基于云原生的大数据产品前端实践 | 第七期图文直播文字回放
2月5日晚,智领云第七次社群图文技术直播如约而至。本次直播由智领云Web开发经理陈磊为大家分享了《基于云原生的大数据产品前端实践》主题内容,其中主要内容包括:BDOS前端架构演进,前端工程体系建设,数据可视化实践,前端能力中台化探索等。
大数据系统BDOS的整体架构
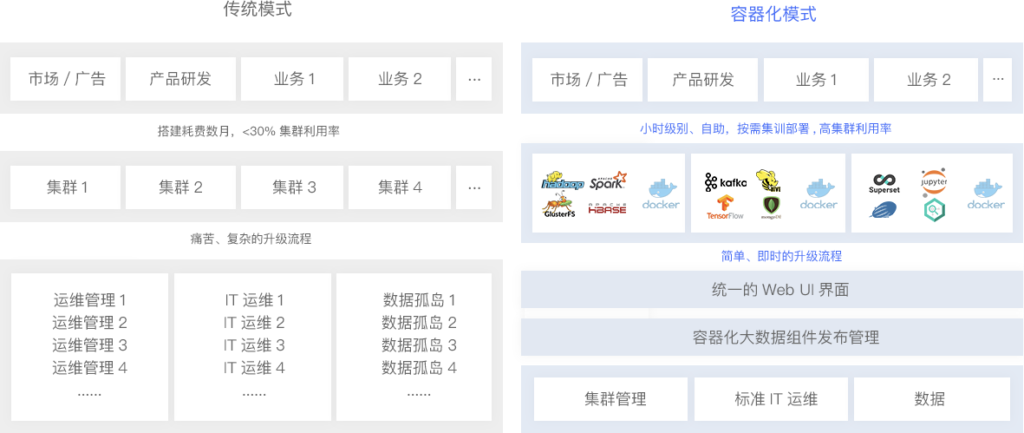
在了解基于云原生的大数据产品前端实践之前,先为大家介绍一下大数据系统BDOS的整体架构,BDOS 是基于云原生的容器化大数据平台,相对于传统模式,具有以下优越性:
- 提供安全、快速的大数据环境部署
- 统一、高效的管理及访问入口控制
- 轻松、灵活的多云环境支持AWS、阿里云、华为云、腾讯云等
- 可以提供一个稳定、弹性、可靠的环境
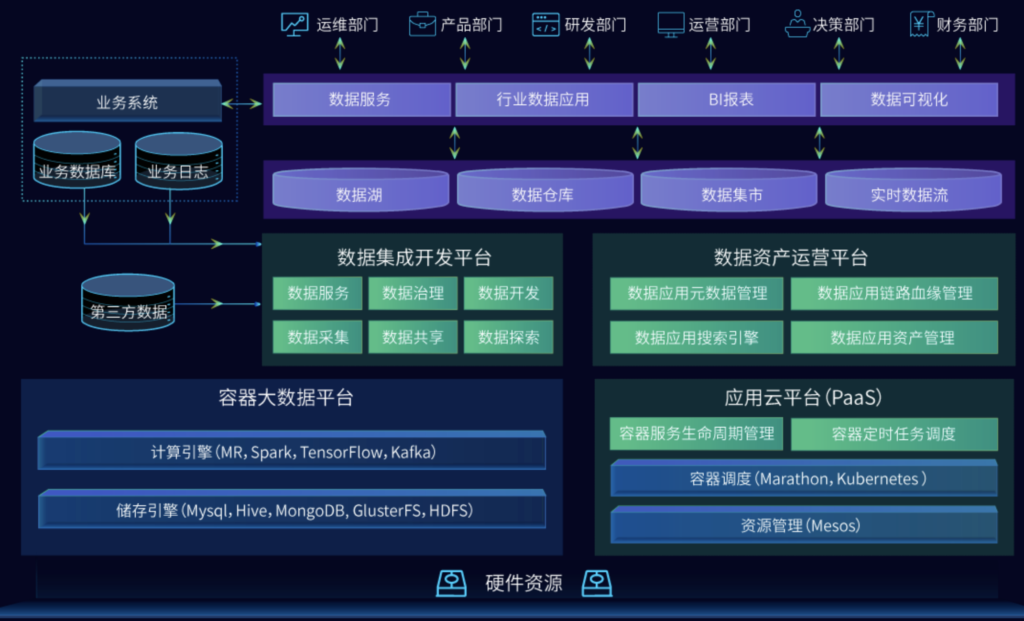
以此为基础,我们构筑了一套包含完整数据链路,可以帮助企业提升运营模式和IT构架,即时洞察经营过程,快速反应市场变化,实现精准营销,快速推出适应市场需求产品的可高度组合定制的解决方案:
BDOS 前端架构演进
1、BFF + Serverless
BFF(Backend For Frontend),既服务于前端的后端,初衷是在后台服务与前端(客户端)之间添加一层。在 Web 架构到达此处之前,大致经历了如下时期:
传统 Web 架构(Traditional Server Side Rendering),通常由单个整体服务器组成,从数据库交互到HTML构造的所有内容都构建为单个应用程序。

千禧年后,随着 Google 推出划时代的基于 Ajax 的邮箱系统 Gmail,Web应用程序逐渐变得丰富和交互。随着Web应用程序数量的增加以及处理集中在客户端上,服务器端越来越多地使用API 发送和接收数据。
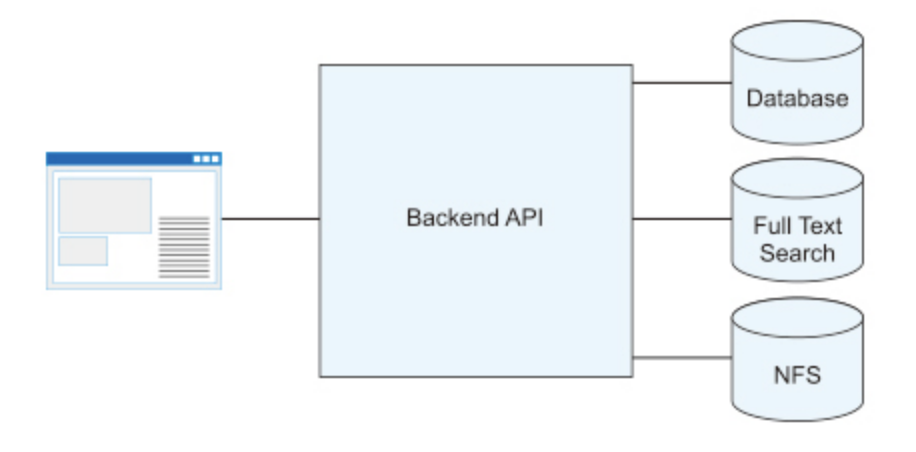
随着诸如移动应用程序和Web应用程序之类的客户端版本数量的不断增加,服务器越来越专注于 API 的实现。它被称为“微服务”,逐渐成为“专门处理特定资源的架构”。
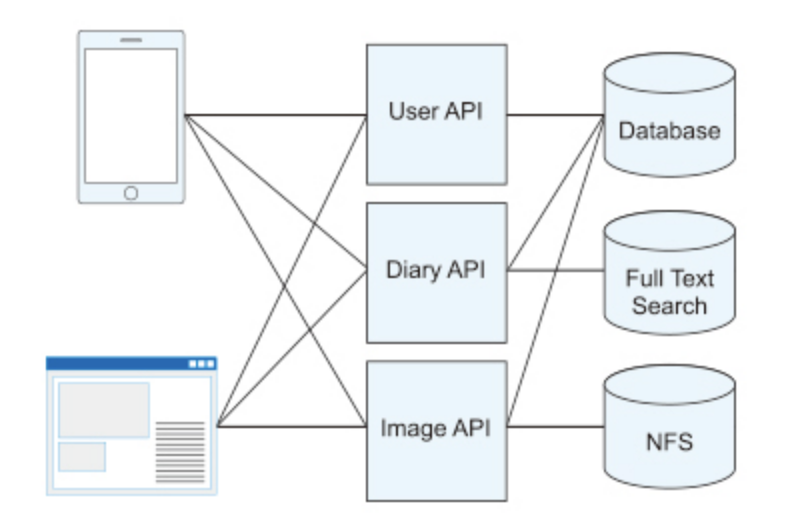
但是,随着客户端变得越来越多样化,创建满足所有客户端需求的API服务器变得很困难。即使创建移动应用程序和Web应用程序,UI也将不同。此外,每个客户所需的项目可能会有所不同。考虑到这些情况,出现了一种架构,其中用于响应每个客户端请求的服务被放置在前端侧,并充当与后端 API 服务器通信的桥梁,这就是我们所说的 BFF 架构。
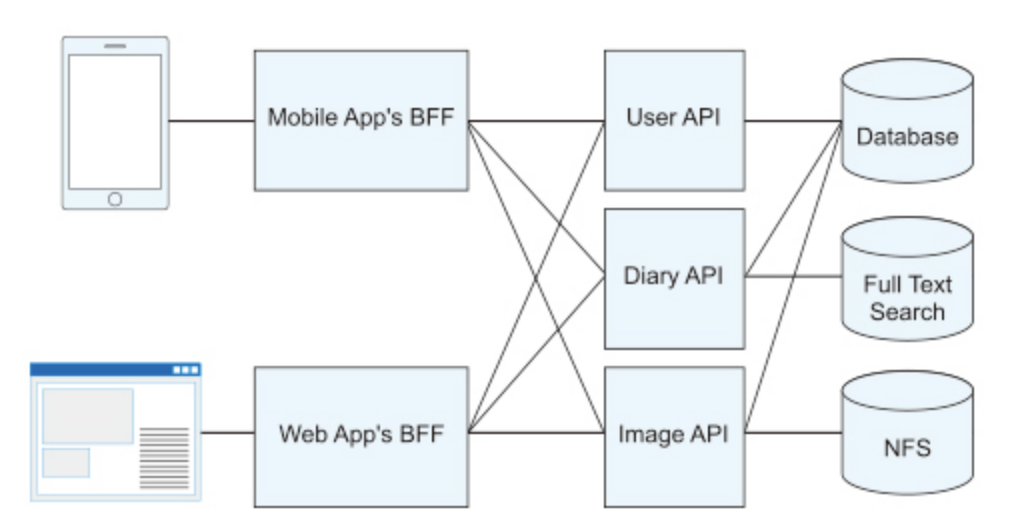
BFF 通常由负责客户端的前端工程师开发。由于 BFF 是服务器,因此可能会认为它将由后端工程师开发,但是由于它是帮助构建和操作 UI 的服务器,因此是前端工程师负责的领域。在BFF体系结构中,后端工程师负责管理资源,以 API 的形式输出。

2、Single BDOS Web App
BDOS Web App 从创建伊始就采用了 BFF 架构,最初我们考虑建立一个大一统的 SPA(Single Page App) ,将 BDOS 全链路的所有功能打包到一个客户端,通过 Immutable Store 管理不同集群模式、组织、角色、用户的权限和视角,使用 BFF 层与自研后端 Service、原生大数据组件以及各种数据源与文件系统交互,并输出统一标准的基于前端业务的 Restful API,供前端完成功能。

3、松耦合 Web App Series
随着 BDOS 涵盖大数据全链路功能的不断深入和产品线的逐渐深入,为了满足客户和产品的功能不断拆分组合、个性化功能改造和可热插拔的外部接入需求,单一 Web App 虽可接受个性化配置和定制,但面对多变的产品形态、个性化和业务隔离需求显得不再适用。
于是,我们从产品线角度对 Single BDOS Web App 进行了拆分,每个 Web App 都由一个独立的前端 + BFF 组成,BFF 负责 Web App 之间以及与后台服务、原生大数据组件、数据源和文件系统之间的通信。
架构在不断迭代演进,随后,我们又从各个 BFF 中抽象出了公共的 BFF Services,比如:
- User Service(负责打通各大数据组件之间的用户系统,输出标准化的 Restful API,通过 JWT 与 Web App 通信)
- ORM Service(基于 GraphQL,通过整合不同类型的数据源,形成标准化的 GQL API,为 Web App 提供高度自由和业务解耦的统一数据访问能力)
- API Gateway(提供了访问后端负载均衡服务器和 ABTest 分流,以及审计能力)
架构还在继续演进,以实现服务原子化、松耦合、高可复用、高度定制化和高度可维护性等为目标。
基于云原生的前端工程体系建设
随着前端开发复杂度的日益增加,各种各样适应业务的组件框架也层出不穷。同时,我们面临业务规模的快速发展和工程师团队的不断扩张,Web 业务日益复杂化和多元化,现在的前端项目,工程复杂性越来越高,同时也伴随更多的问题出现。
这时候,前端工程化的概念逐渐形成。工程化即系统化、模块化、规范化的一个过程,主要目的是提高编码、测试、维护阶段的生产效率,更好更快地完成团队开发以及项目后期维护和扩展。
前端工程化要解决如下问题:
- 统一规范
使用统一的代码规范可以有助于保持代码的可读性和可维护性,促进团队合作、降低代码维护成本、提高 code review 的效率,并且,通过养成规范书写代码的习惯,有助于团队成员自身的技术成长。往常,很多代码规范的遵守基于人力,很容易疏漏,或流于形式。通过工具和脚本的配置,我们可以将编码规范固化到流程中,自动检查甚至纠正规范上的问题,降低成本,提高效率。
我们需要统一代码命名及目录结构,如目录结构、文件命名规范,编码风格规范(eslint、stylelint)等;同时,也需要规范开发流程,以应对层出不穷的需求变更及风险;我们还需要对 API 的定义进行规范,从框架层次封装和简化更上一级的逻辑,使其更关注自己这一层的业务逻辑。
- 流程控制
为了使代码的管理和提交兼顾实用性、规范性和成本,通过不断优化迭代,我们形成了一套基于 Git 的分支、commit、pull request 的流程规范,其中涵盖了从主分支切开发分支的命名规则、提交代码时 commit 内容的书写规则(并使用 pre-commit 等自动化工具,对其进行进行校验),当本地自测无误后,创建 pull-request。通过 git 钩子进行初步自动化检查,并进行必要的 code review 后,再合并代码到主分支。我们还要求每一次 pull request 都保持与任务的关联性、原子性和功能的独立性,最大限度降低由于代码提交和合并所带来的副作用(如代码冲突、引入新 BUG 或不一致的代码风格及实现等)。
- 最佳实践
使用合适的前端技术和框架,提高生产效率,降低维护难度,实现 职责分离、降低耦合,增强代码的可读性、维护性和测试性的目标。采用模块化的方式组织代码,比如 JS(AMD、CommonJS、UMD、ES6 Module) 和 CSS(less、sass、stylus、postCSS、css module) 的模块化;采用组件化的思想,引入 MVVM 框架(如 Vue、React),保持多数模块或组件的无状态、高度可复用、可维护性;采用数据状态管理工具(如 Vuex、Redux),将数据层分离管理,使组件与数据之间进一步解耦;使用面向对象或者函数编程的方式组织架构。
- 质量保证
提高代码的可测试性,引入单元测试(如 karma + mocha + chai、jest、ava)和自动化端到端测试(Katalon、ui recorder),提高代码质量。
对于上游交付的 RestAPI,使用 yapi、rap、postman 等工具进行统一的管理和自动测试。基本流程是:前后端通过工具化平台进行 API 路由、类型、参数和配置的讨论和更新,并自动生成 mock api;而后,前端基于 mock api 开发,后端同步实现对应的 API,并使用工具化平台的自动化测试工具校验通过后,再进行前后端联调。最大限度减少前后端工作进度的依赖和耦合性。
而上游交付的设计稿,则统一使用 Zeplin 进行托管、审核、版本管理和交付。设计师和产品经理的设计输出物,统一作为输入,上传到单一平台,而后,作为标准化的格式输出和呈现,并实现在设计过程中实时进行上下游多方确认和审核。至此,开发人员无需关心设计工具的种类和使用,设计人员也无需关心切图的规范性问题(切图和分层规则可以托管在平台),达到设计和开发工作的异步和解耦,提高工作效率。
- 自动化
通过使用各种自动化的工程工具(比如:脚手架工具 yeoman、create-app、vue-cli、vite;前端构建工具 gulp、grunt、Broccoli;编译工具Babel、Browserify、Webpack;开发辅助工具 livehood、chrome-driver;CI 集成工具 Jenkins、Travis CI、Github Actions 等),提升开发、自测、部署效率。通过编写脚本或自动化工具及其插件的组合,实现了整个开发流程的多数重复操作自动化,减少了出错的概率,达到了降低人力参与、提高人效的目的。
数据可视化实践
数据可视化研究的是,如何将数据转化成为交互的图形或图像等,以视觉可以感受的方式表达,增强人的认知能力,达到发现、解释、分析、探索、决策和学习的目的。
“数据可视化(Data Visualization)和信息可视化(Infographics)是两个相近的专业领域名词。狭义上的数据可视化指的是数据用统计图表方式呈现,而信息可视化则是将非数字的信息进行可视化。前者用于传递信息,后者用于表现抽象或复杂的概念、技术和信息。而广义上的数据可视化则是数据可视化、信息可视化以及科学可视化等等多个领域的统称。”——《数据可视化之美》
科学可视化(Scientific Visualization)是可视化领域最早、最成熟的一个跨学科研究与应用领域[石教英 1996]。面向的领域主要是自然科学,如物理、化学、气象气候、航空航天、医学、生物学等各个学科,这些学科通常需要对数据和模型进行解释、操作与处理,旨在寻找其中的模式、特点、关系以及异常情况。
信息可视化(Information Visualization)处理的对象是抽象数据集合,起源于统计图形学,又与信息图形、视觉设计等现代技术相关。其表现形式通常在二维空间,因此关键问题是在有限的展现空间中以直观的方式传达大量的抽象信息。与科学可视化相比,科学可视化处理的数据具有天然几何结构(如磁感线、流体分布等),信息可视化更关注抽象、高维数据。柱状图、趋势图、流程图、树状图等,都属于信息可视化最常用的可视表达,这些图形的设计都将抽象的数据概念转化成为可视化信息。
可视分析学(Visual Analytics)被定义为一门以可视交互为基础的分析推理科学。它综合了图形学、数据挖掘和人机交互等技术,以可视交互界面为通道,将人感知和认知能力以可视的方式融入数据处理过程,形成人脑智能和机器智能优势互补和相互提升,建立螺旋式信息交流与知识提炼途径,完成有效的分析推理和决策。
数据可视化是数据(Dataset) 到视觉元素(VisualMap) 的映射过程(这个过程也可称为视觉编码,视觉元素也可称为视觉通道)。
常用的视觉元素(VisualMap)有图形类别(Symbol)、图形大小(SymbolSize)、颜色(Color)、透明度(Opacity)、颜色透明度(ColorAlpha)、颜色明暗度(ColorLightness)、颜色饱和度(ColorSaturation)、色调(ColorHue)。
我们首先需要关注的是数据思维考虑问题的方式,在传统思维模式中,我们通常会从方法论、公理推导、因果关系的方面考虑事物之间的关系或推断未知情况,而在大数据思维模式下,我们通常从事件发生的关联性,倒推事物之间的相关性,继而进行判断或推测。
我们解读数据的方法也在不断的变更:最开始,我们采用人工决策,既依靠数据分析人员的专业分析;而后,分析人员(不一定深度专业)利用工具或平台进行分析;随着大数据技术的不断演进,通过机器自主思考、学习和判断进行智能决策逐渐变为了现实。
进行数据可视化之前,需要先进行数据分析,路径主要包含数据采集、数据存储、数据清洗和计算、数据服务等。用一张经典的图来说明如何进行数据可视化:
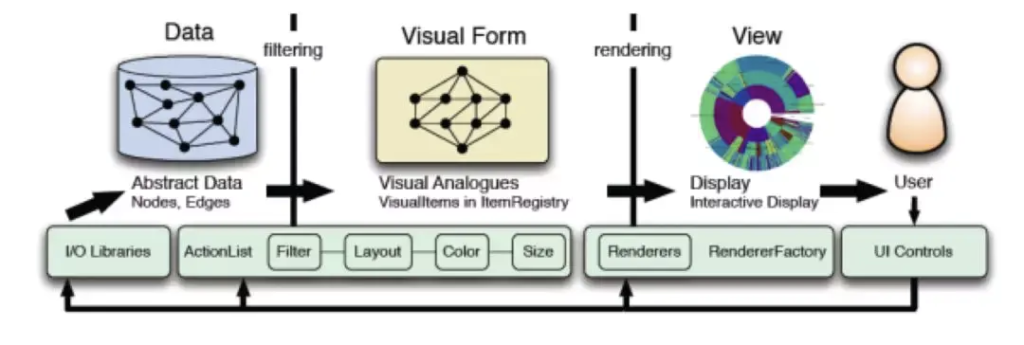
先定义数据可视化要解决的问题,可以从 趋势、对比、分布、流程、时序、空间、关联性等角度来定义。接着,确定要展示的数据,由于画布大小的限制,过量的数据不能够在直接显示出来,所以要确定展示的数据,需要考虑可能的问题,比如:数据是否 ready。是否有异常的值;是扁平还是树状的数据;数据的规模;是否需要对原始数据进行进一步的处理,比如聚合或分层展示数据;是否需要在展现过程中根据业务对数据进行进一步处理。而后,需要确定要显示的数据维度,对字段进行选择,选择不同的字段在后面环节中选择适合的图表类型也不同。最后,也需要根据要解决的问题、数据的结构、选择的数据维度来确定要显示的图表类型。
目前数据可视化的需求场景主要分为如下几种:
通用报表,使用一般的图表库来满足日常的开发需求,这类需求一般使用业内比较常用的开源图表库,如 echarts、highcharts、d3 等来实现;
移动端图表,基于性能和屏幕可视范围以及兼容性的考虑,根据业务实际,选择同时兼容 PC 或移动端的开源图表库如 G2,或专注移动端的图表库如 F2;
大屏可视化,聚焦于会议展览、业务监控、风险预警、地理信息分析等多种业务的展示,在图形渲染、可视化设计方面都有很高的要求,目前几乎已成为to B项目的标配,应用场景越来越广泛;
关系图:图可视化主要有图编辑(用于图建模(ER图、UML图)、流程图、脑图等,需要用户深入参与关系的创建、编辑和删除的场景)和图分析(用于风控、安全、营销场景中的关系发现,对图的一些基本概念进行业务上解读,环、关键链路、连通量等)两大领域。目前主流的开源框架有:jointjs(聚焦于图编辑,包含了常见的流程图和BPMN 图的功能,上手容易,开箱即用但是二次开发非常困难)和 d3.js(非常底层的可视化库,有大量图分析场景的案例,上手成本高,demo 同业务的距离比较大);
地理数据可视化主要是对空间数据域的可视化,主要有三大领域:信息图(主要用于展示位置相关的报表,信息图,路径变化等等)、大屏应用(大屏展示一般以地理数据为载体,如建筑,道路,轨迹等数据可视化)、地理分析应用(往往是海量地理数据的交互分析,用户基于位置的用户推荐,拉新,促活等业务运营系统,或者选址,风险监控等系统)
具体实现时还需要考虑超大规模数据的可视化场景,为了兼顾性能和可用性,我们可以使用数据分层、数据聚合、数据抽样等方式来实现。
前端能力中台化探索
所谓中台,就是把公司技术、业务、组织中高频的、通用性强的、可系统化的部分抽离、固化到信息系统里,从而减少重复劳动,降低人力成本,提高公司的盈利能力。
随着 BDOS 大数据业务的不断展开,Web 工具及框架开发、产品业务逻辑实现、外部交付个性化、与业务场景高度耦合的项目实施等工作之间的互相干扰越来越严重,如何更好地平衡内部核心产品迭代和外部项目交付的资源调配关系,解耦以上不同类型的开发工作和资源,解耦各层次的资源、迭代和交付物,使其更大程度地无状态化成为了刚需。
为了实现该目标,我们需要将团队的能力通过工具、流程和方法的方式输出到公司,在某些场景实现技术实现与人的分离。
通过维护前端组件库和 BFF 公共模块库,公司内可以通过 Npm / Deno Url / Dynamic Import 等方式方便地引入封装过的自研模块或组件;通过将设计师的稿件抽象为 Style Guide,并通过 Component 的方式形成可配置的前端组件库,达到低前端技术的开发人员也可以快速通过公司内的公共资源快速组合,开发出灵活的自定义 Web App
除此之外,我们通过自研的基于 Json-Schema 的表单渲染引擎,和基于 Json 配置的自助页面渲染平台,可通过接入 User Service、ORM Service 和 API Gateway,实现对数据流水线输出物的自助消费能力。
留言
评论
暂时还没有一条评论.