基于BDOS数仓建设实践 | 第八期图文直播文字回放
3月4日晚,智领云第八次社群图文技术直播如约而至。本次直播由智领云大数据应用开发经理 Robin为大家带来了《基于BDOS数仓建设实践》的主题分享,其中主要内容包括:数仓建设演进、理论及规范;BDOS大数据平台介绍;基于BDOS大数据平台数仓建设实践
数仓建设演进、理论及规范
什么是数据仓库
数据仓库,英文名称为Data Warehouse,可简写为DW或DWH。数据仓库,是为企业所有级别的决策制定过程,提供所有类型数据支持的战略集合。它出于分析性报告和决策支持目的而创建。为需要业务智能的企业,提供指导业务流程改进、监视时间、成本、质量以及控制。
数据仓库的特点
面向主题,与传统数据库面向应用进行数据组织的特点相对应,数据仓库中的数据是面向主题进行组织的。
面向主题的数据组织方式,就是在较高层次上对分析对象数据的一个完整、一致的描述,能完整、统一地刻划各个分析对象所涉及的企业的各项数据,以及数据之间的联系。
比如电商领域常见的主题划分:用户主题、订单主题、商品主题、配置主题、活动主题等。
集成的,面向事务处理的操作型数据库通常与某些特定的应用相关,数据库之间相互独立,并且往往是异构的。而数据仓库中的数据是在对原有分散的数据库数据抽取、清理的基础上经过系统加工、汇总和整理得到的,必须消除源数据中的不一致性,以保证数据仓库内的信息是关于整个企业的一致的全局信息。
相对稳定的,操作型数据库中的数据通常实时更新,数据根据需要及时发生变化。数据仓库的数据主要供企业决策分析之用,所涉及的数据操作主要是数据查询,一旦某个数据进入数据仓库以后,一般情况下将被长期保留,也就是数据仓库中一般有大量的查询操作,但修改和删除操作很少,通常只需要定期的加载、刷新。
反映历史变化,操作型数据库主要关心当前某一个时间段内的数据,而数据仓库中的数据通常包含历史信息。
数据仓库架构
数据仓库的基本架构主要包含的是数据流入流出的过程,可以分为三层——数据获取、数据仓库、数据应用:
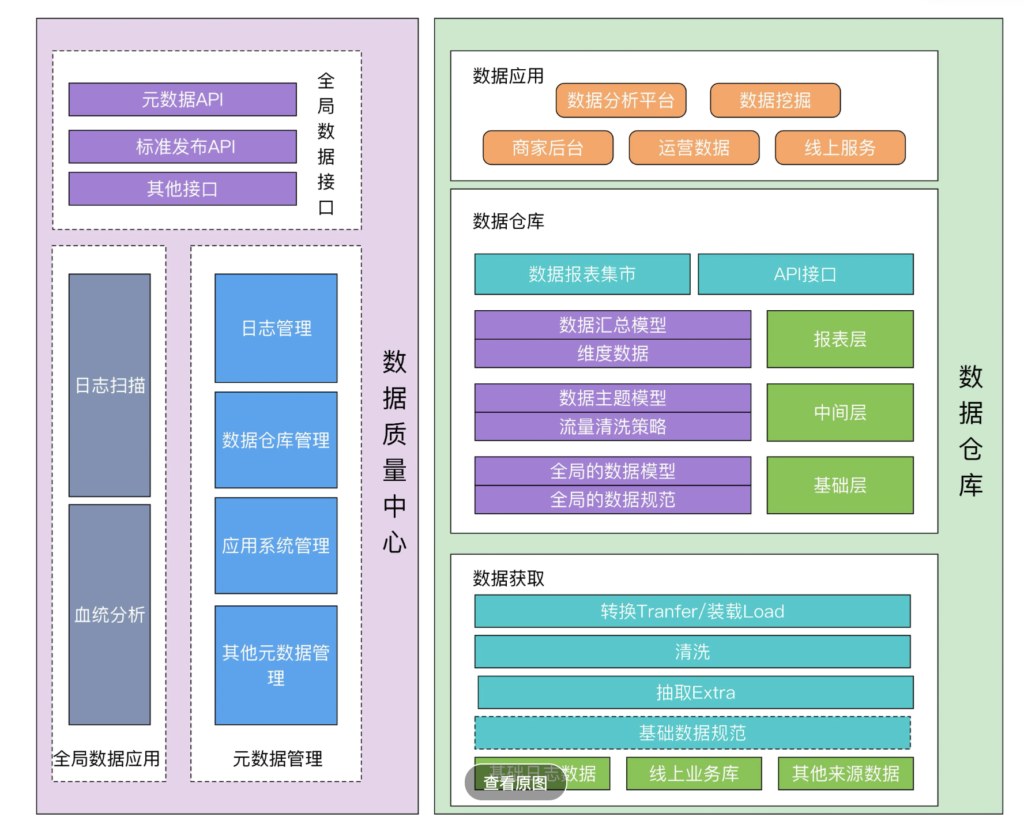
数据仓库分层
借鉴京东数仓分层架构,大致分四层架构:
数据缓冲层(BDM):源业务系统数据的快照,保存细节数据,按天保存基础数据层(FDM):按业务概念组织细节数据,并进行名称、代码等标准化处理,同时对表进行标准化处理。
通用数据层(GDM):根据京东核心业务价值链按照星型模型或雪花模型设计方式建设的最细业务粒度汇总层。在本层需要进行度量与维度的标准化,保证度量数据的唯一性。
聚合数据层(ADM):根据不同的业务需求采用星型或雪花型模型设计方法构建的数据汇总层。
维度层(DIM):维度是对具体分析对象的分析角度,维度要具备丰富的属性,历史信息的可追溯性,对通用的维表要保持一致性。
也可以参考另一种通用的数据分层设计,将数据模型分为三层:数据运营层( ODS )、数据仓库层(DW)和数据应用层(APP)。
数仓建设规范
数仓分层:贴源层(ODM)、基础数据层(FDM)、通用数据层(GDM)、应用数据层(ADM)。
主题域划分:用户主题、订单主题、商品主题。
规范性:命名、类型、注释、默认值规范。
完整性:数据清洗、处理、加工过程中,数据没有缺失和遗漏的。
准确性:宽表和集市表结果正确。
一致性:字段名称、类型、释义保持一致。
BDOS大数据平台介绍
BDOS大数据平台是基于云原生数据驱动IT架构的容器化大数据平台,利用云计算优势来构建和运行大数据应用程序。
大数据平台主要组件有:数据集成中心系统、标签系统和数据服务平台。

我们今天主要分享,在数仓建设过程使用到的核心组件,BDOS数据集成中心系统(以下简称 FlowMan)。
BDOS数据集成中心系统
BDOS数据集成中心系统(以下简称 FlowMan)是智领云自主研发的一款集数据集成、数据开发、数据资源管理、安全控制为一体的工具,填补了大数据领域基于容器化任务调度的市场空白,原生支持容器调度,实现容器化批处理任务的编排、调度、监控。
基于我们的FlowMan,可以快速搭建数据湖和数据仓库,做到数据安全和权限管理,实现数据的共享和赋能。

FM数据开发
FM支持数据抽取、转换、加载(ETL),数据汇聚,数据的复杂计算以及Yarn,Spark,Clickhouse,Python等计算。
数据采集
Sqoop批采集 – 实现结构化数据到大数据系统的数据导入,通过该作业从不同的数据源(包括Oracle,MySQL,MongDB等)中采集数据到目标数据库,如Hive,HDFS等,实现数据的导入。
流采集 – 支持实时同步binlog的方式,实现对MySQL数据库表的流采集。
自定义采集 – 用户可自行添加本地程序用于做数据爬取或数据导入,进行试运行并查看结果日志,支持把运行成功的程序转换成作业定时周期性运行。
数据治理
Hive作业 – 系统支持用户创建Hive作业,可通过直接编写HQL,也可调用用户上传的自定义Hive函数,实现数据清洗、统计等。
Spark作业 – 系统支持用户创建Spark作业,可使用Spark计算引擎对批处理数据进行数据清洗、整合。
SparkSQL作业 – 系统支持用户创建SparkSQL作业,可通过直接编写SparkSQL,对批处理数据进行数据清洗、整合。
Clickhouse作业 – 系统支持用户创建Clickhouse作业,可以通过直接编写Cilckhouse SQL,对批处理数据进行数据清洗、整合。
自定义作业 – 系统支持用户创建自定义作业,用户可以根据自己的需求,上传自定义的程序,对批处理数据进行数据清洗、整合。
数据转换
数据转换作业对目标数据源的输出进行转换,转换的方式有JDBC、Sqoop和DataX三种方式,支持的输入源包括 HDFS、Hive、Mongo、MySQL、Oracle、Clickhosue等,支持的输出源包括 Hive、MySQL、Oracle、ElasticSearch、HBase、MPP(PgSql)等。
FM作业编排和任务调度
FM支持容器调度,实现容器化批处理任务的编排、调度、监控,是一个集程序管理和数据资源管理、安全为一体的任务调度工具。
用户可以轻松地管理成百上千乃至上万个数据开发任务(采集、治理 和 转换),并允许用户根据业务需要,将多个有依赖关系的作业串成工作流,从而实现任务的调度,极大简化数据从采集到转换和治理的整个流水线。

基于BDOS大数据平台数仓建设实践
建设背景
在新零售转型过程中,数仓建设是其中一个核心的工作,通常会遇到下面这些问题:
- 如何搭建大数据平台?
- 如何使用大数据平台的开发工具?
- 如何提高数仓模型设计质量?
- 如何提高数仓开发和运维效率?
- 如何具备数据服务和应用能力?
下面我们将介绍基于FM,如何搭建数据仓库,提供数据服务。
建设方案

数据源支持多种采集方式:
- 基于自研开发的埋点SDK工具,实现用户行为数据的实时采集。
- 基于自研开发的Flowman产品,实现对业务数据的批量采集。
- 基于自研开发的广告采集器工具,实现对不同广告商的广告数据采集。
数仓建设包括:
- 数据仓库,面向主题的、集成的、分层的数据集合。
- 数据服务,提供数据API服务化的组件。
- 标签系统,提供数据标签服务的组件。
- 其他组件。
数据应用:
- 自助报表,自助化的报表工具Superset。
- 用户行为分析,基于用户行为数据和ERP数据,做深度的用户行为分析。
- 广告渠道分析,打通渠道数据和ERP数据,提供更加准确的广告质量分析及监控。
- 用户画像,基于用户基本信息、ERP统计信息、用户行为数据刻画更加完整的用户画像模型。
- 商品推荐,基于用户的浏览和用户画像模型,实现个性化的用户推荐。
数仓模型,是整个数仓设计的基础性工作。数仓模型不只是考虑如何设计和实现功能,设计原则应该从访问性能、数据成本、使用成本、数据质量、扩展性来考虑。
维度建模是一个迭代设计过程,设计工作从总线矩阵中抽取实体级别的初始图形化模型开始,详细建模过程要深入定义、资源、关系、数据质量问题以及每张表的数据转换,主要目标是建立满足用户需求的模型,校验可加载到模型中的数据,为ETL提供明确的方向。
下面是一个以用户、订单、商品为事实表的数仓模型:
数仓ER模型包括:用户表(isc_user_info),订单表(isc_order),商品表(isc_product),订单商品表(isc_order_product),用户钱包表(isc_user_wallet_record),用户优惠券表(isc_user_coupon_record)
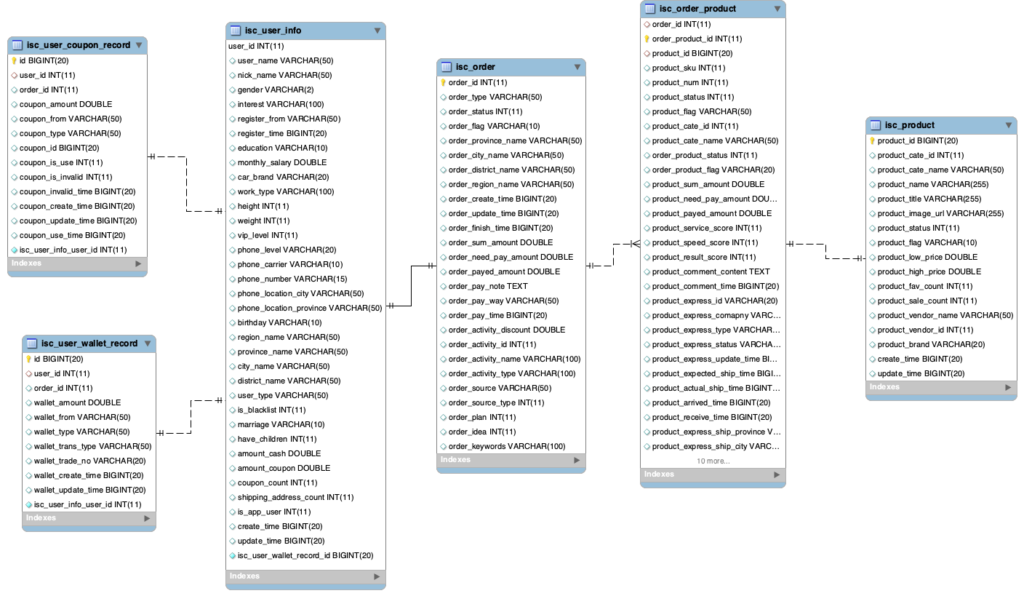
ETL设计
ETL是将业务系统的数据经过抽取、清洗转换之后加载到数据仓库的过程,目的是将企业中的分散、零乱、标准不统一的数据整合到一起,形成数仓,生成报表和应用。ETL设计的好坏,直接决定了数仓建设的成效。
ETL设计会随着对业务、系统理解的深入以及结构框架的变化而发生变化,应该遵循一定的设计规范。主要包括:命名规范、功能定义规范、结构规范。
下面是以新零售行业为例,抽象出来的ETL设计。

ETL实现
在数仓建设过程中,你可能会发现,80%的时间都用在ETL的实现和调试过程中,所以一个好的ETL数据实现工具,是可以帮助你在数仓建设过程中,起到事半功倍的作用。
我们的FM产品,通过简单的作业和作业流方式,让复杂的ETL实现简单化,让用户能够在FM上快速实现和调试ETL,并且支持Hive、Spark、SparkSQL、Clickhouse、MySQL等多种数据加工方式。
下面是以新零售行业为例,抽象出来的一个简单的ETL实现。

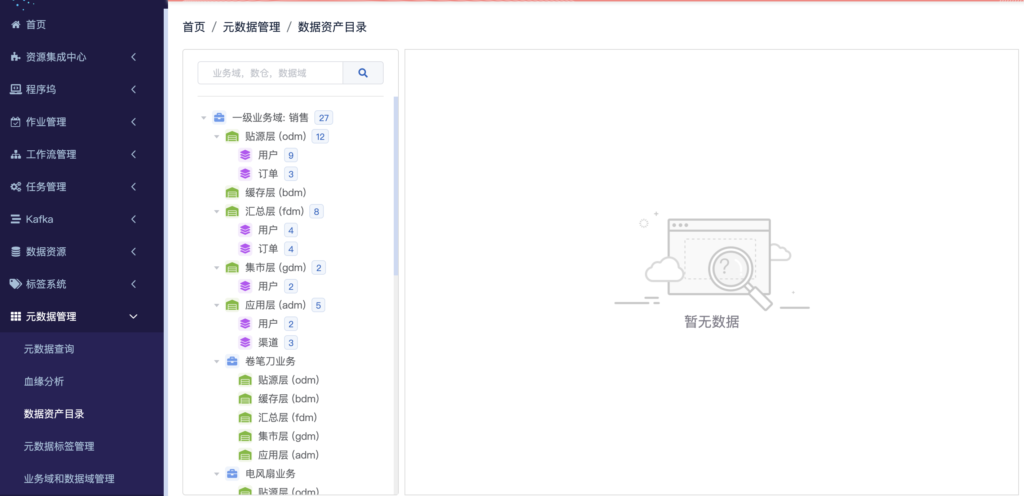
数据资产目录
企业通过数仓模型,ETL设计及实现,完成了数仓建设之后,下一步就是需要对数据的资产进行管理,发现和释放数据的价值。
在我们FM平台上,同样也集成了数据资产管理,我们可以通过定义业务域和数据域,将我们的数据资产,进行可视化的管理。
当我们建设好了数仓,并完成了数据资产的管理,下一步我们将对数据进行赋能。
留言
评论
暂时还没有一条评论.