使用BDOS打造产品推荐系统
什么是智能产品推荐
从广泛意义上来说产品推荐基本上是一种过滤系统,它的主要目的在于预测和显示用户想要购买的商品。 产品推荐的结果有可能不是100%的准确,不过从统计学的角度来讲,在一定概率内它能够像一定数量级用户推荐的商品正好是他们想要购买的,那么这就能带来不菲的商业价值。
什么是推荐系统
推荐系统近年来变得越来越流行,并且被广泛用于各种领域,其中包括电影,音乐,新闻,书籍,论文研究,搜索查询以及社交标签。 这一些领域主要存在于TMT行业(电信、媒体和科技),并大力运用在数字与电子化的细分市场之中。其中最为我们所熟知的例子就是电子商务网站,如,亚马逊,阿里巴巴等,都使用其专有的推荐算法,以便更好地为客户提供他们喜欢的产品。
如果设置和配置正确,推荐系统可以显着提高收入,点击率,转化次数和其他重要指标。此外,也可以对用户体验产生积极影响,其中最重要的指标就是: 客户满意度和保留率。
推荐系统主要依赖推荐引擎来实现核心功能。推荐引擎基本上是一种数据过滤的工具,这种工具利用算法和数据向特定用户推荐最相关的信息。这个模式其实可以抽象成我们最熟悉的线下导购模式: 当你进入一家店面之后,会有一个导购员一直盯着你,观察你的选购路径,然后伺机上前跟你介绍某一款产品,而且还会推荐给你可以挑选的其他的相关商品。当然不同店铺的导购员在交叉销售和追加销售方面的训练层次不一样,同样的,推荐引擎的高下之分也是各大推荐系统角逐胜败的关键因素之一。
亚马逊的例子
亚马逊(Amazon)在电子邮件活动和大多数网站页面中都将推荐系统作为主要的营销工具。 亚马逊根据用户浏览的内容来推荐不同类别的产品,并将可能购买的产品组合展示出来引诱用户来购买。 这里使用的推荐系统只有一个主要目标:通过分析用户存放在在购物车中的商品或他们当前正在浏览的商品来推荐更多产品组合来来增加平均订单价值,从而优化向上销售和交叉销售这两种销售手段,而且不仅仅如此,随后,系统还会进一步使用引擎的建议发送电子邮件或者其他推送信息,让用户了解产品的当前趋势,从而刺激更多的消费行为。
不同类型的推荐引擎
在推荐算法中比较流行的有三种:
- 协同过滤(Collaborative filtering)
利用兴趣相投、拥有共同经验的群体喜好来推荐用户感兴趣的商品 基于内容的过滤(Content-based filtering)
根据商品和用户的特性,发掘其中的相关性,然后基于用户过往的喜好记录推荐给用户相似的商品混合推荐系统(Hybrid Recommendation systems)
混合方法可以分别进行基于内容和基于协作的预测然后将它们组合来实现
协同过滤
协同过滤, 通常基于收集和分析有关用户行为,活动或偏好的信息,并根据与其他用户的相似性预测他们想要的内容。它的关键优势是不用去理解内容本身而去推荐内容。
协作过滤基于这样的假设:过去同意的人将来会同意,并且他们会喜欢过去喜欢的类似项目。例如,如果mike喜欢项目A、B、C,另一个人tom喜欢B、C、D,那么他们有相似的兴趣,所以mike应该喜欢项目D,而tom应该喜欢项目A。
除此之外,有几种类型的协同过滤算法:
基于”用户 – 用户”的协作过滤:这种算法尝试搜索相似的客户,并根据他们的特点选择提供商品。该算法非常有效,但这种类型需要计算和比对每个客户的信息,需要大量的时间和资源。
基于”商品”的协同过滤:这种算法尝试查找商品之间的相似特征,而不是找到客户特征。一旦我们有类似商品的矩阵,我们就可以轻松地向从商店购买的客户推荐类似的商品。该算法比”用户 – 用户”的协作过滤需要的资源少得多。
以下是一个两种算法的示意图
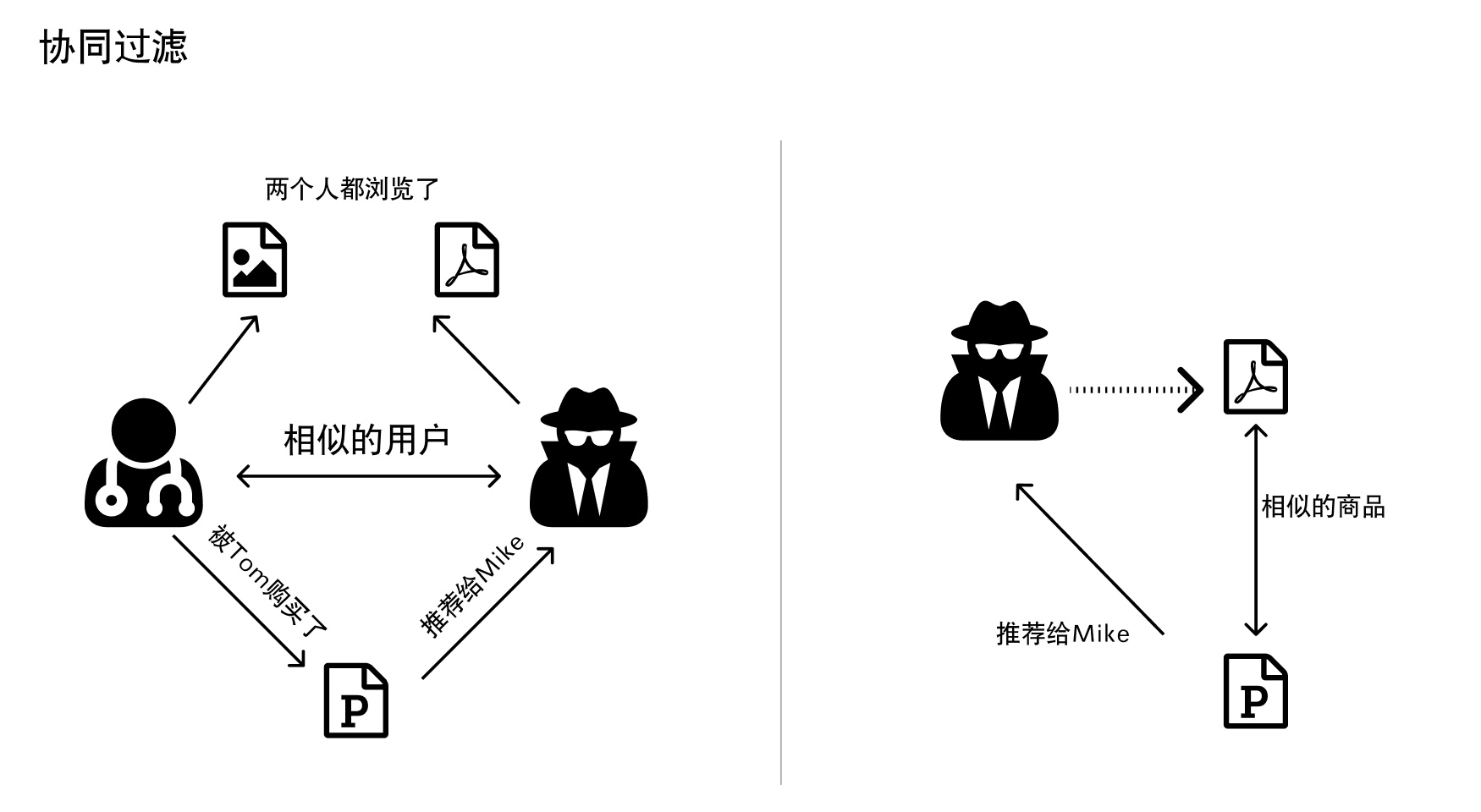
基于内容的过滤:
这种过滤方法基于对商品的描述和用户喜好作为基础(通常做法是进入系统之前会让用户去选择一些喜欢的领域)。这种算法推荐与用户过去喜欢品类相似的产品。基于内容的过滤的想法是,如果你喜欢一个项目,你也会喜欢一个“相似”的项目。这种方法的根源在于信息检索和信息过滤研究。
基于内容的过滤的一个主要问题是系统是否能够从用户的操作中学习偏好,并在其他不同的内容类型中复制场景。
基于内容的过滤在下面几个场景有比较好的优势:
- 过滤结果需要强相关性的: 基于内容的推荐系统,由于基于的是商品和用户的”元数据”,所以推荐出来的结果和用户的喜爱是强绑定的,比如: 消息订阅推送的系统
- 推荐过程需要被透明化: 与协同过滤的”黑盒子”的推荐流程相比,如果企业的推荐场景设计是需要对用户透明公开的,那么基于内容的过滤会是优先的选择
- 新商品可以被马上推荐: 基于内容的过滤,当新商品上架的时候可以跨过”需要用户输入一些交互”的冷启动过程,可以马上基于已有的模型推荐给用户
混合推荐系统:
事实上在实践当中,结合上述两种方法可能更有效果。混合方法可以分别进行基于内容和基于协作的预测然后将它们组合来实现。此外,通过向基于协作的方法添加基于内容的功能,反之亦然; 或者将方法统一到一个模型中,都是非常有效的手段。
承载推荐系统的平台
可以看出,事实上并没有一个通吃的算法,或者模型来帮助一个企业达到一招鲜,吃遍天的效果,企业需要不停的捕获用户数据,分析数据,调整算法参数,以及选择算法组合来达到最佳的推荐效果,并且已经完成的算法模型还需要根据市场变化来不断的调整,才能持续的产生商业价值,而且用户和商品的数据都是海量的,很多时候还需要实时处理数据来捕获转瞬即逝的市场机会,而这一些都需要一个标准化的大数据平台,和算法平台的支撑,并且需要一个统一的应用云平台来随时更新发布这一些智能应用。
因此我们推荐使用智领云自主研发的BDOS大数据操作系统,一款适合各种企业规模的先进的大数据、算法、应用云平台。
BDOS秉承”让大数据变得简单”的理念,帮助企业用户,完成机器学习/人工智能应用场景下的95%的准备工作,让用户无需操心,机器学习/人工智能应用所需要的:
- 配置管理
- 监控
- 资源管理
- 服务基本架构
- 分析工具
- 数据清洗
- 数据采集
- 特征提取
- 程序管理
而将全部的资源和精力集中在对算法的调优,以及捕捉市场机会上面。
使用BDOS打造产品推荐系统 – Demo示例 课程推荐系统
老用户可以直接登录BDOS Online,在首页应用展示当中轮播图中,可以点选”课程推荐系统的demo示例演示”。
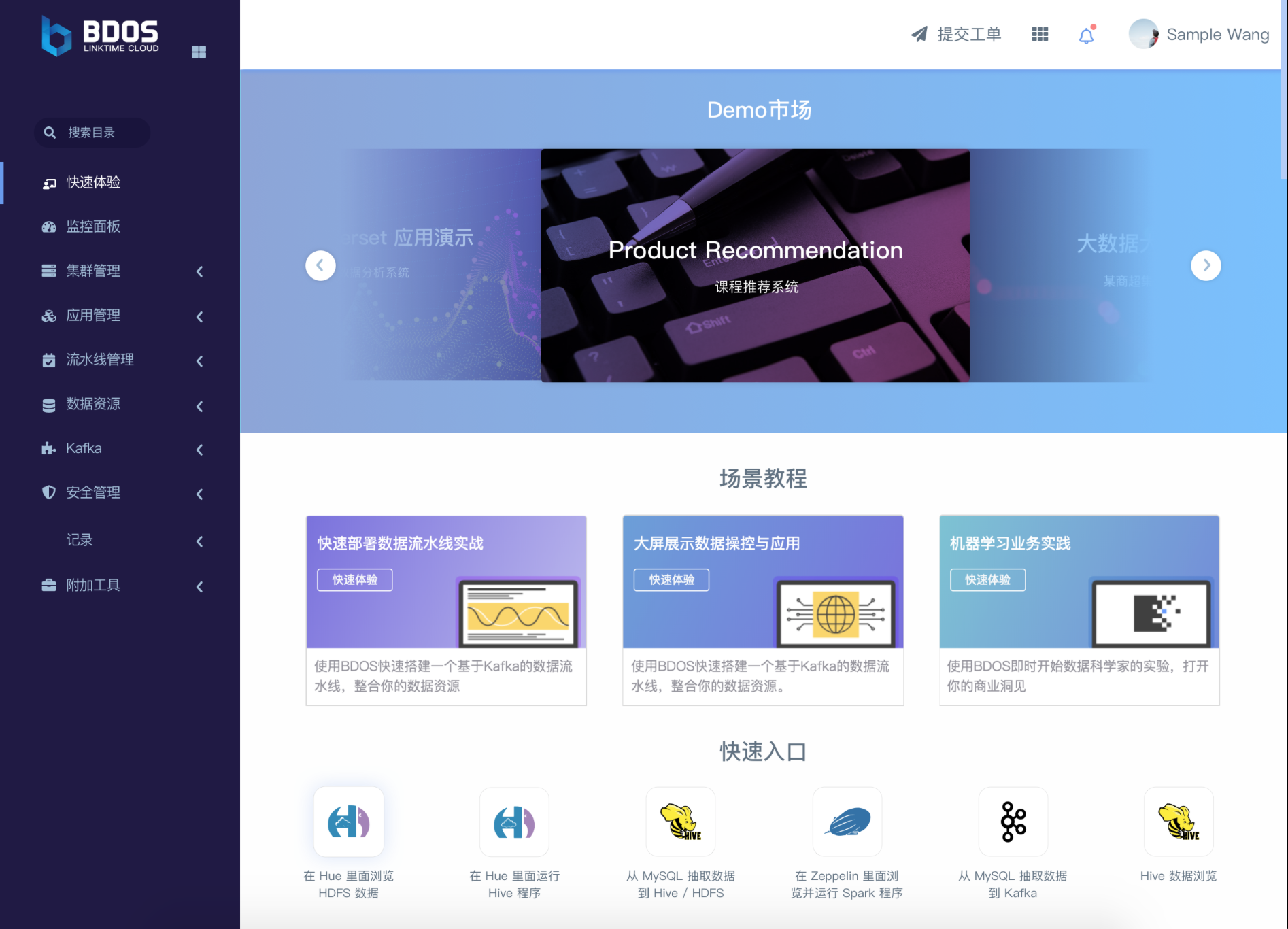
Demo 简介
用户可以使用三种不同的算法模型分别获得适当的课程推荐结果; 并且通过算法分析图能够知道不同算法如何生成结果; 而且通过使用过滤器来准确得到结果;
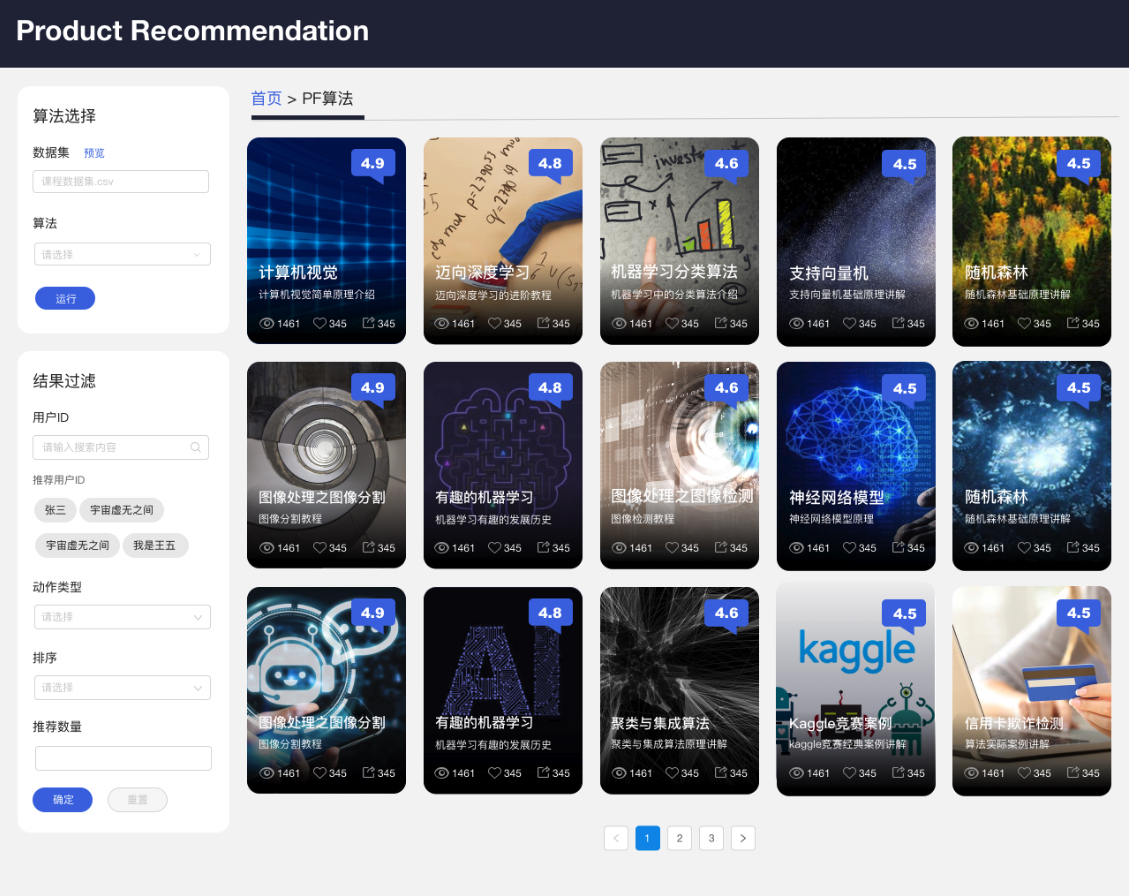
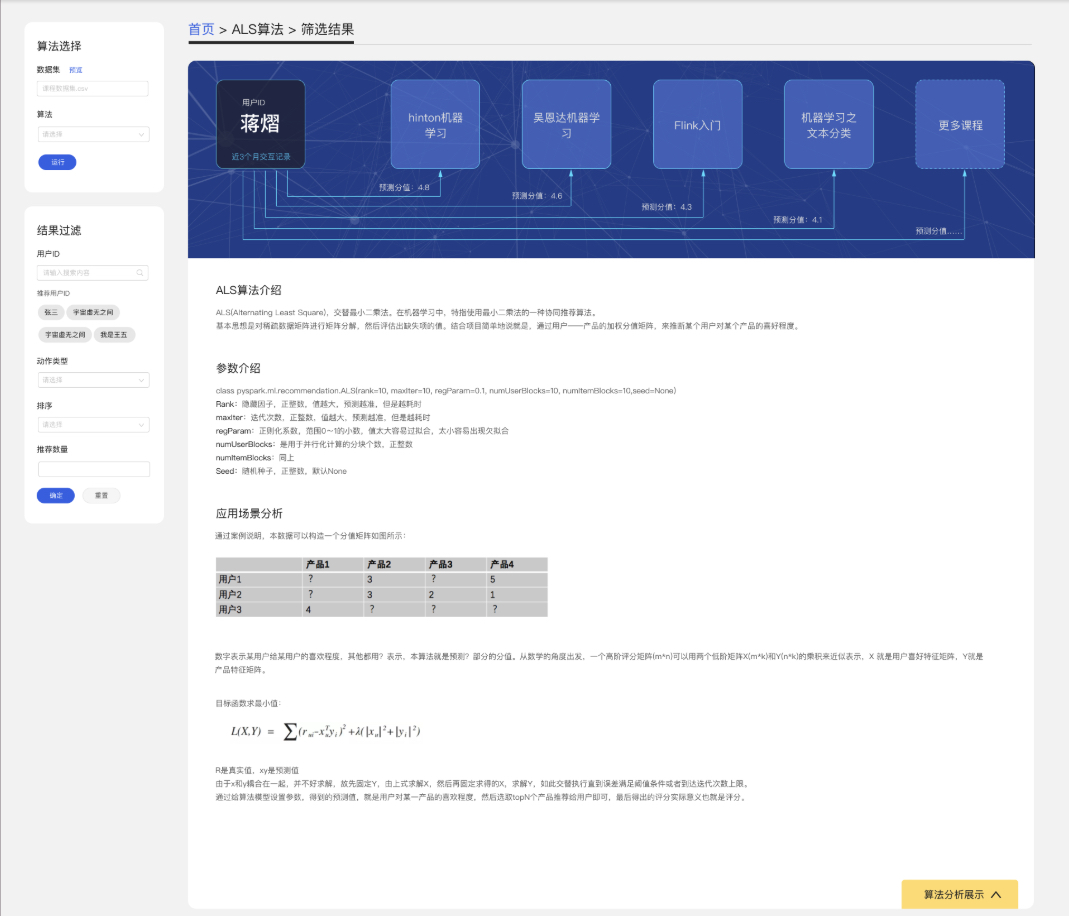
本demo示例的主要目的是来展示,在BDOS平台发布一个产品推荐系统的便捷性,以及可操控性,从示例可以看出,企业用户可以随意的安装/更换/调整自己所需的算法模型,并且能够款速的迭代更新发布;并且BDOS提供数据科学家专用平台,能让他们在一个独立的环境中大量实验和比对不同算法的区别,等确定好算法效果之后,一键部署到生产品台。
示例当中采取的算法简介
1- FP-Growth算法介绍
通过为算法模型设置满足需要的最小支持度和最小置信度之后,从中找出为用户关联的产品,按照置信度排序取TopN个即可,最后的分值实际意义是置信度。
(参数展示)
minSupport:最小支持度,范围在0~1之间,筛选找出的项集的支持度都是在minSupport之上的。
minConfidence:最小置信度,范围在0~1之间,筛选出的预测项的置信度都是在minConfidence之上的。
itemsCol:设置输入数据的列名,字符串。
predictionCol:设置预测数据的列名,字符串。
numPartitions:并行计算分区个数,正整数,可以进行并行FP算法的计算。
2-KMEANS算法介绍
K-MEANS算法通过设定类的个数k,将数据集分成k个不同的簇,保证同一个簇中相似度较高,不同簇间相似度较低。
(参数展示)
K:设置聚类个数
maxIter:迭代次数,正整数,值越大,预测越准,但是越耗时
Seed:随机种子
3-ALS算法介绍
ALS(Alternating Least Square),交替最小二乘法。在机器学习中,特指使用最小二乘法的一种协同推荐算法。基本思想是对稀疏数据矩阵进行矩阵分解,然后评估出缺失项的值。结合项目简单地说就是,通过”用户—产品”的加权分值矩阵,来推断某个用户对某个产品的喜好程度。
(参数展示)
Rank:隐藏因子,正整数,值越大,预测越准,但是越耗时
maxIter:迭代次数,正整数,值越大,预测越准,但是越耗时
regParam:正则化系数,范围0~1的小数,值太大容易过拟合,太小容易出现欠拟合
numUserBlocks:是用于并行化计算的分块个数,正整数
numItemBlocks:同上
Seed:随机种子,正整数,默认None
联系我们
通过联系售前可以申请高级账户查看更多技术方案,以及预约构架师交流。
留言
评论
Chalin 说 · 2019-01-18 回复
学习了。有机会体验下。
Chalin 说 · 2019-01-18 回复
学习了。有机会体验下。
superman 说 · 2018-12-29 回复
前排