基于BDOS发布的人脸识别器
人工智能的商业价值
近年来大数据持续在互联网、智能政务、金融、医疗健康、教育、娱乐生活、智能制造等等各个领域不断创造出价值,然而随着大数据的技术升级以及支撑平台趋向标准化,大数据在创新领域的价值已经逐渐形成一个新的商业模式。
在创新领域当中,大数据支撑的人工智能产业落地是一个炙手可热的方向,人工智能是一个新的、全方位的技术突破的领域,它最大的价值在于帮助已有的行业进行业务升级和转型。
人工智能和大数据依然是时下最火热的两个名词,事实上不管是从计算机行业、新兴行业或者是传统行业来说,数据的采集、存储、分级以及利用,他们之间其实是天然地要形成持续、正向反馈、关系紧密的闭环的。
所以说任何企业(传统的和新兴的)都希望去往智能企业的方向去发展,对大数据的需求是非常强烈的,因为企业在进行AI技术研发的时候,对于数据的累计、管理、更新、依赖是刚需。
大数据作为信息载体的一种新的聚合形式,本质上是包罗万象的,其中基于图像这种数据形式提供的解决方案,能够蕴含更大的信息量,也能提供更多的价值,但是背后需要的技术支持也更大。
今天我们带来以人脸识别作为人工智能当中的分支场景来解释基于图像数据的应用在BDOS上的应用以及相关的示例。
人脸检测,人脸识别和人脸检索的区别
为什么说人脸识别是人工智能当中的一个分支场景?首先我们要区分几个基础的概念,什么是人脸检测,人脸识别和人脸检索。
人脸检测是根据肤色等特征定位人脸区域;而人脸识别是识别出这个人到底是谁,人脸识别是具有一定的固定过程的,需要首先在图像中检测出人脸的区域(人脸检测),然后再使用人脸识别的算法,识别出图像中的人到底是谁,这个是一个完整的过程。
而人脸检索是指给定一个或多个包含人脸的输入图像,从图像库或者视屏库中检索包含所输入图像中的人脸的那些图像。
人脸识别是有监督学习的过程,需要使用一定数量有标签的图像训练分类模型。
人脸识别和深度学习
上述当中的监督以及对应的非监督学习过程,都是属于机器学习范畴的一般方法。要了解人脸识别和深度学习的关系,我们有必要先了解一下人工智能、机器学习以及深度学习三者的关系。
事实上,这三者是一个包含的关系,简单来说人工智能>机器学习>深度学习,就如之前所描述的一样,人工智能是一个新的,全方位的技术领域,其中机器学习主要努力的方向是人工智能当中的分类、回归以及关联性分析,然后深度学习则是对机器学习当中神经网络的一个纵深的拓展,而人脸识别的技术的突破是和大数据、机器学习以及深度学习的综合性的一个结果。
较为著名的机器学习算法总共有10个: 决策树、支持向量机SVM、随机森林、逻辑回归、朴素贝叶斯、KNN算法、K-means算法、Adaboost算法、Apriori算法、PageRank算法。其中支持向量机SVM是这次demo示例中会使用的机器学习算法之一。
然而深度学习的基础在当下基本上可以用神经网络、深度神经网络、神经网络框架几个名词来概述一下,比较流行的神经网络主要有: 人工神经网络(ANN), 卷积神经网络(CNN),以及循环神经网络(RNN)。其中卷积神经网络(CNN)是这次demo示例会使用的深层神经网络。
在深度学习出现之前,使用机器学习方法的数据科学家和工程师们往往需要大量的时间去对数据进行收集、筛选、和尝试用不同的方法去提取特征然后用不同的组合方式对数据进行分类和预测,然而深度学习的爆发解放了数据科学家和工程师在这个方面的时间和精力的花费,以下是机器学习的一般方法,和深度学习的一般方法的对比:
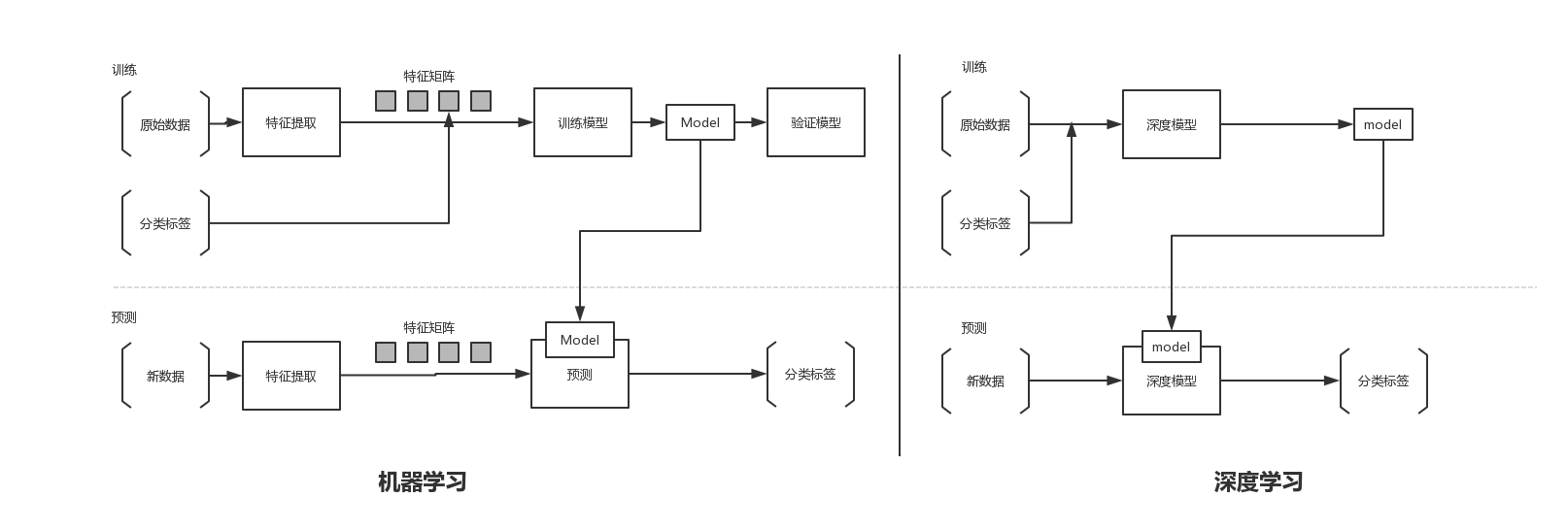
全球现在每天产生的图像和视频的数据量大的惊人,对于企业来说每天都在为这些资源的存储、标注耗费着大量的精力,如果拥有一个能够良好支撑深度学习框架的平台,为神经网络源源不断的提供数据以及稳定的运行资源,企业会以成倍的效率生产价值,以节约数倍的人力和时间成本去展开数据分析和数据挖掘,在商业领域赢得先机。
人脸识别和数据集的关系
人脸识别的算法发展是建立在大量的人脸数据集和对应的人脸数据集关系密不可分,算法需要在大量的人脸数据集上验证、测试,比较典型和常用的数据集有如 LFW、FDBB、Wanwan1、Wanwa2等使用比较多的 ,以及其他很多服务于特定算法、或者神经网络的数据集。
这里我们简单介绍一下大名鼎鼎的LFW数据集,如果对基于这个数据集制作的开源人脸识别项目感兴趣,可以参考技术博客在本机与Docker容器中运行Facenet训练人脸识别器,按照教程亲自操作一遍。
LFW(Labeled Faces in the Wild)数据集是由美国马萨诸塞大学阿姆特分校收集管理并维护的,是为了在不受限制的环境下研究人脸识别问题而设计的,该数据集有13233张图片,每一张的尺寸都是250*250像素的,每张图片都以图像中人物的名字命名,不同的人物放入不同的文件夹,现在里面有5700多个文件夹,即有5700多个人物,LFW可以用于人脸检测、人脸识别和人脸检索。
人脸识别的发展是一个漫长的过程,虽然现在人脸识别的算法在LFW等公开的数据集上面取得了超过96%的甚至更高的准确率,但是和真实环境当中复杂的应用场景相比还是有一段距离,有许多相关的因素需要去考虑,如:
- 表情
- 年龄变化
- 光线变化
- 不同姿态
- 不同图像分辨率
由于LFW里面多是国外的人物图像,为了增加示例趣味性以及综合性难度,在本示例制作的人脸识别器基于开源项目Facenet开发然后做了如下的优化。其主要分为两部分:1.训练基于CASIA-WebFace数据集训练的“inception-resnet-v1”神经网络,用于提取人脸的特征向量。 2.训练基于自建训练集训练的“支持向量机SVM”分类器,用于实现人脸识别任务。
人脸识别器的使用
基于BDOS发布的人脸识别器,最大限度的降低了用户对人脸识别中使用的算法和神经网络的理解难度,将人脸识别的乐趣释放出来,用户可以上传自己的照片,或者是熟悉的人的照片来识别出与之最相似的4个明星脸,同时人脸识别器支持用户在识别的过程中上传自己的照片开始新一论的人脸集的训练,动态更新人脸集,保证人脸识别器的动态更新以及趣味性,越多人用,越多次用,越有趣。
下面是每次Top4的取值逻辑:
Facenet的人脸识别训练过程主要分为两步
1.使用预训练模型(Facenet已训练好的神经网络模型),提取人脸图片的特征向量。此步之后,所有的人脸图片实际上是用一个向量来表示了。
2.拿到了需要训练的人脸图片的向量表示之后。我们使用这些向量来训练一个分类器。这个分类器我们使用线性“支持向量机SVM”算法。
在训练完成之后,我们会得到一个被训练完成的“支持向量机”模型。
识别过程
我们使用这个被训练好的分类器(“支持向量机”SVM模型)来对用户提供的图片进行分类。其过程也是分为两步:
1.使用预训练模型提取此人脸图片的特征向量
2.使用上一步得到的特征向量作为输入,分类器会在这个特征向量的基础上进行矩阵运算。输出的是一个标签和它对应的可能性(probability)。
取值逻辑
训练这个分类器的过程实际上是利用训练集不断的更新分类器里面参数的过程(这些参数可以理解为Y=W1X1 + W2X2 + … + WnXn + …)中的W1,W2等等。
在训练训练完成之后,这个参数也就确定了。最后的取值,实际上是利用这些参数和用户提供照片的特征向量做一个矩阵运算,得到标签和对应的可能性。
为什么相同的人的相似度不能达到100%
识别过程只是我们训练好的分类器对于提供图片的特征向量的一个矩阵运算。而不是将提供的图片和训练集里图片进行比较。实际上,一旦训练完成,训练集就不会再被用到。 认为会得到100%的想法,实际上是觉得识别过程是将用户提供的图片和训练集进行比较,然而实际上不是这样的。
同样,通俗意义上理解的100%,其实和人脸识别的算法逻辑存在一定的偏差,实时上通过算法识别的照片会有一个possibility的值,值最高的那一个如果是正确的那么这一次的识别就算是成功(不论possibility的值的大小是多少),然后这个过程运行100次,如果其中97次都正确了,那么这个算法的accuracy就是97%.
大数据和大数据平台的支持
人脸识别当中的步骤都需要大量的训练数据。好消息是现实生活中的确有很多数据。坏消息是它们要么是未分类要么是未注释。本示例恰好验证了机器学习专家们所说的,机器学习项目中大部分时间将用来准备训练数据而不是训练模型本身。
对于图像分类分类问题,需要将数大量的图像排列成不同的类。这是一项繁琐的工作。标记数据这个任务真的很单调,很无聊,但是很必要。
而且根据David Talby的描述: “如果没有源源不断的新数据,模型质量会迅速降低。这是著名的概念漂移(concept shift),这意味着,随着时间的推移,静态机器学习模型提供的预测变得不那么准确,并且不太有用。在某些情况下,甚至可能在几天内发生。”
因此,必须不断改进模型,并且永远得不到一个一劳永逸的模型。其实还挺有趣的。然而,这一切如果没有标准、统一的数据平台的支撑,很难有大的成效。
现在基于BDOS发布的人脸识别器示例应用已经可以在BDOS Online上面使用了,老用户可以直接登录BDOS Online,在首页应用展示当中轮播图中,可以点选”课程推荐系统的demo示例演示”。
联系我们
通过联系售前可以申请高级账户查看更多技术方案,以及预约构架师交流。
留言
评论
暂时还没有一条评论.