硅谷速递 | 硅谷2020最新大数据学习路线:科学使用这一招,12周助你成为数据分析师

原文作者:Cassie Kozyrkov、Freddie Odukomaiya、Monika Sharma
【硅谷速递】每周一为大家速递美国硅谷最精彩的科技文章和学习资料,简约不简单是本栏目的最大特点,3篇短小精悍的文章,助你每周快速精准Get一项最新技术点!把握技术风向标,了解行业应用与实践,就交给“硅谷速递”吧~
速递先知
本期三篇超实用文章,帮助大家玩转大数据:
- 数据科学到底是什么?
- 想要在12周内成为数据科学家吗?成为数据分析师可能是一个不错的目标
- 3个必须了解的数据科学面试问题
数据科学到底是什么?
数据科学是一门将数据变得有用的学科,它包含三个重要概念:统计、机器学习、数据挖掘/分析。《数据科学杂志》曾提出:“所谓的‘数据科学’,指的是那些任何与数据相关的内容”。对此,我表示赞同,现在一切都无法与数据分割。之后,对数据科学的定义便层出不穷,例如Conway的维恩图,以及Mason和Wiggins的经典观点。
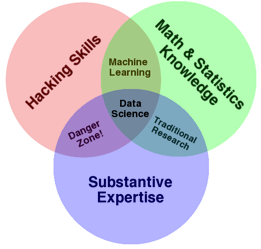
那么,我们究竟如何能够让数据变得更有用呢?可以通过以下几个步骤来实现:
数据挖掘:如果不知道你要作何决定,最好的办法就是去寻找灵感。这就是所谓的数据挖掘、数据分析、描述性分析、探索性数据分析或知识发现。
数据挖掘的黄金法则是:只对你能看到的做出结论,而不对你看不到的做出结论,因为你需要统计数据和更多的专业知识。数据挖掘的专业知识是通过检查数据的速度来判断的,只需学会操作设备及R语言的教程、Python语言的教程等等。当你开始玩得开心时,你可以称自己为数据分析师,当你能够以闪电般的速度曝光照片以及所有其他类型的数据集时,你就可以称为专家分析师。
统计推断:灵感很容易获取,但严谨却很难做到,如果你想掌握数据,则需要专业课程的学习。想要做好它需要花费不少的时间,如果打算做出高质量且风险可控的决策,由于决策不仅仅依赖所得到的数据,此时则需要在分析团队中加入统计技能,因为在情况不确定的时候,或许统计学能够改变你的想法。
机器学习:机器学习从本质上来讲,是使用示例而非指令来实现操作的,大家可以看一些关于机器学习的文章,包括机器学习与人工智能有何不同、如何入门机器学习、企业运用机器学习的经验教训以及向孩子介绍监督学习等。
数据工程:数据工程指的是将数据传递给数据科学团队的工作。它本身就是一个复杂的领域,通常而言,它更接近于软件工程,而不是统计学。获取数据之前的大部分技术工作都可以被称为“数据工程”,而获取到数据后所做的一切都是“数据科学”。
决策智能:决策智能是关于决策的,包括基于数据的大规模决策,这使得它变成了一门工程学科。利用社会和管理学科,增强数据科学的应用。决策只能是社会和管理学科的组成部分。换句话说,它是这些数据科学的超集,不涉及为通用用途创建基本方法之类的研究工作。
想要在12周内成为数据科学家吗?成为数据分析师可能是一个不错的目标。
许多广告声称可以在12周内使您成为数据科学家,并教您Python编程,Pandas,Matplotlib等python库和scikit-learn,Tableau,SQL等其他可视化工具。12周后,您将获得一份可赚取约100,000美元的工作。这现实吗?取决于您所处的级别。如果已经知道一种编程语言并转而使用Python从事新的职业,那么如果努力工作是可以实现的。但如果没有任何编程背景,则很难。
合理的时间表:如果想成为数据科学家,则需要至少学习一种编程语言。学习编程语言并不意味着只学习if / else语句和循环,你应该花至少三个月的时间只学习一种语言。 如果不这样做而立即进入所有的学习库和数据库,那么极有可能最终会学无所成。
这些只是最低要求:你需要不断提高自己的编程技能,重要的一件事是统计,至少要学习一些初级的推理统计数据和模型拟合,并学习在Python或R中实现它们。另外,将数据挖掘视为一项重要技能,那里有很多数据,需要进行提取。如果您能花费一两年时间去学习这些技能,它将会为您的生活增添很多价值。
12周到18周的合理时间 :看起来很难在12周内成为一名数据科学家,不过成为数据分析师可能是一个不错的目标。
进一步提高Excel技能,了解一些高级技术,例如数据透视表,Visual Basic等;了解Tableau这样优质的数据可视化工具,学习SQL ,它比学习编程语言更容易,同时也是就业市场中的一项宝贵技能。
发展软技能 :以上三项技能加在一起可以助您轻松就业。但是我们过于专注于学习工具,却忘记花一些时间来开发软技能。没有一些实际的良好知识,将很难有效地使用这些工具。同时,请阅读文章、书籍或报纸以保持与时俱进。包括:参加研讨会听取经验丰富的人的讲话,参与Stack Overflow,Stack Exchange和Slack Channels社区,随时了解就业市场,最新技术并提高软技能。
结论:我的建议是,开始学习免费课程。 甚至根本不需要为学习编程语言付费, Coursera , edx , udacity有一些高质量的免费课程。
3个必须了解的数据科学面试问题

为了不让自己在同一个地方失败两次,也为了让自己对他人有用,以此文章献给那些想追随自己的激情,成为数据科学家的人。数据科学是一个需要不断提高技能的领域,同时每天都在发展机器学习算法的基本概念。
问题1:共线性会对模型有影响吗?
答案: 共线性是指两个或多个预测变量之间关系密切。下面的图2显示了共线变量的例子。变量2严格遵循变量1,Pearson相关系数为1。所以很明显,当这些变量被输入到机器学习模型中时,它们中的一个会表现得像噪音一样。
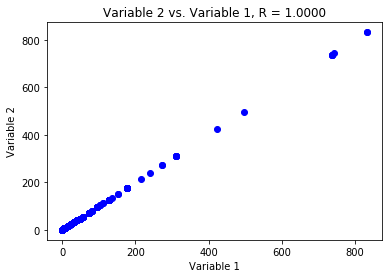
共线性变量的例子
共线性的存在在回归类型的问题中可能成为问题,因为很难分离出共线性变量对响应的个别影响。或者换句话说,共线性降低了回归系数估计值的准确性,导致误差增加。这将最终导致t统计量的下降,因此,在共线性存在的情况下,我们可能无法拒绝原假设。
检测共线性的一个简单方法是查看预测变量的相关矩阵。这个矩阵的一个元素的绝对值很大,表明了一对高度相关的变量,存在数据共线性的问题。不幸的是,并不是所有的共线性问题都可以通过检查相关矩阵来发现:即使没有一对变量具有特别高的相关性,三个或多个变量之间也可能存在共线性。这种情况称为多重共线性。对于这种情况,评估多重共线性的一个更好的方法是计算方差膨胀因子 (VIF),而不是检查相关矩阵。每个变量的VIF可以用公式计算:
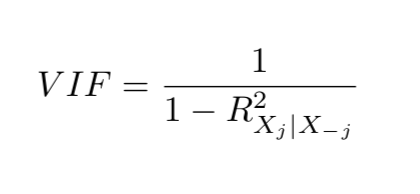
方差膨胀因子
其中r平方项是变量X对所有其他预测因子的回归。如果VIF接近或大于1,则存在共线性。当遇到共线性问题时,有两种可能的解决方案。一种是删除冗余变量。这可以在不影响回归拟合的情况下完成。第二种方法是将共线变量合并成单个预测器。
问题2:给外行解释深度神经网络
答案:神经网络(NN)的概念最初起源于人类大脑,其目的是识别模式。神经网络是一套通过机器感知、标记和聚类原始输入数据来解释感知数据的算法。任何类型的现实世界数据,无论是图像、文本、声音甚至时间序列数据,都必须转换成包含数字的向量空间。
深度神经网络中的深度是指神经网络由多层构成。这些层是由节点组成的,在节点上进行计算。人脑中的一个类似节点的神经元在遇到足够的刺激时就会被激活。节点将原始输入的数据与其系数或权值组合在一起,这些系数或权值根据权值减弱或放大输入。输入和权重的乘积在图3所示的求和节点上求和,然后将其传递给激活函数,激活函数决定该信号是否应该在网络中进一步扩展并影响最终结果。节点层是一排类似神经元的开关,当输入通过网络输入时,这些开关就会打开或关闭。
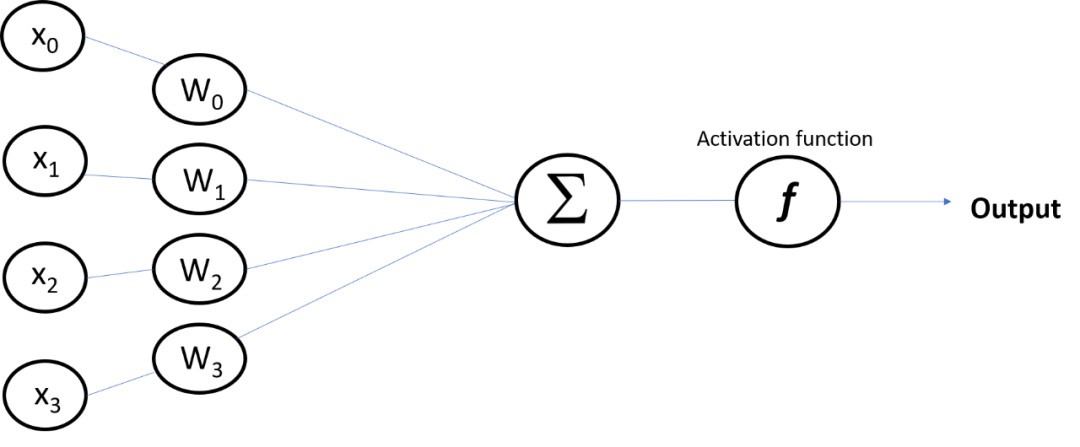
神经网络中节点的可视化
深度神经网络不同于早期的神经网络,如感知器,因为它们是浅层的,只是由输入层和输出层以及一个隐含层组成。
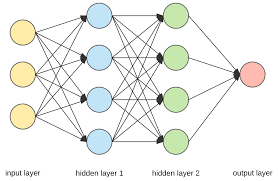
深度神经网络包含多个隐含层
问题3:3分钟简单阐述一个可以让你回去解决的数据科学的项目
答案:一个典型的数据科学面试过程始于具体的数据分析项目。我做过两次,取决于项目的复杂度。第一次,我有两天的时间来解决一个问题,使用机器学习。而第二次,我有两个星期的时间来解决一个问题。不需要指出的是,当我第二次处理类别不平衡的数据集时,这是一个更加困难的问题。因此,3分钟的推销式面试问题可以让你展示你对手头问题的把握。请务必从你对问题的解释开始,你解决问题的简单方法,你在你的方法中使用了什么类型的机器学习模型,以及为什么这样做?不要对模型准确性过多的吹嘘。
留言
评论
${{item['author_name']}} 回复 ${{idToContentMap[item.parent] !== undefined ? idToContentMap[item.parent]['author_name'] : ''}}说 · ${{item.date.slice(0, 10)}} 回复
暂时还没有一条评论.