigerGraph是一家专注于图数据库研发和服务的企业,TigerGraph称之为基于“原生”“并行”图(Native Parallel Graph,NPG)技术的全球首个实时图分析平台,相比较而言,该平台的技术优势体现在以下几个方面:
首先,实时计算,不超过1亿个节点和边关联的查询一般不到1秒钟一个服务器就可以完成;
其次,支持数据库的实时增删改查,是可以上线的数据库;
第三,深度关联,用户可以使用TigerGraph针对图的高级开发语言,自己做图模型、做数据录入、做二次开发等。
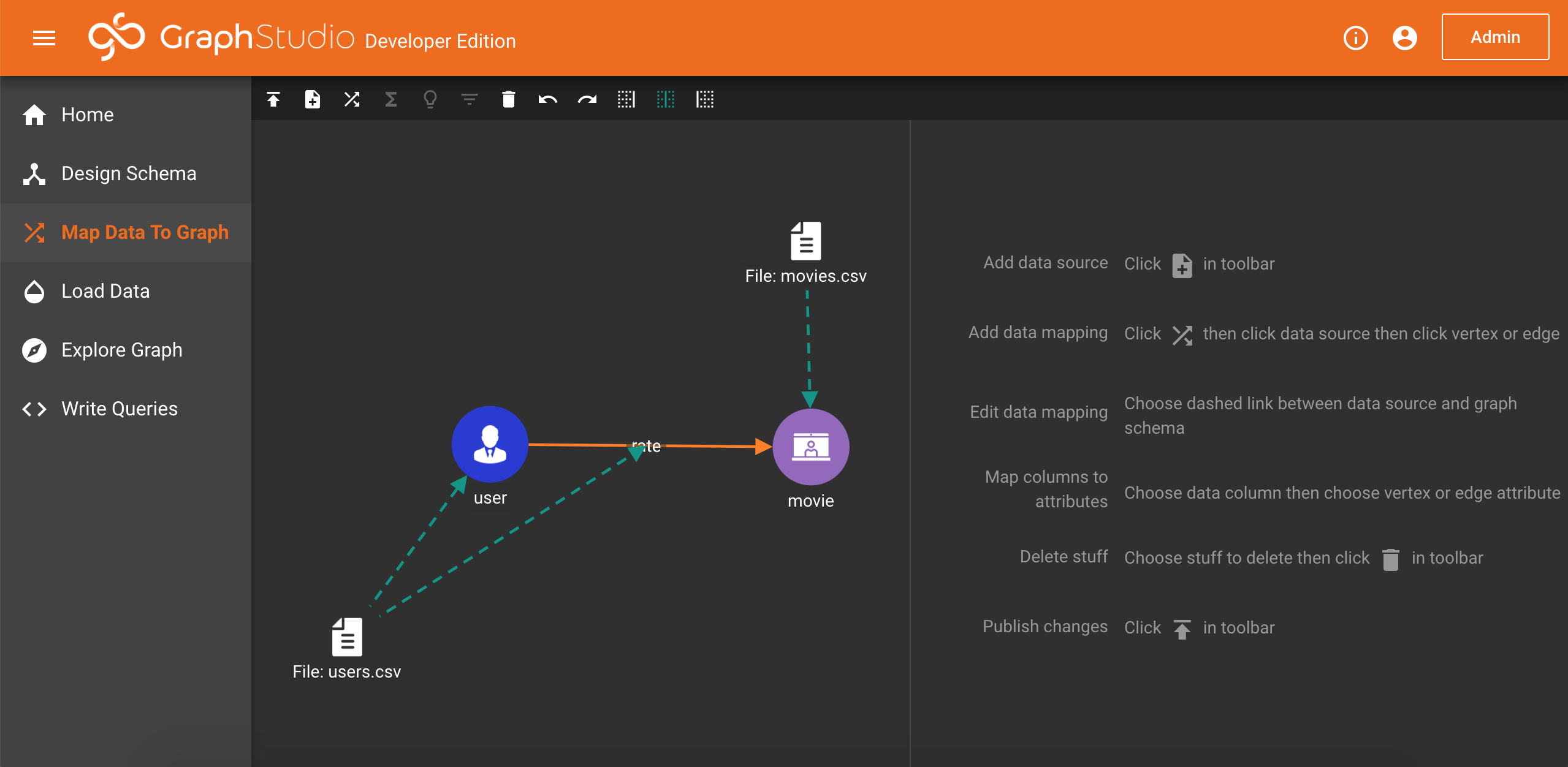
首先我们熟悉一下GraphStudio主界面:

1.Design Schema:可创建图模型,包括顶点和边类型
2.Map Data To Graph:上传源数据,创建数据和图模型直接的映射关系
3.Load Data:真正地加载数据到数据库中,同时显示统计信息
4.Explore Graph:浏览数据,包括随机选取及最短路径等查询工作,方便了解数据库中的实体内容
5.Write Queries:创建查询,自定义编写GSQL,并可直接运行查看结果
图模型简介
在开始浏览数据之前,我们简单介绍一下图模型
简单介绍一下图模型
图模型由若干节点类型(vertex type)和若干边类型(edge type)组成。可以指定边类型的源节点类型(source vertex type)和目标节点类型(target vertex type)。图模型是对现实世界的问题的一种直观的抽象。
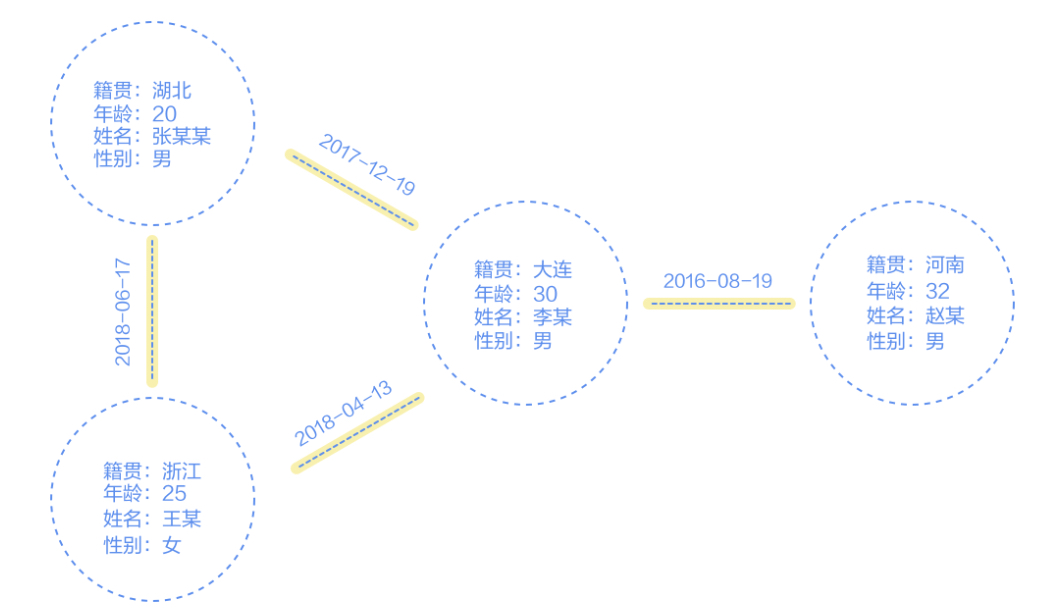
下图可以看作是一个简单的例子,包含4个顶点(以圆圈表示)和4条边(以直线表示)。
圆圈表示具体的人,包含其姓名,性别,年龄,籍贯等属性,在图数据库中称作顶点;直线表示两个人成为朋友,属性为时间,在图数据库中也称为边。
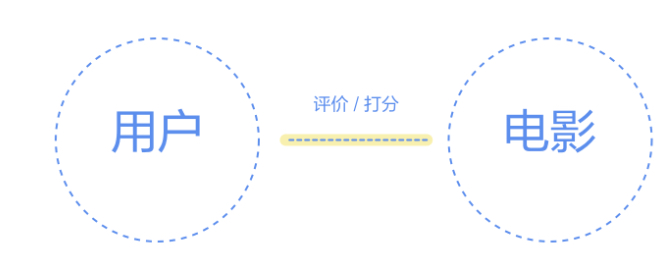
回到实际的例子,目前有两个文件,moives.csv和users.csv,包括电影相关属性数据和用户评分数据,我们可以很简单的想到这两者之间的关系:就是用户去评价电影,这样就可以提炼出两个顶点–用户(user)和电影(movie),另外还有一条边–评价或者打分(rate)
准备工作
我们系统已经将豆瓣电影的数据导入进去了,你可以点击左侧Map Data To Graph查看其映射关系。
现在来了解一下豆瓣电影数据集结构,你可以把鼠标放在任意类型上面即可查看其字段属性
movie节点:movies.csv:
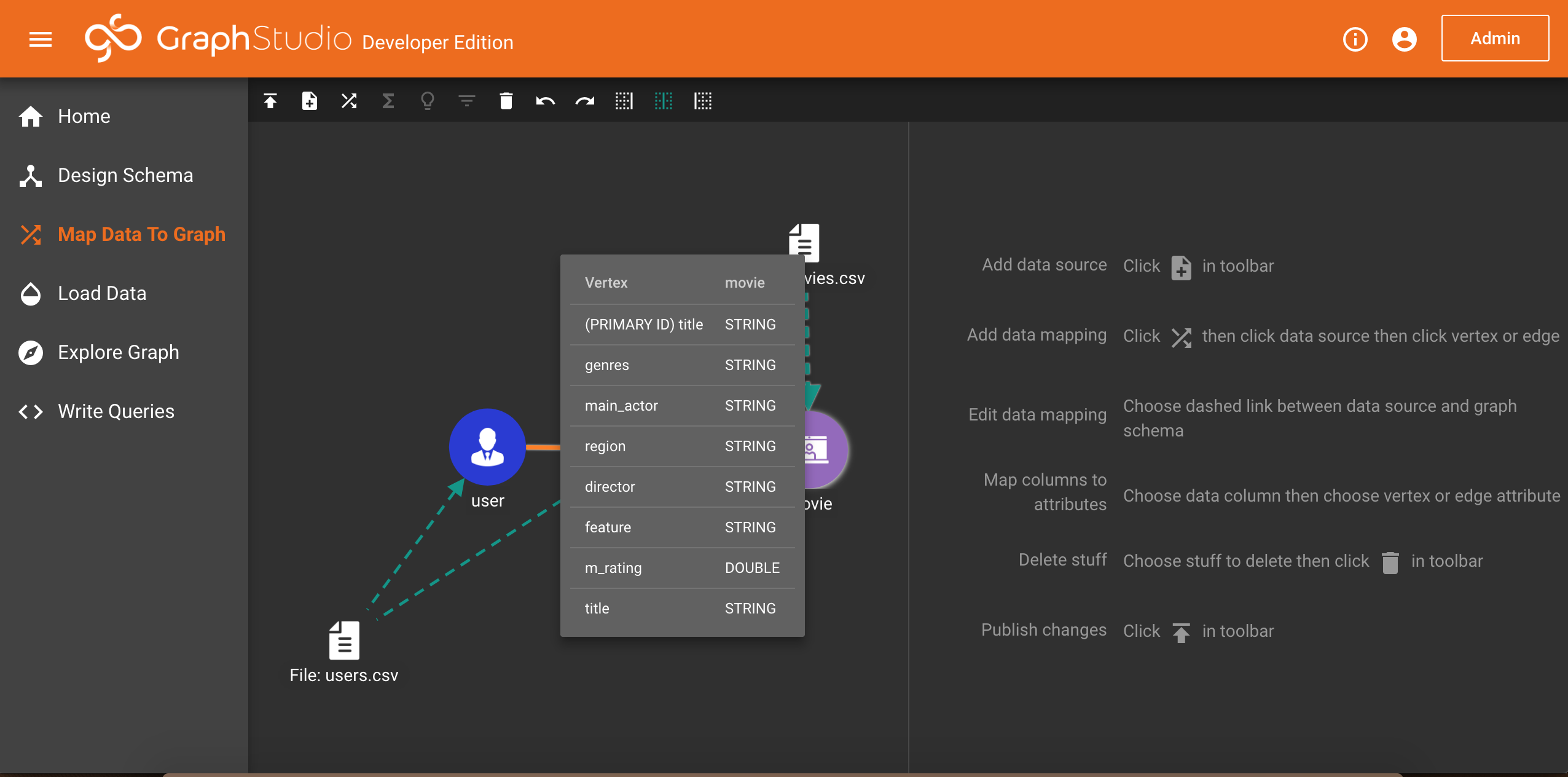

该文件共有93161行,除第1行是表头外,每行用7列表示一部电影,分别为电影类型(genres)、主演(main_actor)、地区(region)、导演(director)、特色(feature)、电影评分(m_rating)和电影名称(title)。
rate边以及user节点:users.csv:
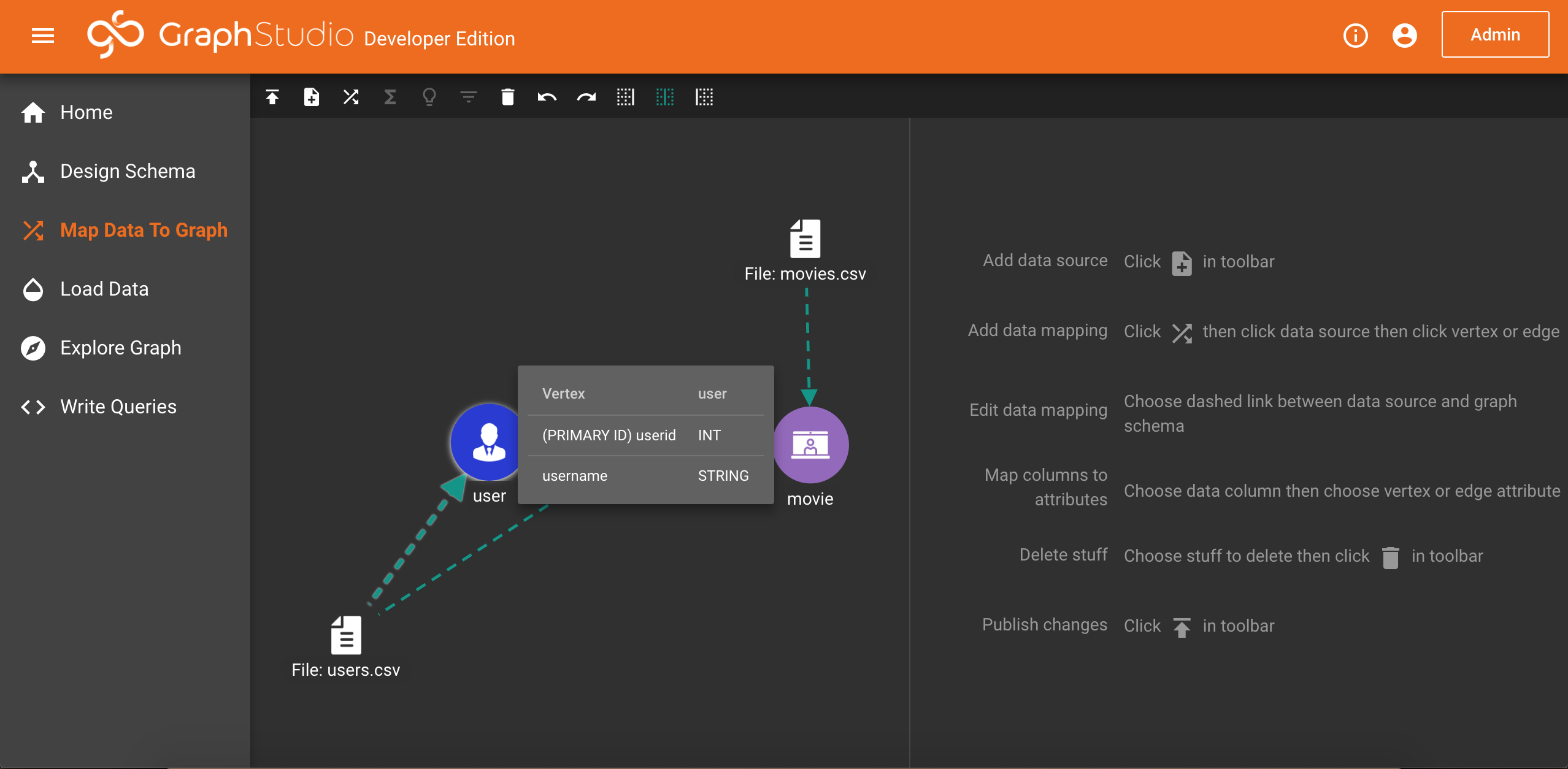
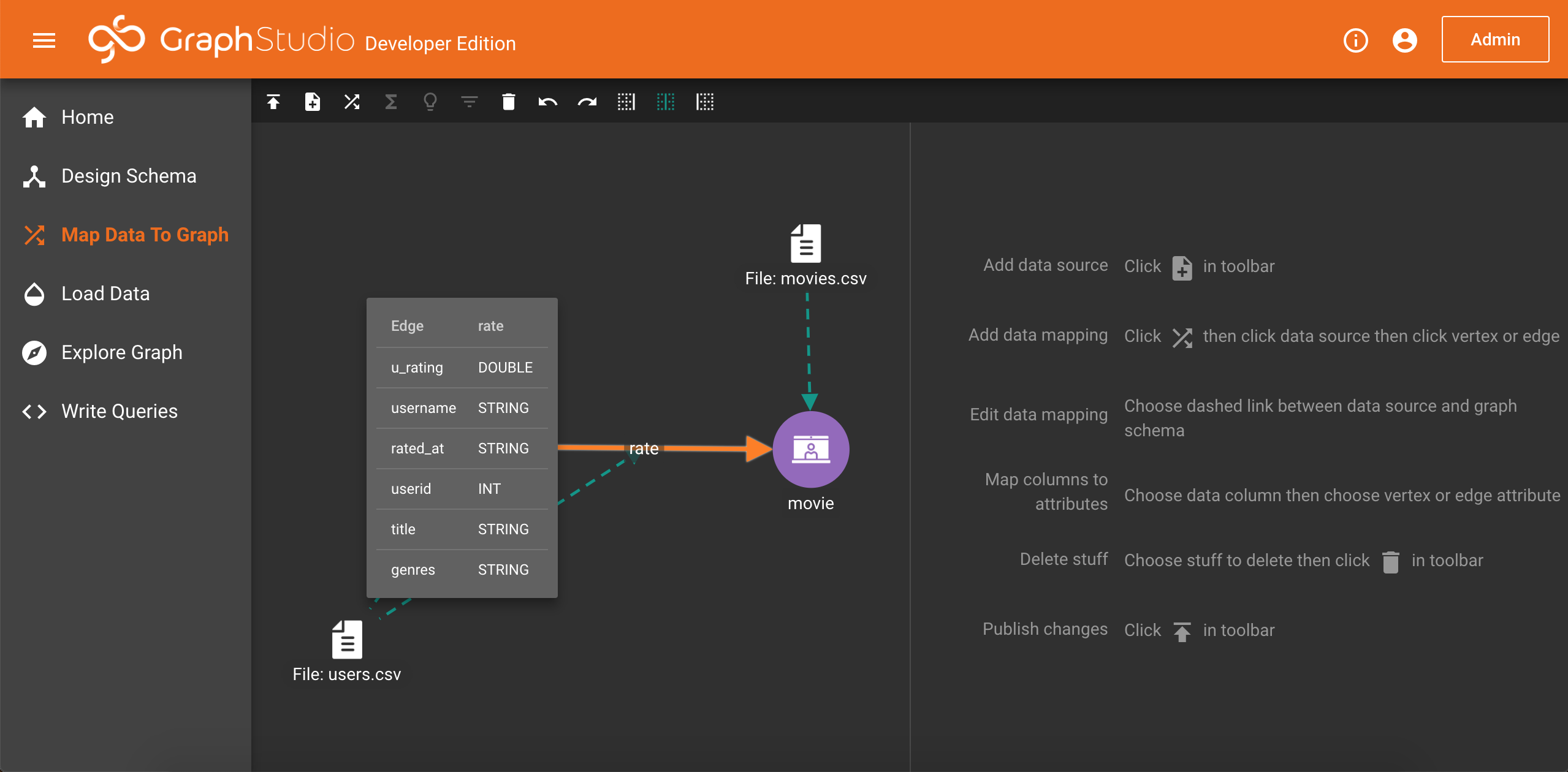

该文件总共有199814行,除第1行是表头外,每行用6列表示一位用户对一部电影的评分,分别为用户评分(u_rating)、用户名(username)、评分时间(rated_at)、用户ID(userid)、电影名(title)、类型(genres)。
浏览图数据
点击左侧的Explore Graph项进入浏览图数据页面:
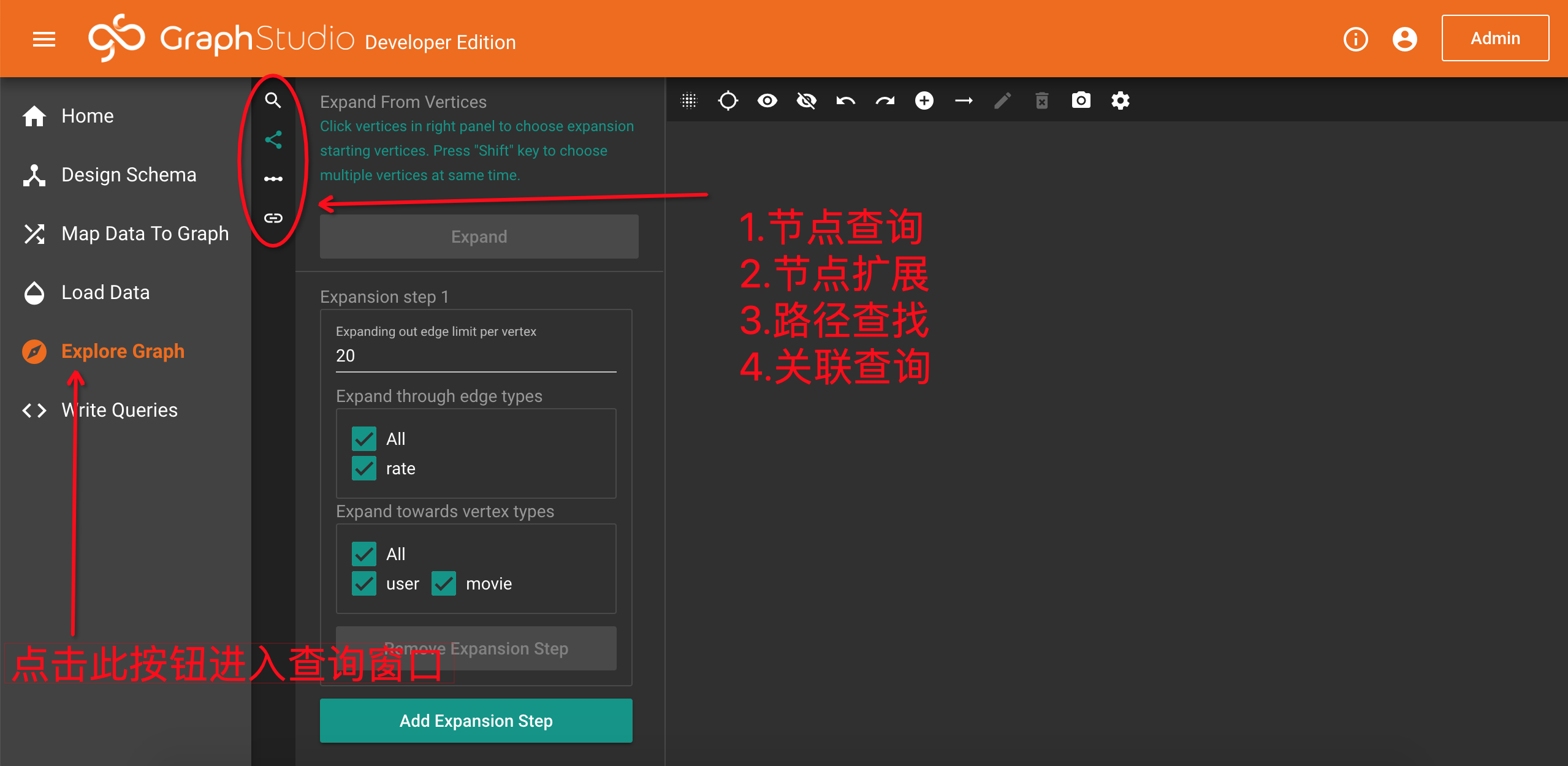
首先我们了解一下不同的功能
1.Search vertices 查找节点,可以输入节点主键查找或者让系统帮你挑选
2.Expand from vertices 可根据指定的节点扩展关系
3.Find paths:给定起始和目标节点,查找之间的路径
4.Find connections 根据指定的节点,查找相互之间的关系
1.Search vertices
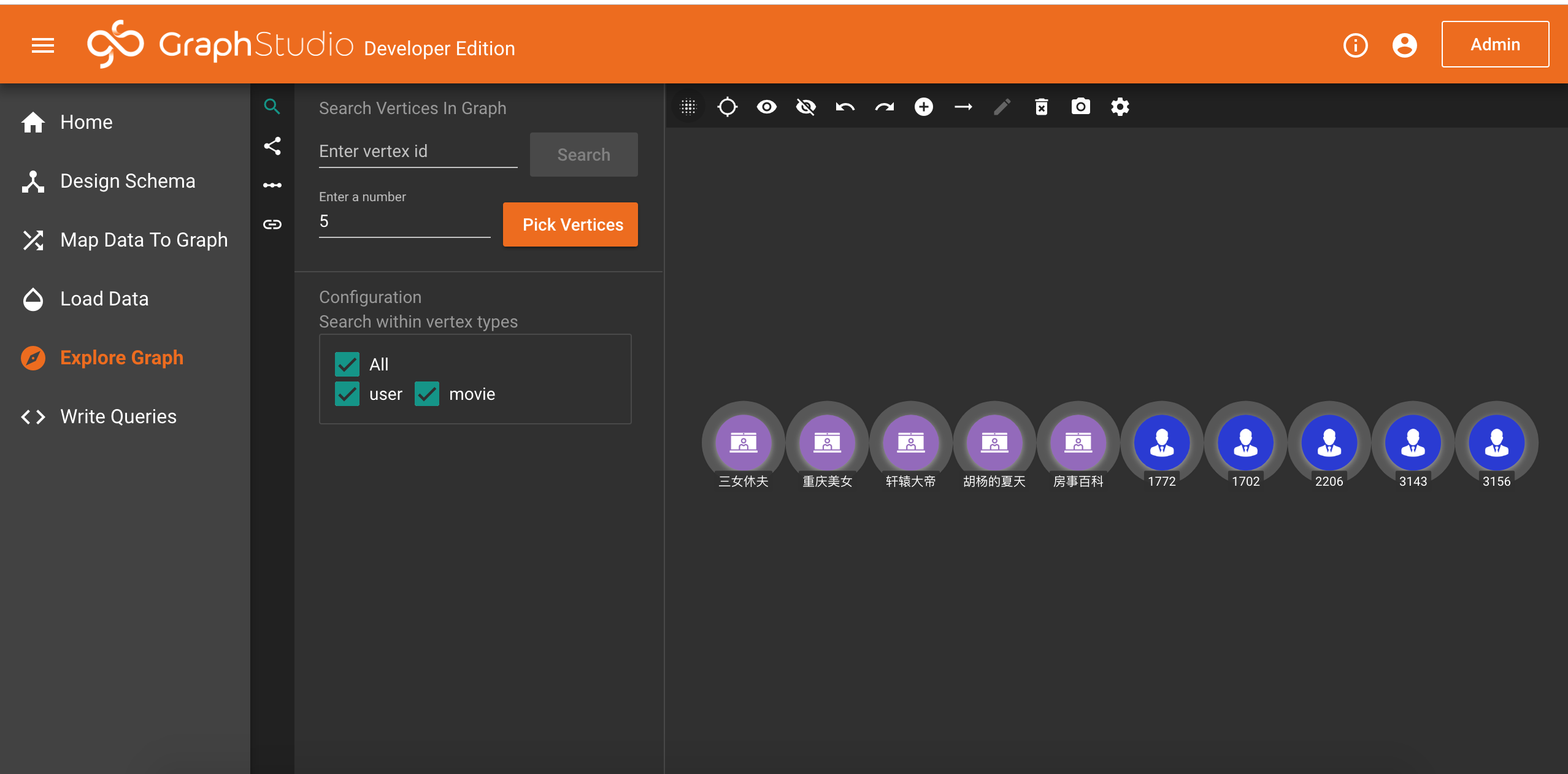
我们可以点击拾取节点(Pick Vertices)按钮,默认会从图数据中拾取5个person节点和5个movie节点。这里的拾取不是随机的,因此每次拾取会返回相同的结果。如果你想要更多的节点,可以修改Enter a number中的数字。这里最大可以输入500。如果你知道节点的主键,可以在Enter vertex id输入框中输入主键的值,然后点击旁边的Search按钮拾取那个节点。配置(Configuration)可以控制拾取节点的类型范围,默认是从全部类型中拾取。你也可以勾选取消一些类型。

如果你不喜欢显示的默认配置,可以点击上方的工具栏进行修改,比如我们设置layout的模式为Tree:
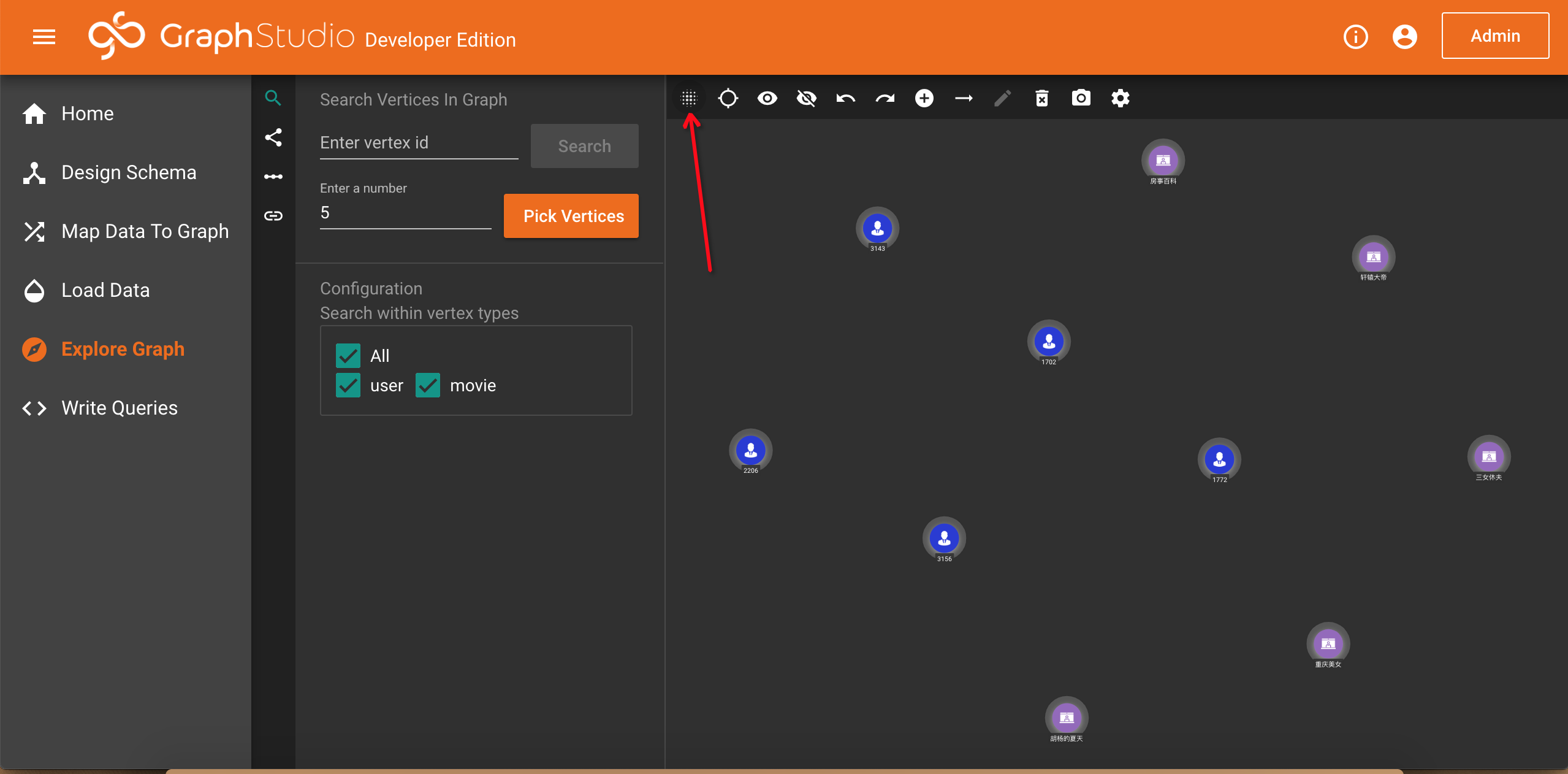
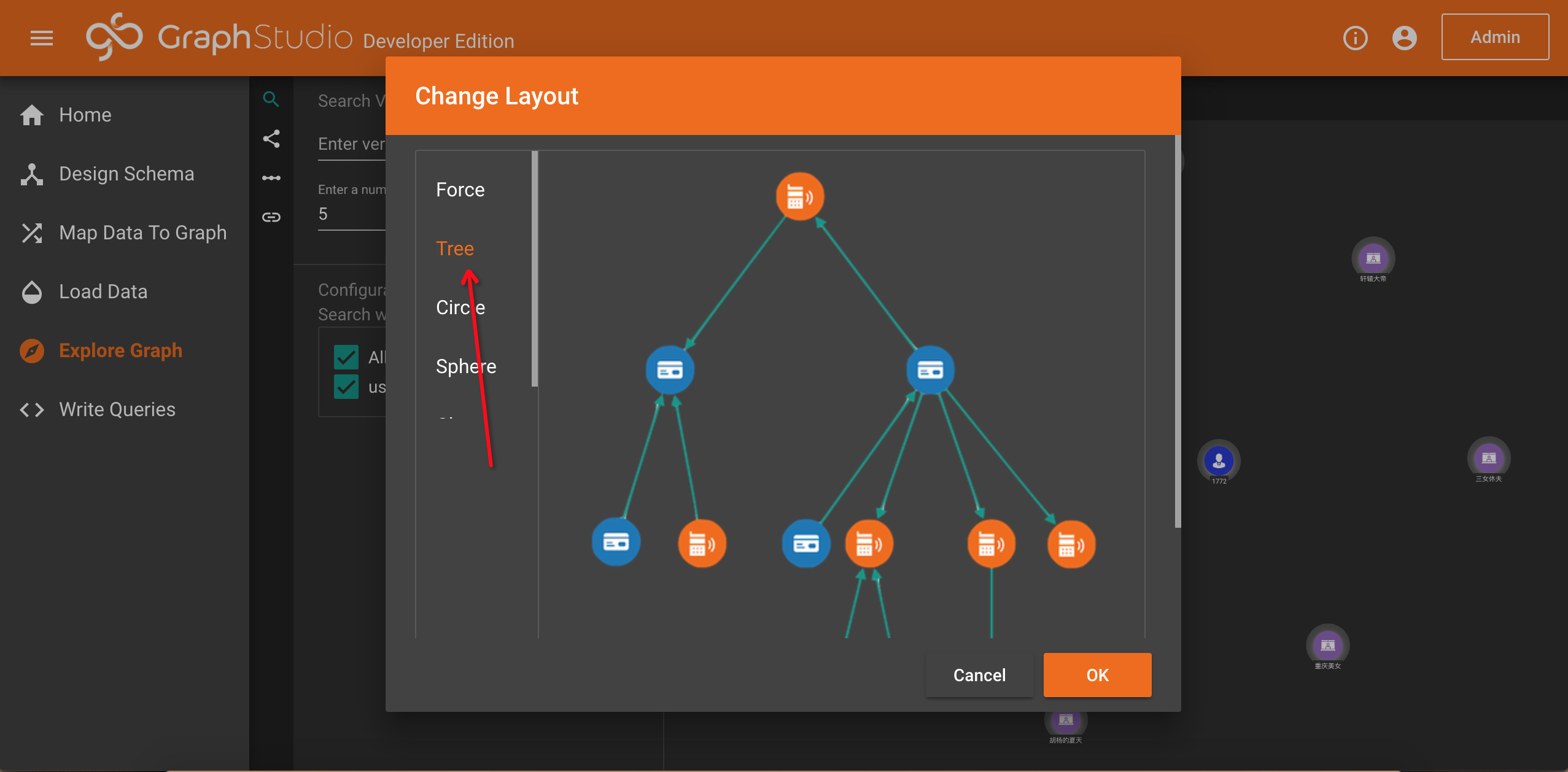
完成修改之后,你可以效果如下。
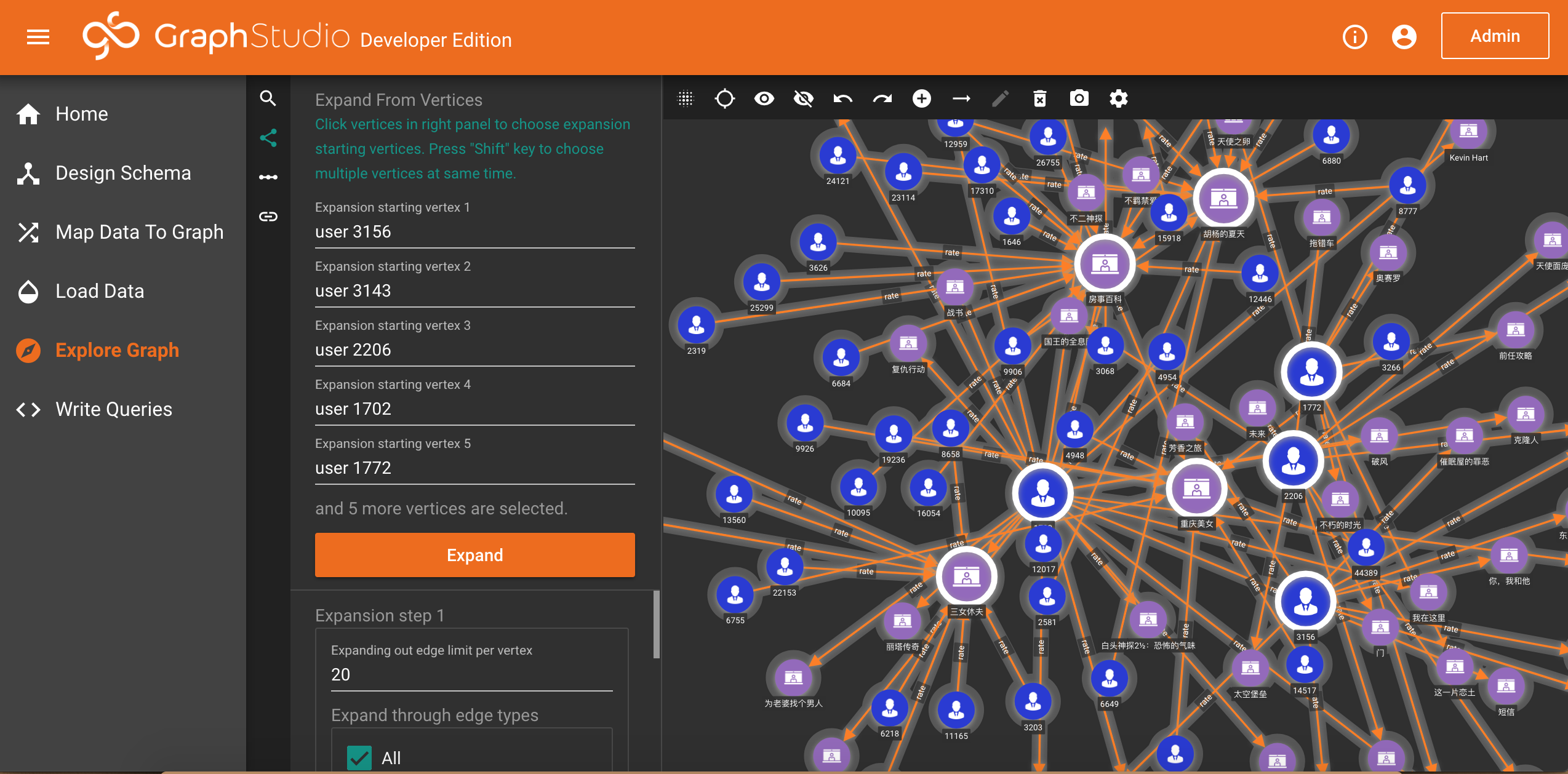
2.Expand from vertices
这里大家可以按照默认设置,点击Expand按钮,直观感受一下效果,同样也可修改默认的显示
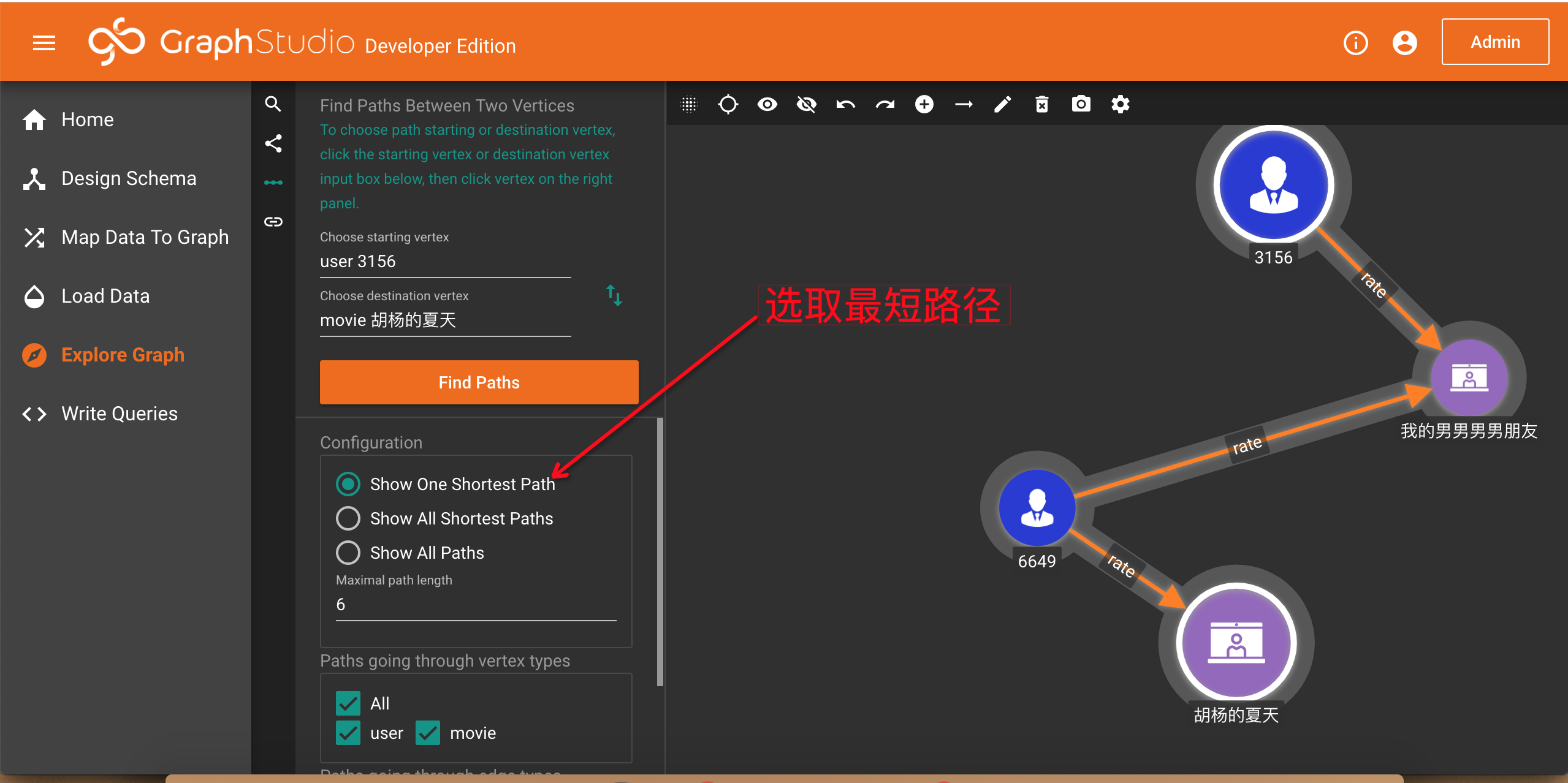
3.Find paths
你可以点击选择起始节点(Choose starting vertex)输入框,再随意点击工作面板中的一个节点。再点击选择目标节点(Choose destination vertex)输入框,再随意选择工作面板中的另一个节点。
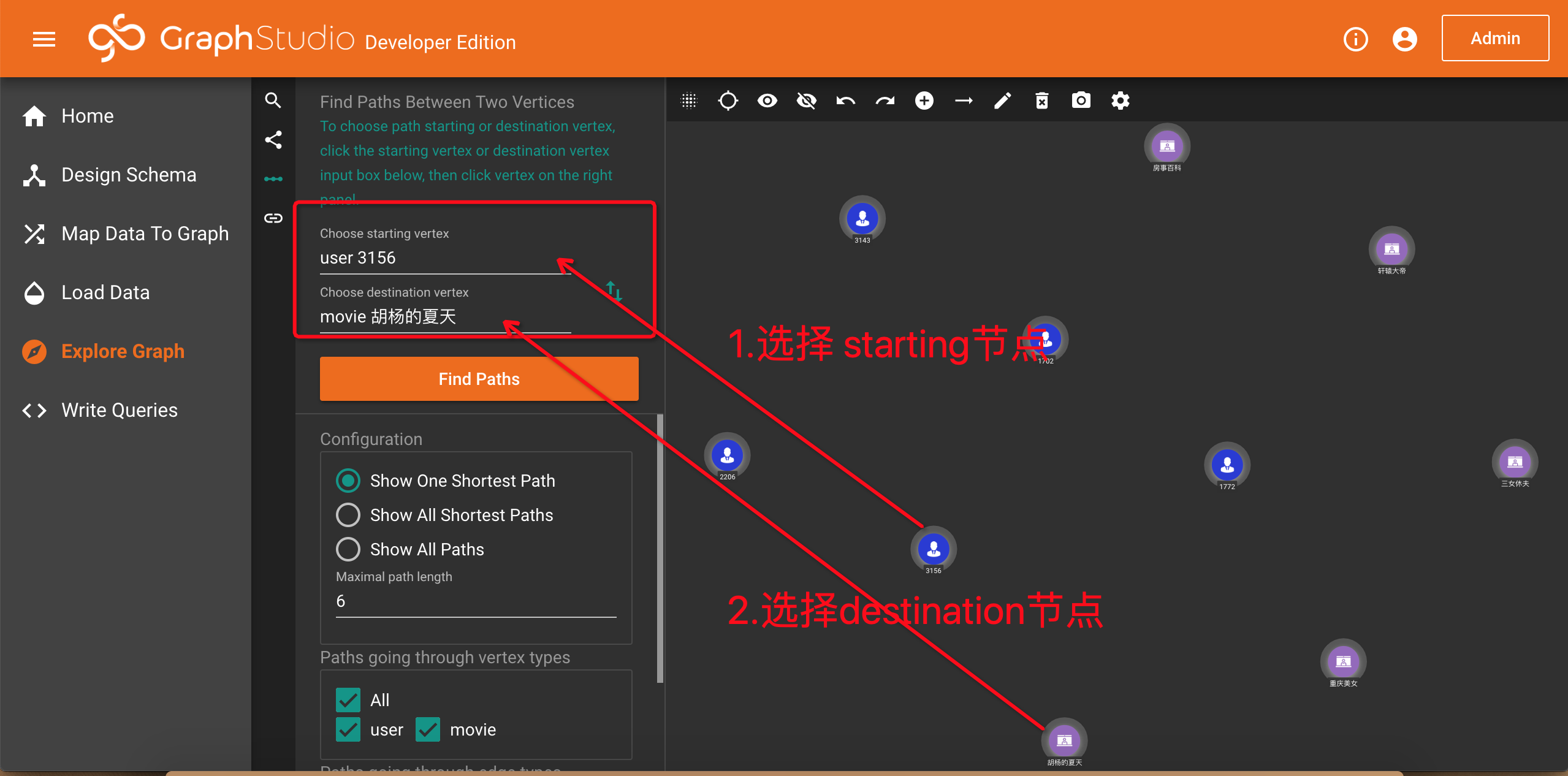
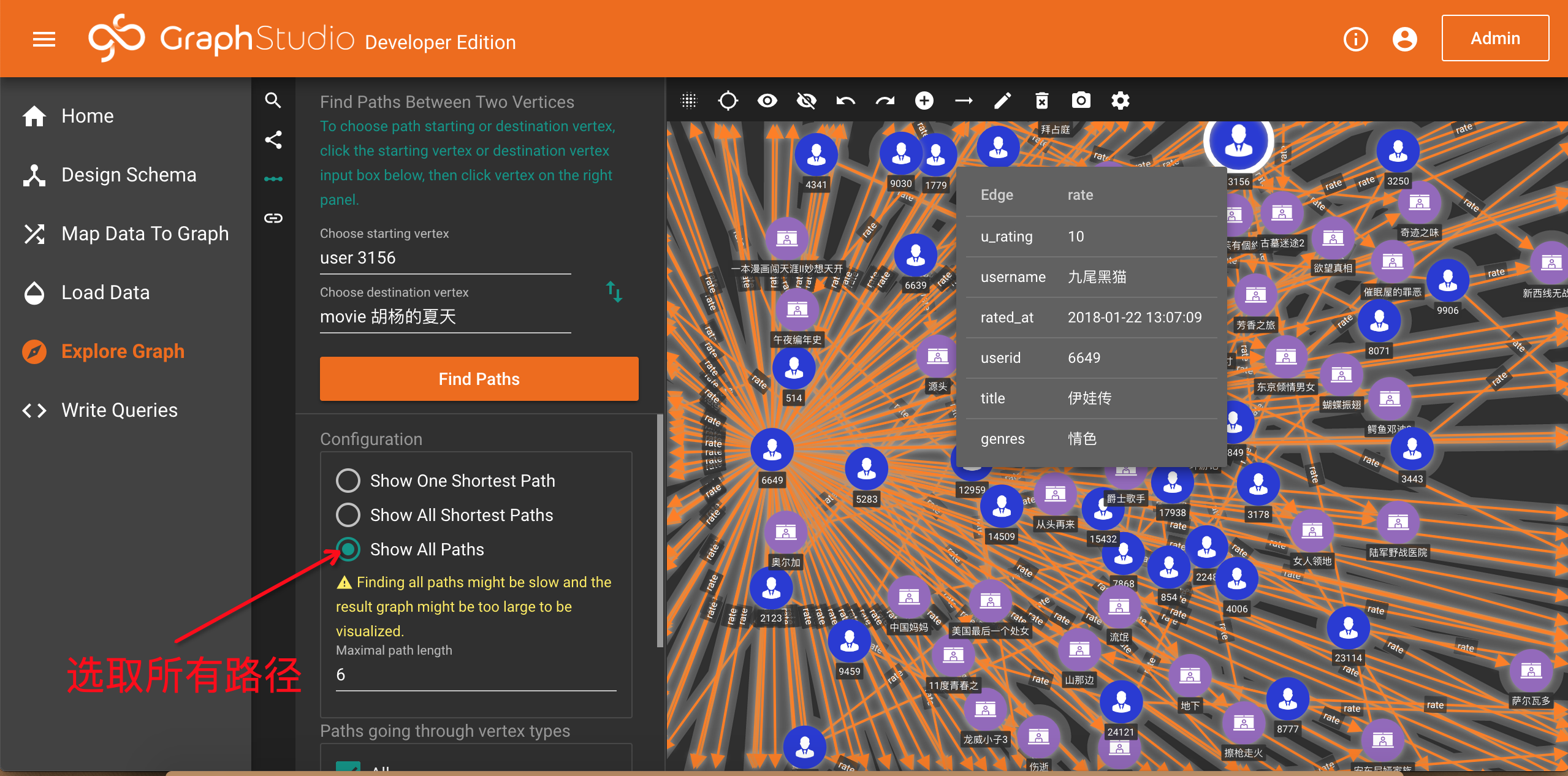
在配置选项里,你有三种路径可以选择,默认是选择一条最短路径,TigerGraph瞬间找到了两点之间的一条最短路径。你也可以选取所有路径,在数据集比较大的时候,请谨慎选择:
4.Find connections
你可以同时选取多个节点,然后点击查找它们之间的相互联系
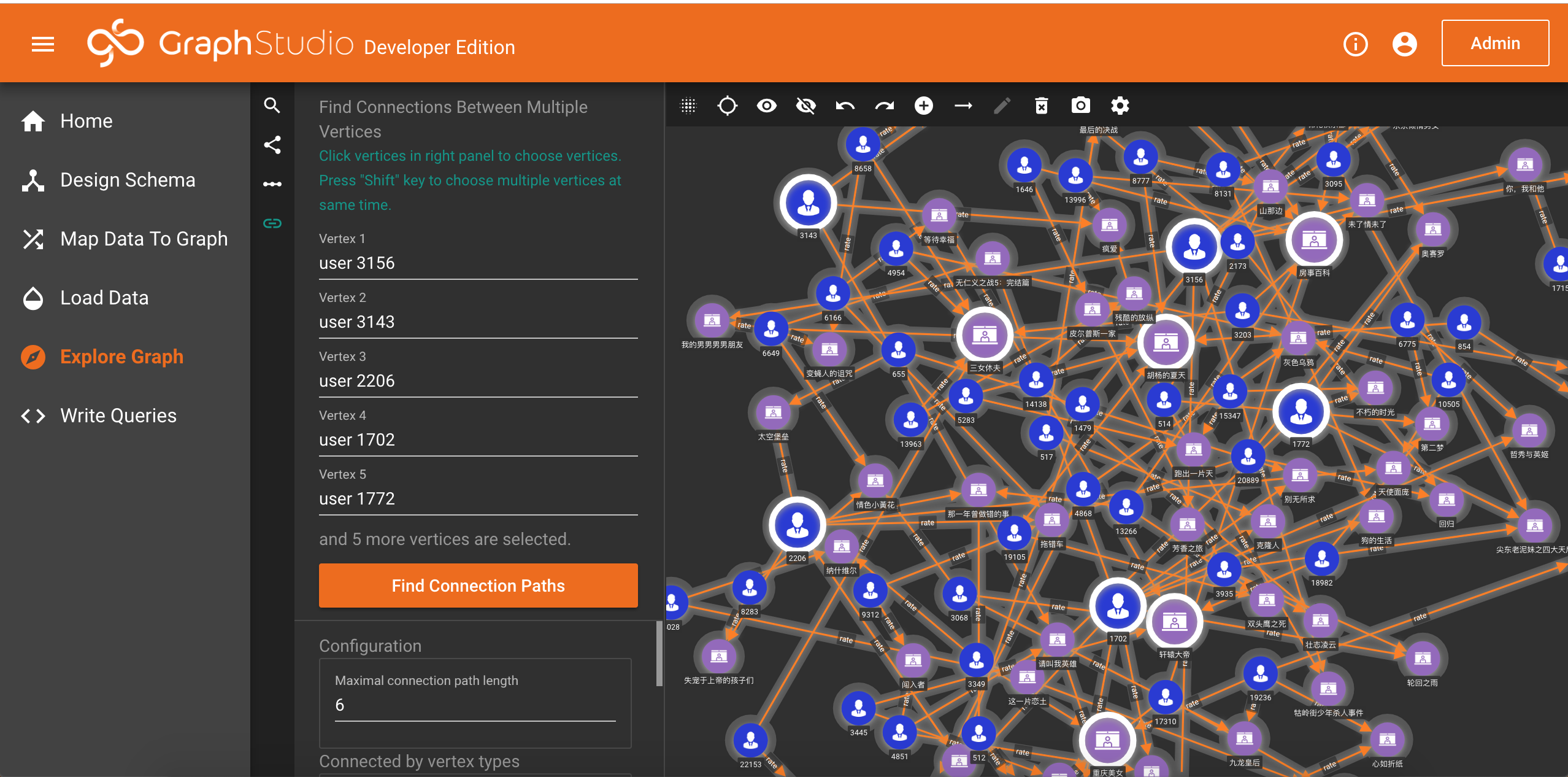
这里先不扩展详述原理部分,主要解释的功能是浏览数据,随着理解的深入,你可以调整相关的配置,以达到预期的效果
好了,现在你已经了解了图模型以及其和豆瓣电影数据集之间的映射关系,并且通过浏览图数据直观的感受了user节点和movie节点是如何通过rate边互相连接的。
运行查询
我们系统已经根据数据集内容,为你安装了一个查询,实现了电影推荐的功能
你可以点击左侧导航栏的Write Queries项进入编写查询页面:
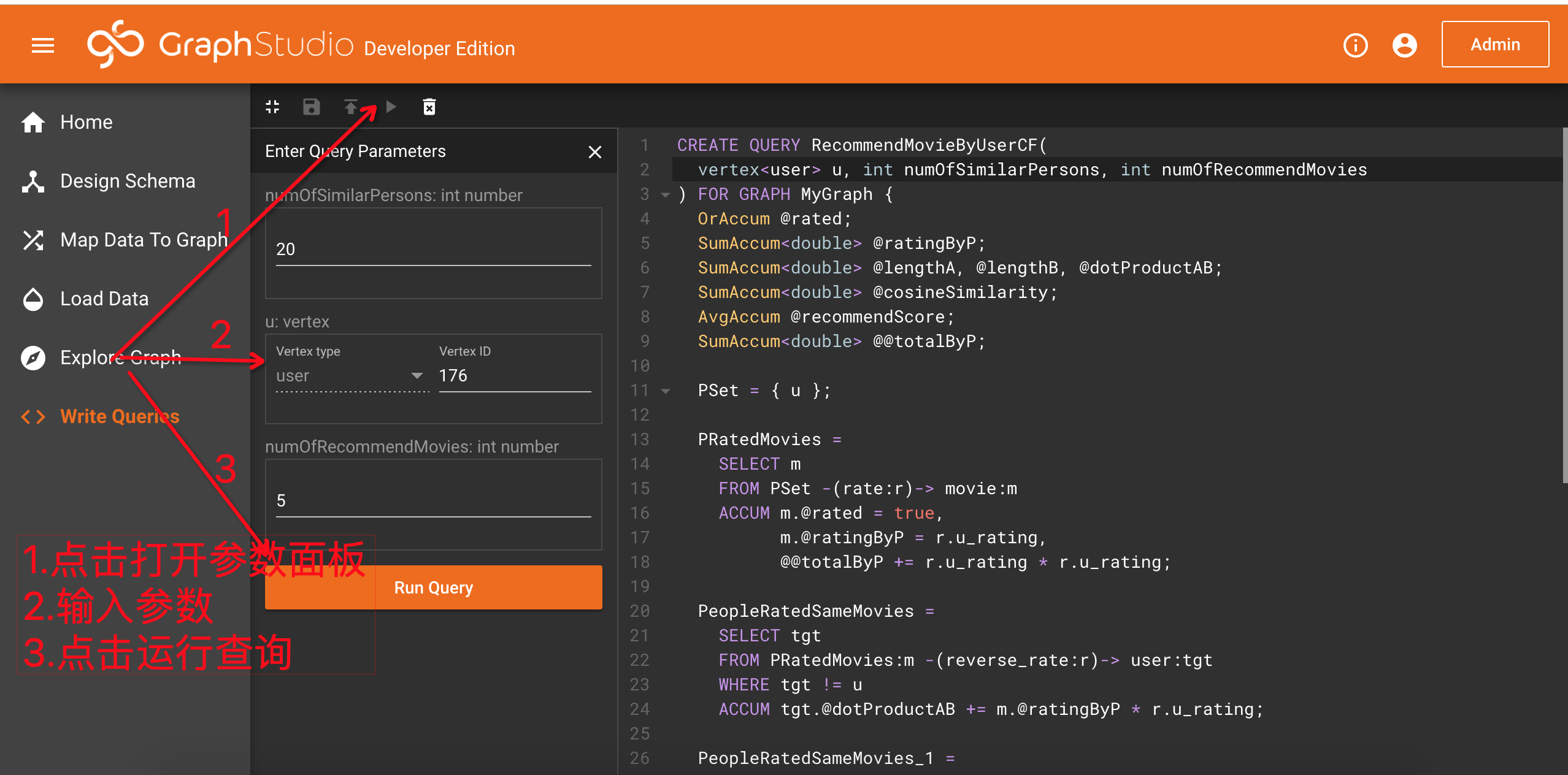
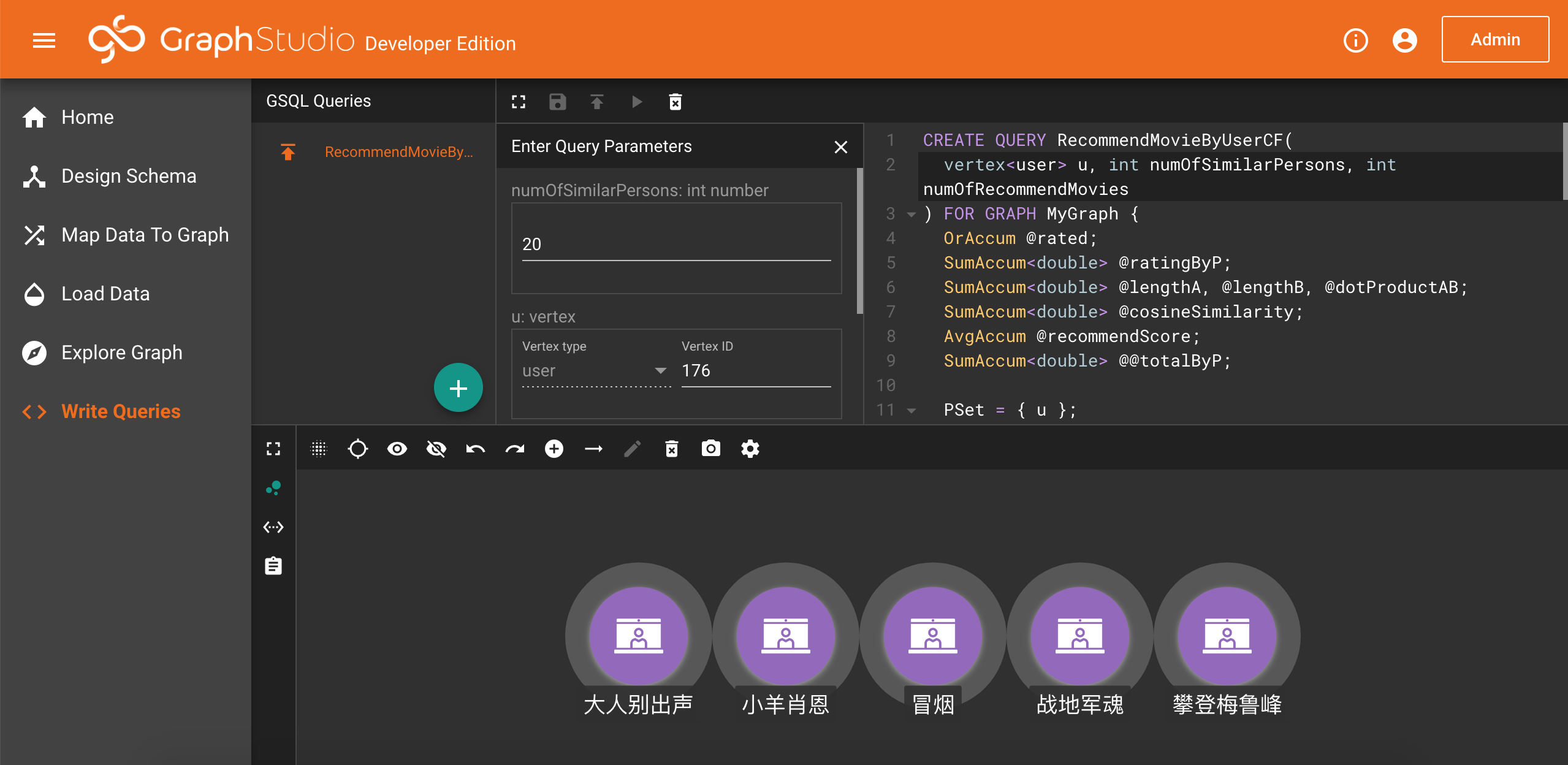
你可以看到上面已经有一个RecommendMovieByUserCF的查询了,选择该查询,然后点击工具栏上的运行查询按钮,由于这个查询需要输入参数,参数面板会弹出。输入一个人的id(比如176),给定numOfSimilarPersons(比如20)和numOfRecommendMovies(比如5),然后点击参数面板下方的运行查询按钮,很快结果面板中显示了推荐的电影,默认显示格式也可以进行修改:
你可以点击结果面板左侧的显示JSON项,可以查看JSON格式的查询返回结果:

总结
本文介绍了如何简单地使用TigerGraph,体验图数据库的魅力。通过联系售前申请账户查看技术方案,以及预约构架师交流。
留言
评论
暂时还没有一条评论.