数据工程-工作流与依赖视图
工作流与依赖视图
用户进入数据工程,系统默认以工作流与依赖视图的呈现方式进行展现步骤间的依赖关系。初次进入的界面如下:
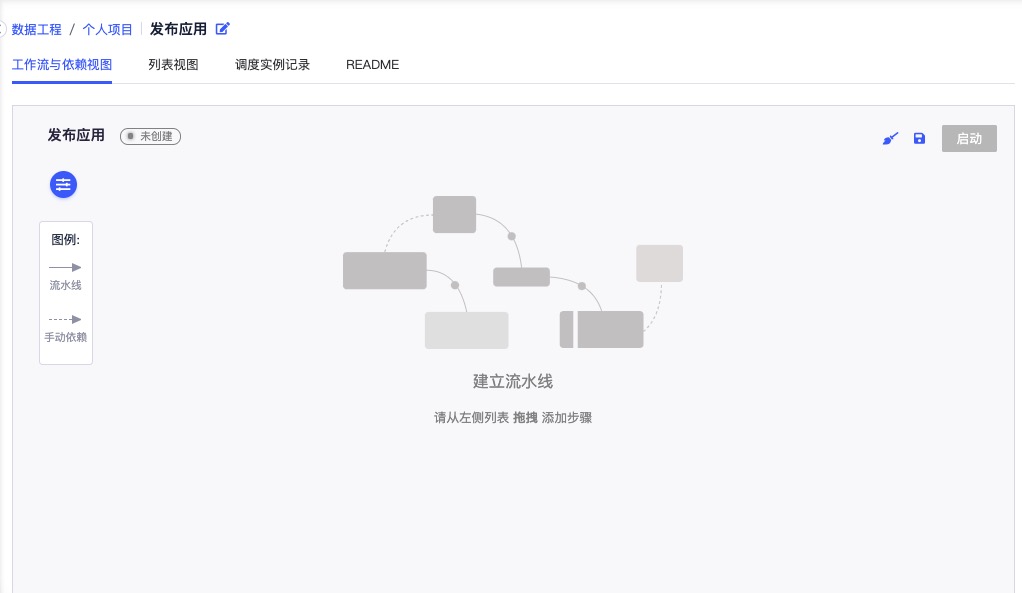
图例
用户可在左上角看到标识流水线和手动依赖的两个箭头:
- 流水线:通过实线,表示可根据流水线依赖关系,按顺序自动运行流水线连接的步骤
- 手动依赖:通过虚线,表示可手动建立步骤间的逻辑依赖关系,且需单独在步骤中直接运行,不能在流水线中统一运行
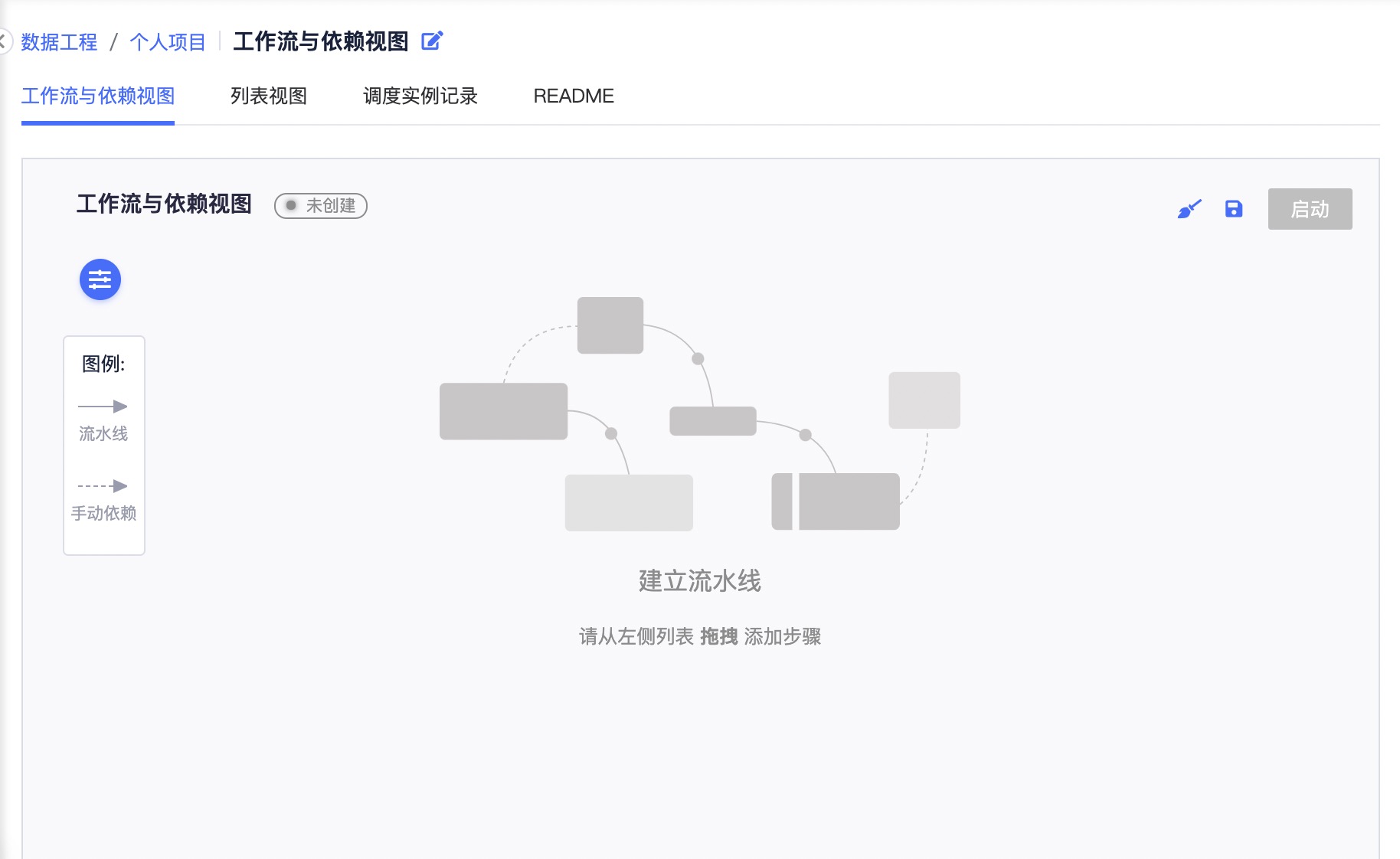
流水线步骤
系统当前版本支持的流水线步骤包括:
| 类别 | 步骤名称 | 流水线类型 | 是否需要试运行 |
|---|---|---|---|
| 数据采集 | 数据库采集 | 流水线 | 是,流水线统一运行前,需试运行一次 |
| 爬虫采集 | 流水线 | 是,流水线统一运行前,需试运行一次 | |
| 数据转换 | ETL程序 | 流水线 | 是,流水线统一运行前,需试运行一次 |
| 数据分析 | Hive程序 | 流水线 | 是,流水线统一运行前,需试运行一次 |
| Spark程序 | 流水线 | 是,流水线统一运行前,需试运行一次 | |
| Saprk SQL程序 | 流水线 | 是,流水线统一运行前,需试运行一次 | |
| JupyterNotebook | 流水线 | 是,流水线统一运行前,需试运行一次 |
手动依赖步骤
系统当前版本除了以上可以在流水线中统一自动运行的步骤,其他步骤都为建立手动依赖关系的步骤,包括:
| 类别 | 步骤名称 | 流水线类型 |
|---|---|---|
| 数据采集 | 文件上传 | 手动依赖步骤 |
| URL文件导入 | 手动依赖步骤 | |
| 数据转换 | HDFS到Hive导入 | 手动依赖步骤 |
| 数据质量 | 数据质量(即将推出) | 手动依赖步骤 |
| 数据管理 | 创建MySQL表 | 手动依赖步骤 |
| 创建Hive表 | 手动依赖步骤 | |
| 数据服务 | API | 手动依赖步骤 |
| 数据应用 | Spring Boot应用 | 手动依赖步骤 |
| Tomcat应用 | 手动依赖步骤 | |
| Python应用(即将推出) | 手动依赖步骤 | |
| BI报表 | Superset图表(即将推出) | 手动依赖步骤 |
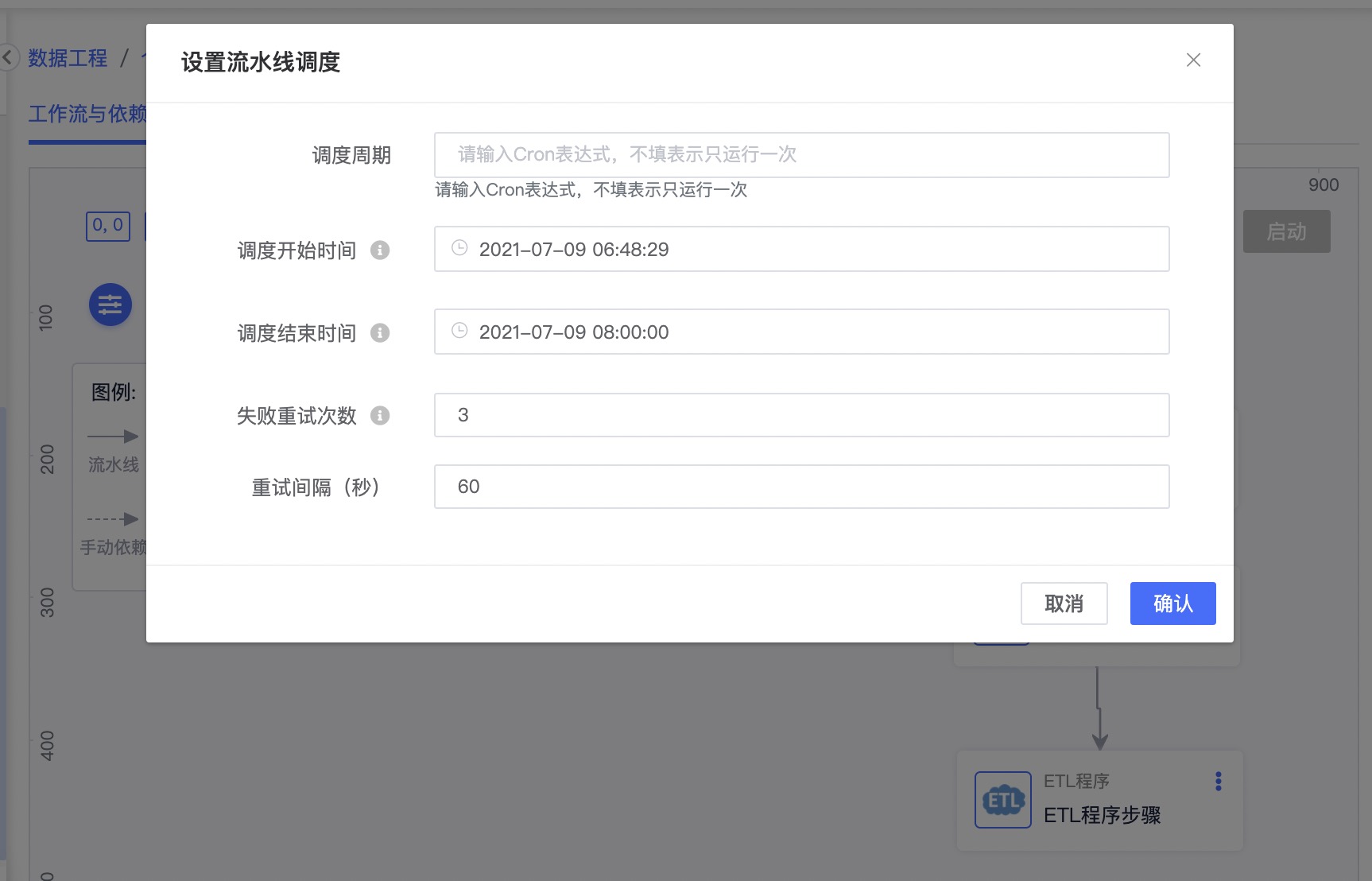
设置流水线调度
用户可通过对调度周期、调度时间等的设定,对整条流水线配置调度属性,从而进行自助、定时按依赖关系顺序调度运行。带调度属性的流水线启动后,可通过挂起流水线并修改调度周期和调度时间等设置,实现流水线调度属性的修改。
点击流水线调度图标,可对调度周期进行设置。
| 名称 | 内容 | 描述 |
|---|---|---|
| 调度周期* | 填入Cron表达式 | 不填表示只运行一次。用户可选择系统默认的调度周期(包括:每天运行一次、每小时运行一次、每分钟运行一次、每30秒运行一次、只运行一次);也可自定义调度周期,如指定在每周固定的一天或每天固定的时间段运行等 |
| 调度开始时间* | 必填。记录任务调度的起始时间。当设置的调度开始时间晚于当前时间,则从设置的调度时间开始进行任务调度;当设置的调度时间早与当前时间,则从配置的调度时间开始进行任务调度。 | |
| 调度结束时间* | 必填。记录任务调度的终止时间。当到达设置的调度结束时间时,任务将不再被调度。 | |
| 失败重试次数* | 不填则默认为3。如单个任务失败重试次数超过此次设置的重试次数,后续的任务将不再被调度。 | |
| 重试间隔(秒)* | 不填则默认为60。设置每次重试的间隔时间 |
保存
点击保存
启动
点击启动,可启动流水线并对流水线内步骤根据依赖关系(流水线),根据设置的调度时间定时统一按顺序运行。
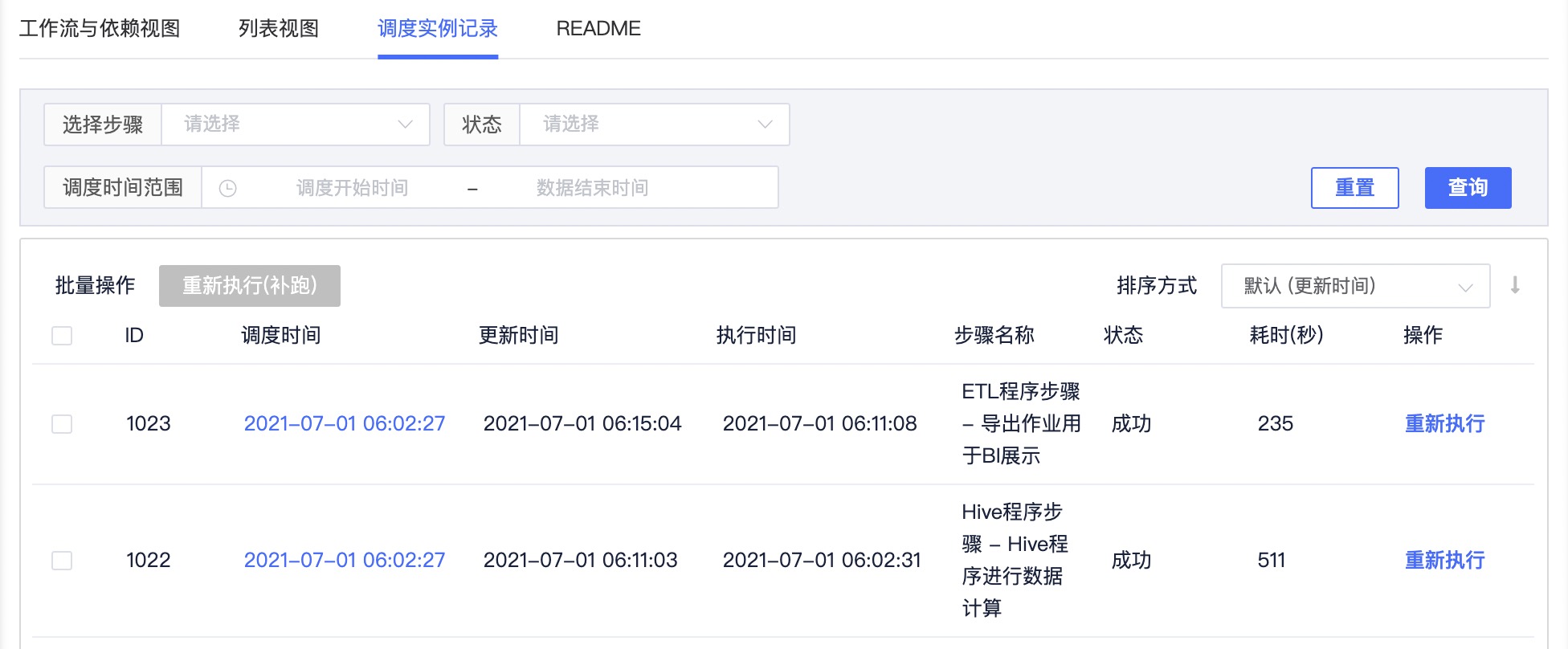
调度实例
可通过调度实例记录查看任务调度的记录,并可指定步骤进行重新执行。
留言
评论
暂时还没有一条评论.