机器学习-反欺诈检测
本项目目的是对模拟的银行转账异常现象进行侦查,对银行交易的数据进行检测,起到反欺诈的作用。 通过读取的数据集原网址为 creditcard_link ,数据集包含欧洲部分持卡人在2013年9月使用信用卡进行交易的Demo数据,使用 Jupyterlab 进行模型训练,筛选出最优模型得出最佳预测结果,并对数据进行主成分分析及三维图形展示。
本介绍将以向导的形式,向大家展示一个机器学习分类分析实例,包括数据采集、数据处理和数据分析这几个步骤:
- 银行转账Demo数据采集
- 进入 JupyterLab环境
- 数据处理与导出
- 分类模型
- GBT分类模型调参
- PCA降维视觉化
完整步骤内容文档下载
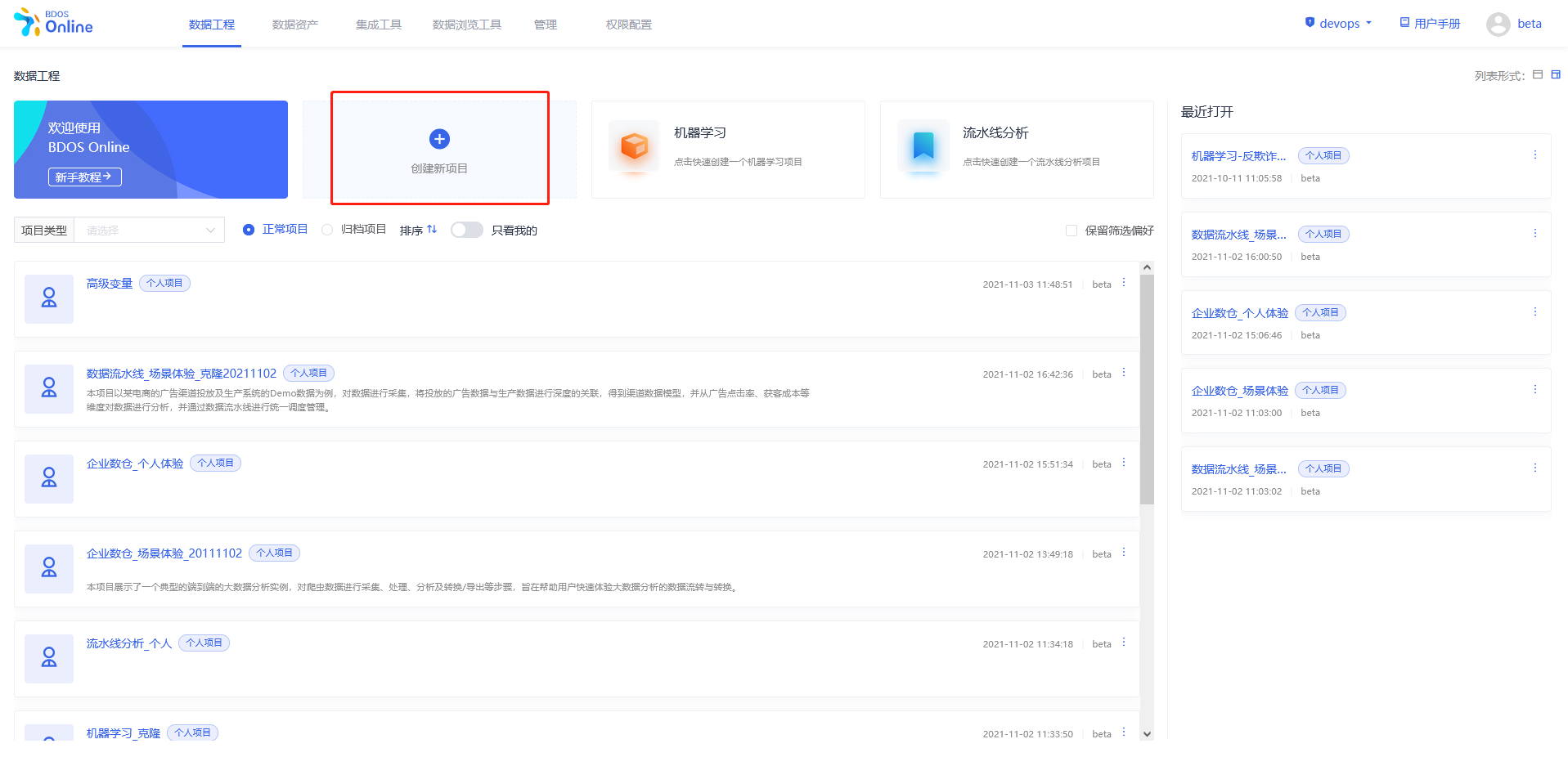
步骤一:新建个人/机构项目
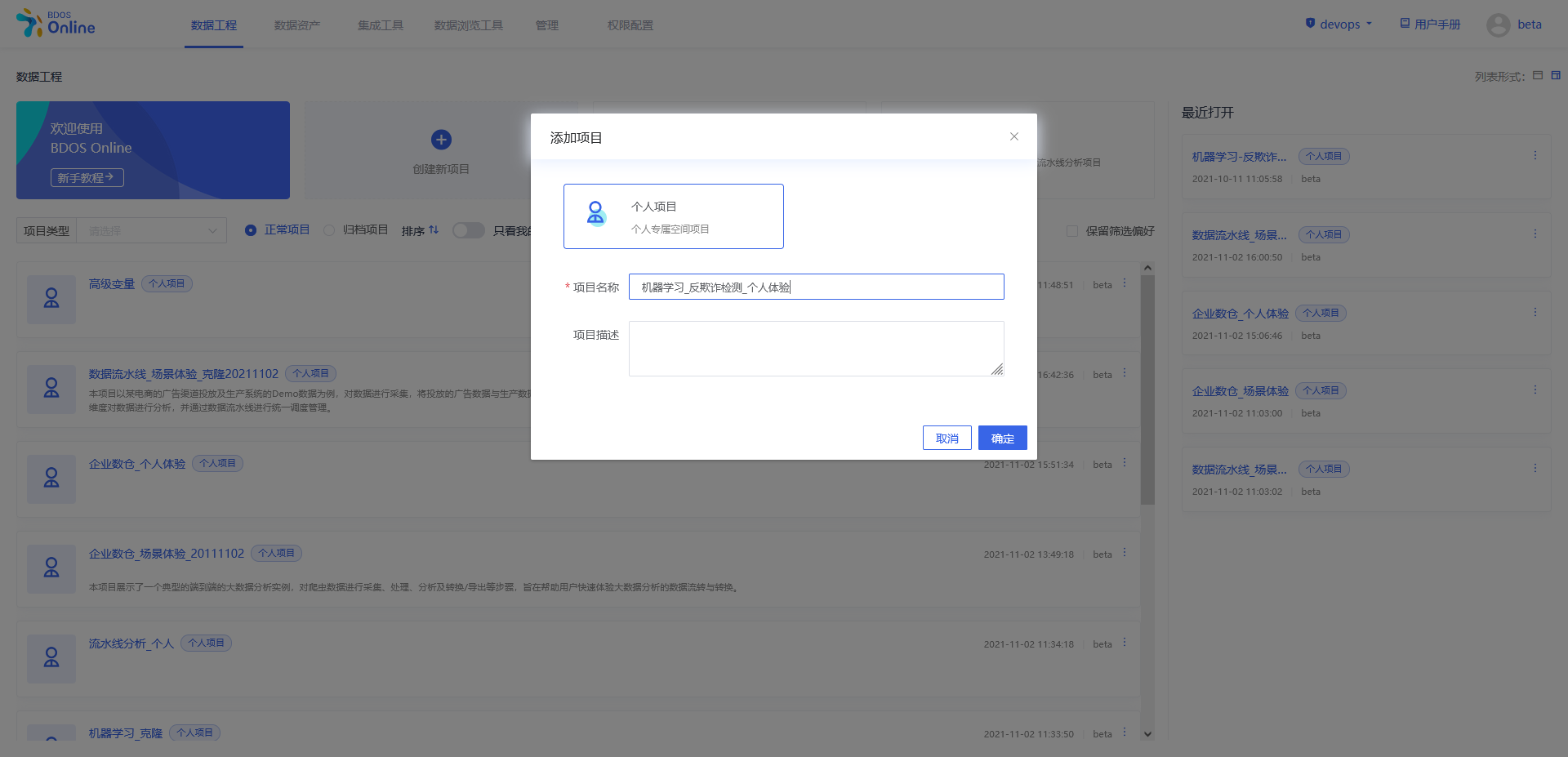
用户点击界面上创建新项目,填写名称可参照下图、
步骤二:添加项目步骤
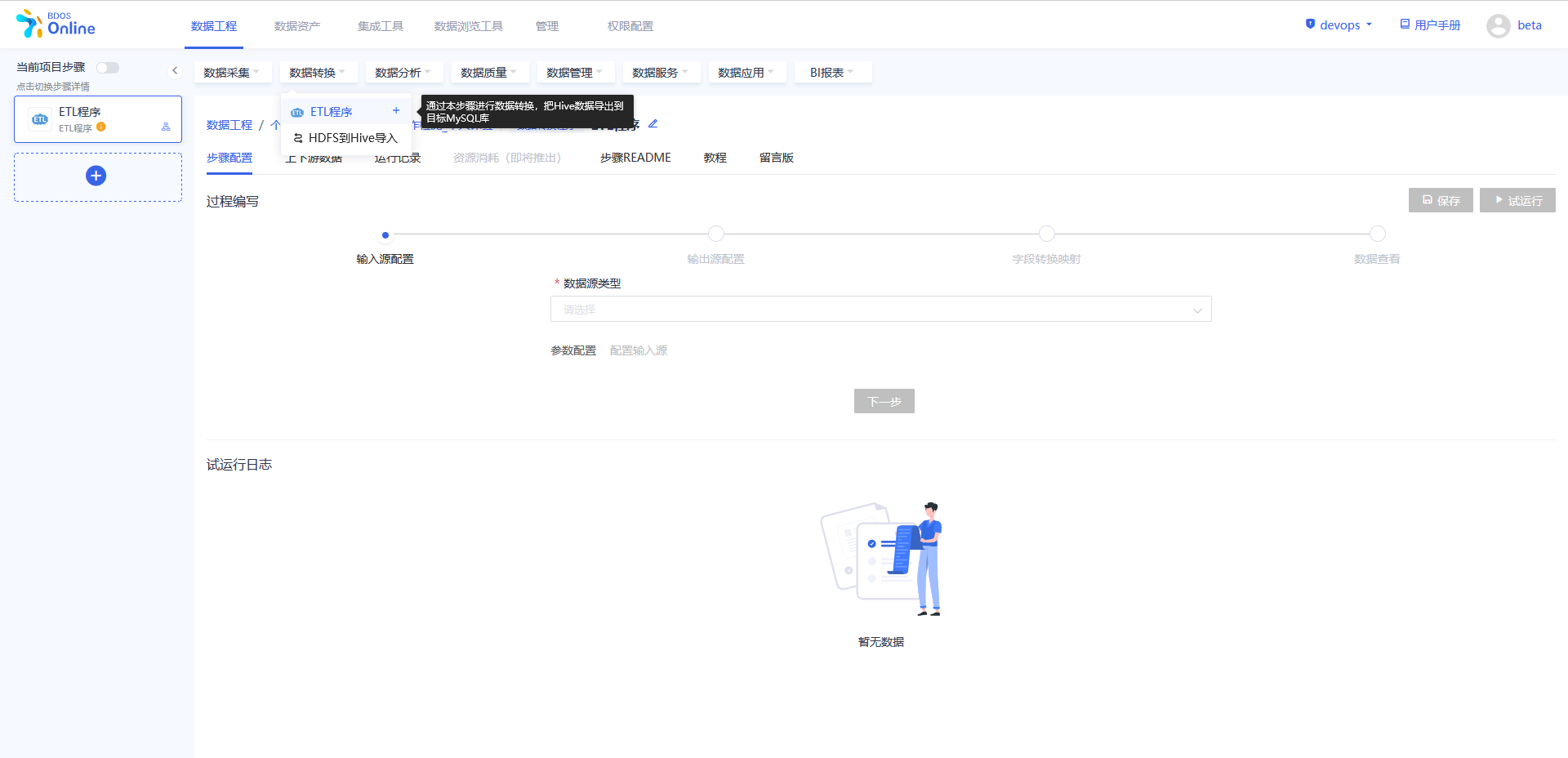
从当前项目步骤中进行添加,点击各个目录中的具体操作,依照该方法,分别添加以下几个步骤:
1.数据采集–URL文件导入
2.数据分析–jupyterNotebook
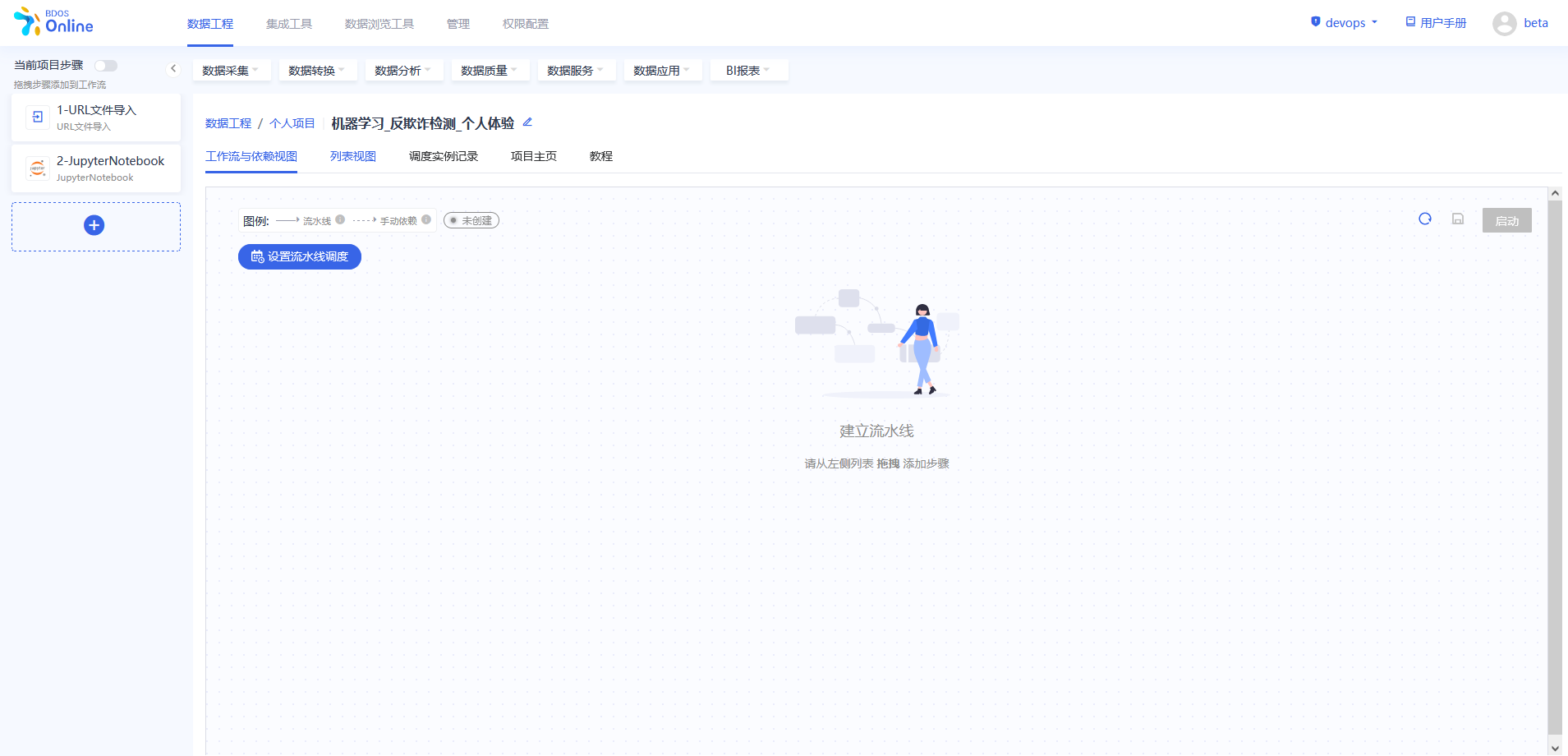
添加完成后,对步骤进行修改名称,以区分,可以参照下图进行修改。
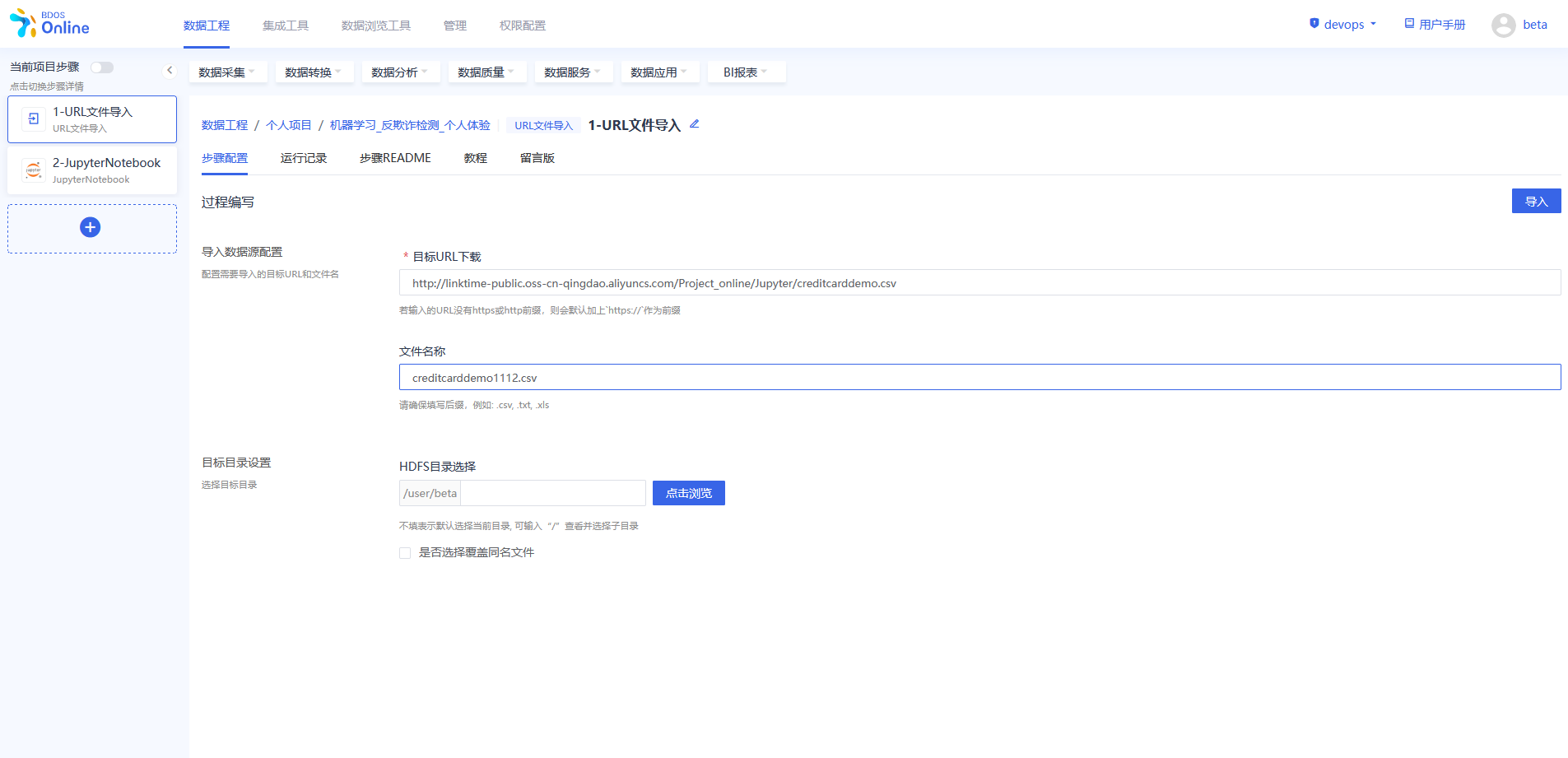
步骤三:URL 文件导入
在BDOS Online大数据平台,用户可通过URL文件导入,导入到系统的HDFS。
Web下载路径:http://linktime-public.oss-cn-qingdao.aliyuncs.com/Project_online/Jupyter/creditcarddemo.csv
文件名称:xxx.csv(用户选填,不填则默认为url链接包含的文件名,用户也可参照示例进行名称自定义并带上文件后缀)
HDFS目录选择:保持默认
点击导入,导入完成后可以在运行记录中查看结果。
步骤四:数据处理与导出
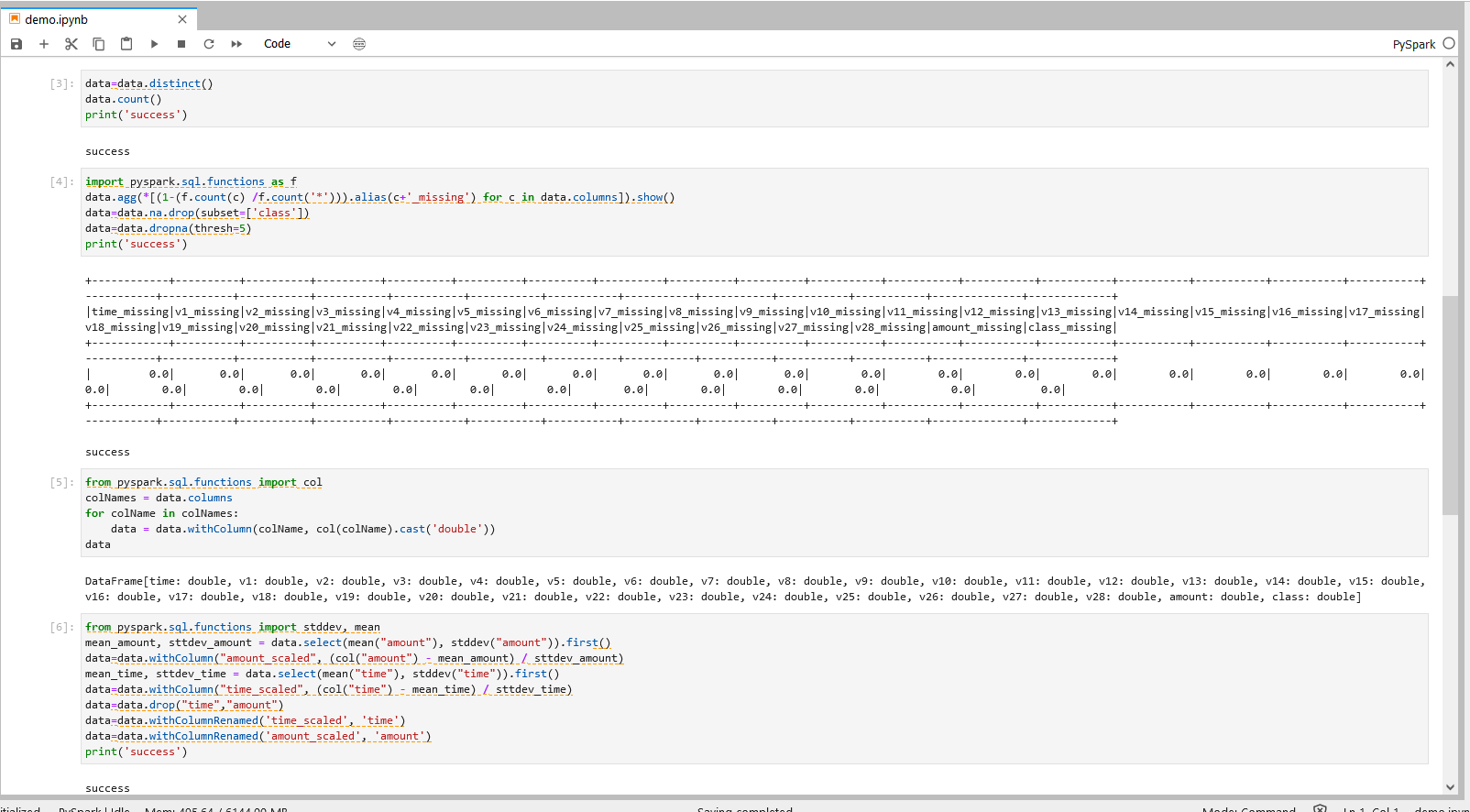
按照图中的位置,进入jupyter,新建Pyspark,在Pyspark程序步骤对银行demo数据进行处理并导出。
选择pyspark notebook
操作一
注:
个人项(xxx/xxx为user/xxx)1.替换user/xxx的xxx为当前登录用户名 2.若URL文件导入步骤填入自定义名称,则替换csv为实际csv表名,否则不用修改csv表名
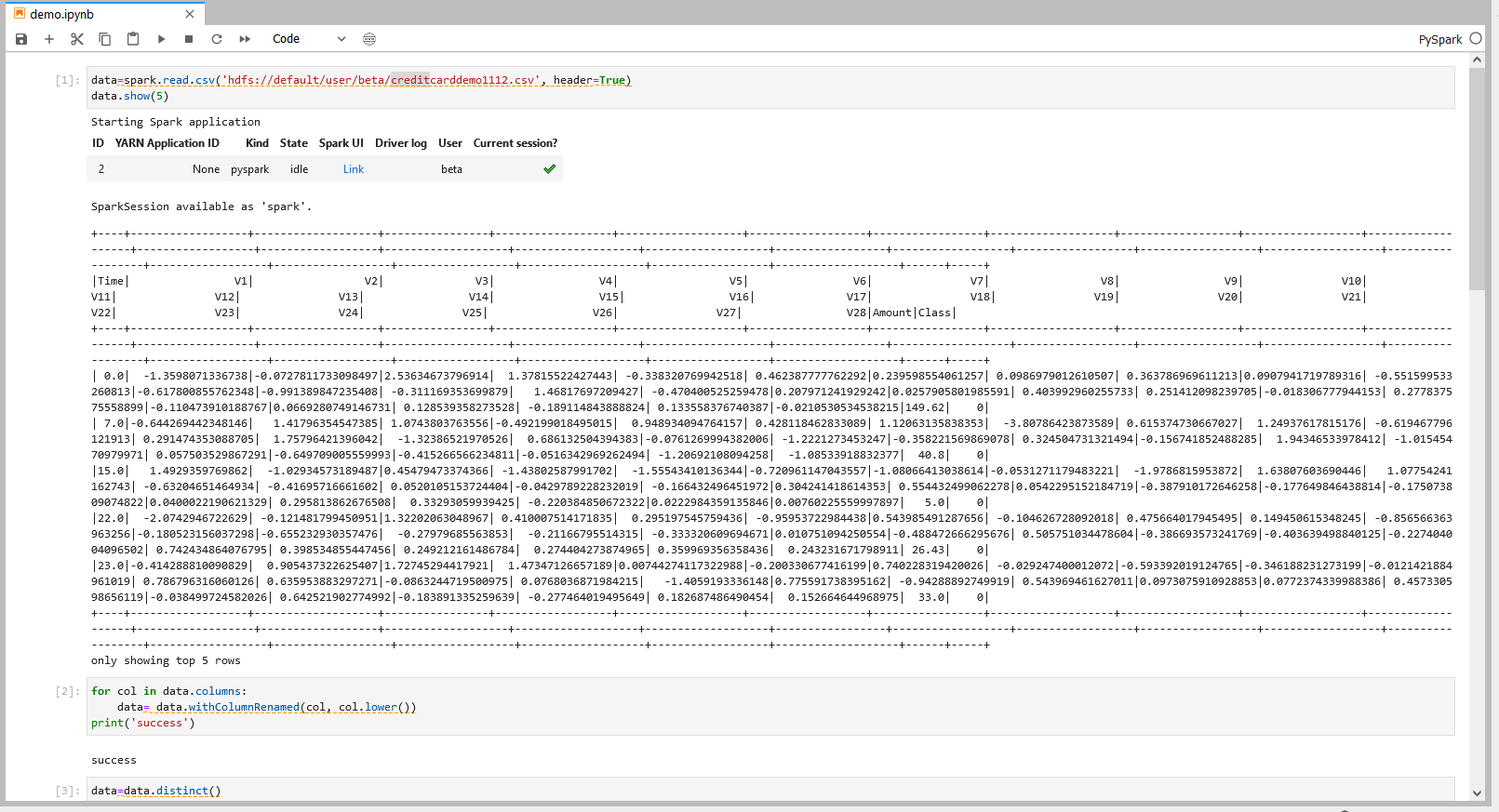
data=spark.read.csv('hdfs://default/xxx/xxx/creditcarddemo.csv', header=True)
data.show(5) 操作一说明
1.以PySpark的格式读取导入到Hive目标表的实验数据到PySpark dataframe
2.使用function data.show() 将dataframe 的内容进行展示。如:通过在show()中填写数字,选择需要展示的行数,show(1),即展示数据集第1行,不填则默认展示前20行。
操作二
for col in data.columns:
data= data.withColumnRenamed(col, col.lower())
print('success')
操作二说明
将dataframe中的所有列名全转化为小写字母形式
操作三
data=data.distinct()
data.count()
print('success')
操作三说明
1.处理重复数据,如:使用function data.distinct() 对完全相同的行进行去重。 2.数据统计,如:使用function data.count() 统计数据集行数。
操作四
import pyspark.sql.functions as f
data.agg(*[(1-(f.count(c) /f.count('*'))).alias(c+'_missing') for c in data.columns]).show()
data=data.na.drop(subset=['class'])
data=data.dropna(thresh=5)
print('success')
操作四说明
1.打印每列数据的空缺比。
2.删除Class项结果项空缺的数据,如:(data.na.drop(subset=[‘class’])),对“class”项缺失的行进行删除。
3.删除非Class项空缺数>5的行数据,如对 thresh 进行参数设置来控制判断空缺项的阈值。
操作五
from pyspark.sql.functions import col
colNames = data.columns
for colName in colNames:
data = data.withColumn(colName, col(colName).cast('double'))
data
操作五说明
对数据类型进行转换,将string类型数据转换成double类型数据。
操作六
from pyspark.sql.functions import stddev, mean
mean_amount, sttdev_amount = data.select(mean("amount"), stddev("amount")).first()
data=data.withColumn("amount_scaled", (col("amount") - mean_amount) / sttdev_amount)
mean_time, sttdev_time = data.select(mean("time"), stddev("time")).first()
data=data.withColumn("time_scaled", (col("time") - mean_time) / sttdev_time)
data=data.drop("time","amount")
data=data.withColumnRenamed('time_scaled', 'time')
data=data.withColumnRenamed('amount_scaled', 'amount')
print('success')
操作六说明
计算某列数据的平均值和方差,根据平均值和方差将该列数据进行标准化,即把该列数据的值减去平均值后再除以方差。
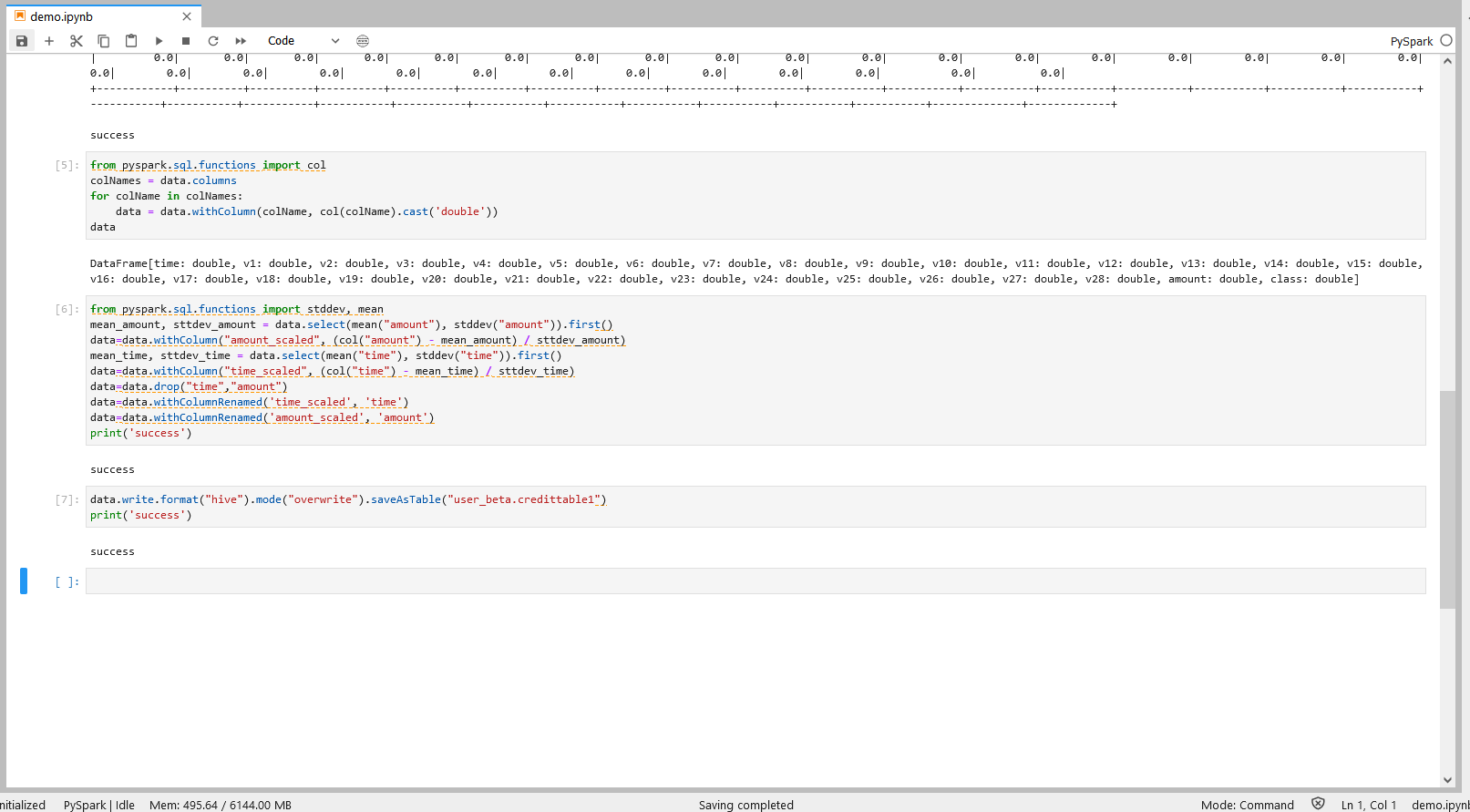
操作七
注:
机构项(xxx_xxx为org_xxx)1.替换org_xxx的xxx为机构名称 2.table1为Hive目标表名,用户可自定义目标表名。
个人项(xxx_xxx为user_xxx)1.替换user_xxx的xxx为当前登录用户名 2.table1为Hive目标表名,用户可自定义目标表名。
data.write.format("hive").mode("overwrite").saveAsTable("xxx_xxx.table1")
print('success') 操作七说明
将结果数据导出到目标Hive库表
以上操作和结果可参考下图。
步骤五:分类模型
在Pyspark程序中运用五种不同的机器学习分类模型,并对每个模型的预测结果进行评估。
继续上一步的PySpark notebook,进行后续操作。
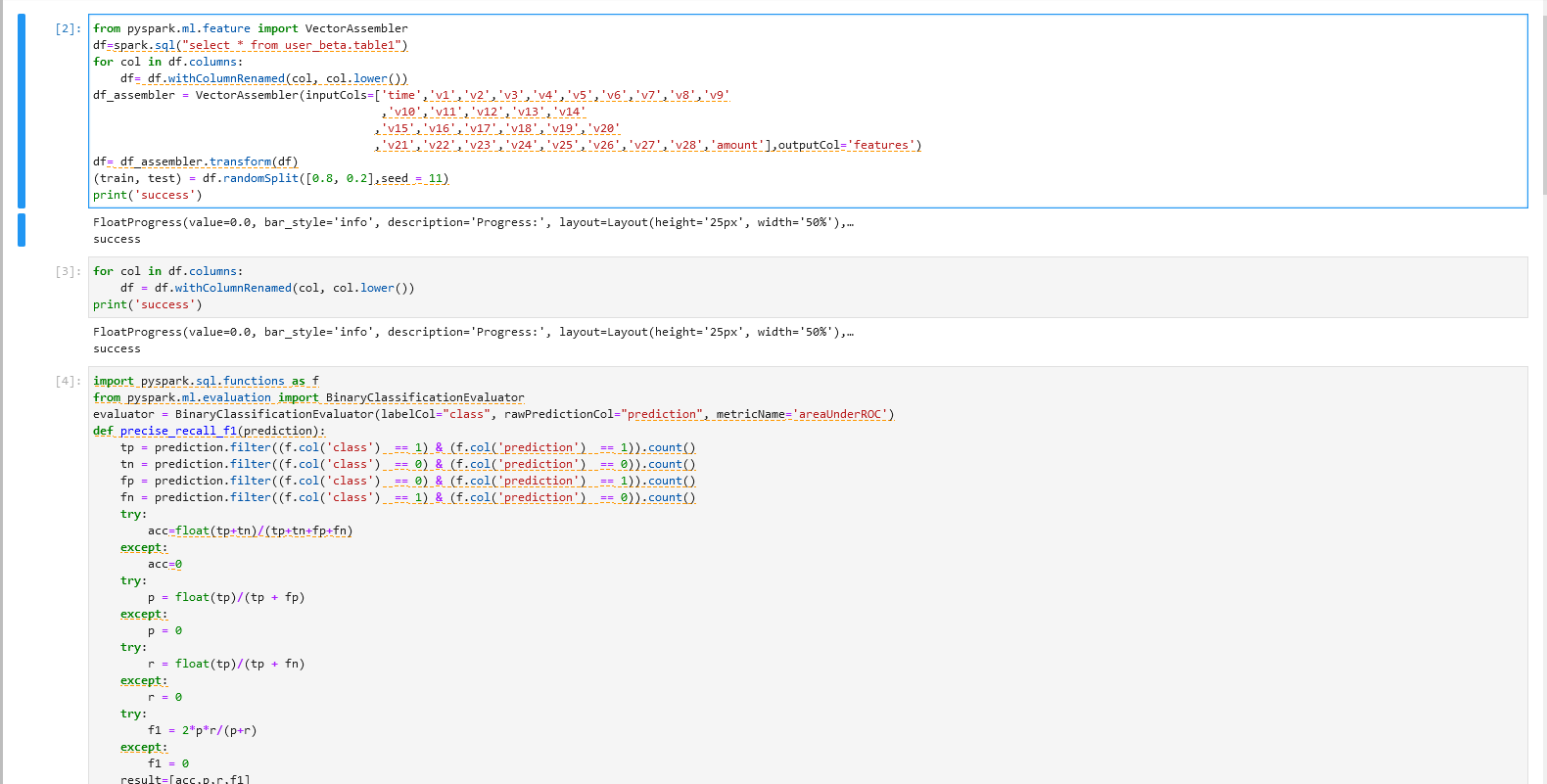
操作一
注:
机构项(xxx_xxx为org_xxx)1.替换org_xxx的xxx为机构名称 2.table1为Hive目标表名,用户可自定义目标表名。个人项(xxx_xxx为user_xxx)1.替换user_xxx的xxx为当前登录用户名 2.table1为Hive目标表名,用户可自定义目标表名。
from pyspark.ml.feature import VectorAssembler
df=spark.sql("select * from xxx_xxx.table1")
for col in df.columns:
df= df.withColumnRenamed(col, col.lower())
df_assembler = VectorAssembler(inputCols=['time','v1','v2','v3','v4','v5','v6','v7','v8','v9'
,'v10','v11','v12','v13','v14'
,'v15','v16','v17','v18','v19','v20'
,'v21','v22','v23','v24','v25','v26','v27','v28','amount'],outputCol='features')
df= df_assembler.transform(df)
(train, test) = df.randomSplit([0.8, 0.2],seed = 11)
print('success')
操作一说明 – 数据转换与导入
导入上一个步骤的输出到Jupyter,并将给定的多列转换为一个向量列。
操作二
for col in df.columns:
df = df.withColumnRenamed(col, col.lower())
print('success')
操作二说明
将dataframe中的所有列名全转化为小写字母形式
操作三
import pyspark.sql.functions as f
from pyspark.ml.evaluation import BinaryClassificationEvaluator
evaluator = BinaryClassificationEvaluator(labelCol="class", rawPredictionCol="prediction", metricName='areaUnderROC')
def precise_recall_f1(prediction):
tp = prediction.filter((f.col('class') == 1) & (f.col('prediction') == 1)).count()
tn = prediction.filter((f.col('class') == 0) & (f.col('prediction') == 0)).count()
fp = prediction.filter((f.col('class') == 0) & (f.col('prediction') == 1)).count()
fn = prediction.filter((f.col('class') == 1) & (f.col('prediction') == 0)).count()
try:
acc=float(tp+tn)/(tp+tn+fp+fn)
except:
acc=0
try:
p = float(tp)/(tp + fp)
except:
p = 0
try:
r = float(tp)/(tp + fn)
except:
r = 0
try:
f1 = 2*p*r/(p+r)
except:
f1 = 0
result=[acc,p,r,f1]
return result
print('success')
操作三说明 – 评估方程
1.运用模型BinaryClassificationEvaluator,评估每个分类模型预测结果的AUC(正确率度);
2.对于二分类的数据集,对accuracy,precision,recall,f1_score进行评估;
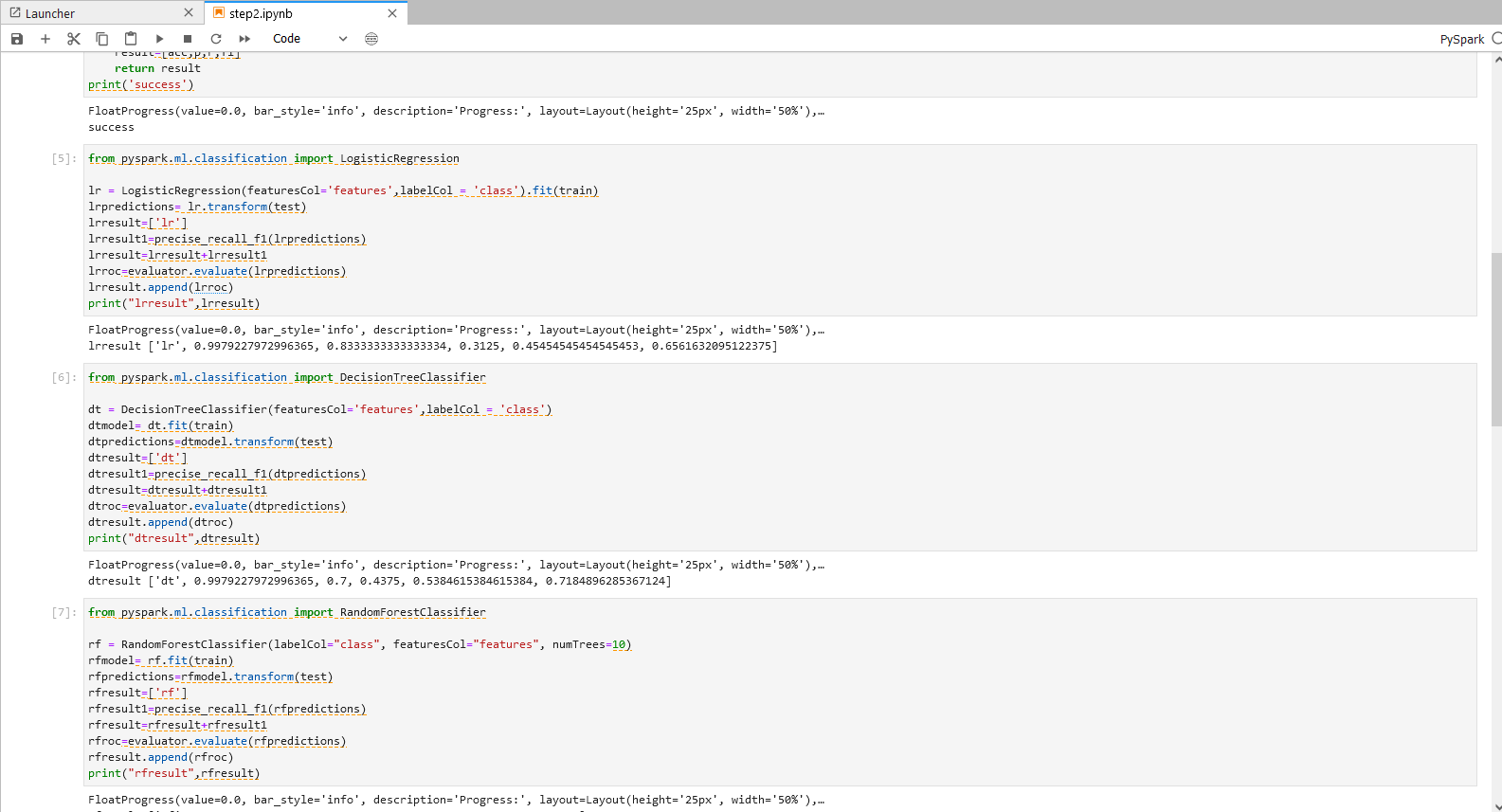
操作四
逻辑回归
from pyspark.ml.classification import LogisticRegression
lr = LogisticRegression(featuresCol='features',labelCol = 'class').fit(train)
lrpredictions= lr.transform(test)
lrresult=['lr']
lrresult1=precise_recall_f1(lrpredictions)
lrresult=lrresult+lrresult1
lrroc=evaluator.evaluate(lrpredictions)
lrresult.append(lrroc)
print("lrresult",lrresult)
决策树分类
from pyspark.ml.classification import DecisionTreeClassifier
dt = DecisionTreeClassifier(featuresCol='features',labelCol = 'class')
dtmodel= dt.fit(train)
dtpredictions=dtmodel.transform(test)
dtresult=['dt']
dtresult1=precise_recall_f1(dtpredictions)
dtresult=dtresult+dtresult1
dtroc=evaluator.evaluate(dtpredictions)
dtresult.append(dtroc)
print("dtresult",dtresult)
随机森林分类
from pyspark.ml.classification import RandomForestClassifier
rf = RandomForestClassifier(labelCol="class", featuresCol="features", numTrees=10)
rfmodel= rf.fit(train)
rfpredictions=rfmodel.transform(test)
rfresult=['rf']
rfresult1=precise_recall_f1(rfpredictions)
rfresult=rfresult+rfresult1
rfroc=evaluator.evaluate(rfpredictions)
rfresult.append(rfroc)
print("rfresult",rfresult)
梯度提升决策树分类
from pyspark.ml.classification import GBTClassifier
gbt = GBTClassifier(labelCol="class", featuresCol="features", maxIter=10)
gbtmodel=gbt.fit(train)
gbtpredictions=gbtmodel.transform(test)
gbtresult=['gbt']
gbtresult1=precise_recall_f1(gbtpredictions)
gbtresult=gbtresult+gbtresult1
gbtroc=evaluator.evaluate(gbtpredictions)
gbtresult.append(gbtroc)
print("gbtresult",gbtresult)
线性支持向量分类
from pyspark.ml.classification import LinearSVC
lsvc = LinearSVC(labelCol="class", featuresCol="features", maxIter=10, regParam=0.1)
lsvcModel = lsvc.fit(train)
lsvcpredictions=lsvcModel.transform(test)
lsvcresult=['lsvc']
lsvcresult1=precise_recall_f1(lsvcpredictions)
lsvcresult=lsvcresult+lsvcresult1
lsvcroc=evaluator.evaluate(lsvcpredictions)
lsvcresult.append(lsvcroc)
print("lsvcresult",lsvcresult)
操作四说明 – 分类模型
分别使用五类模型:逻辑回归,决策树分类,随机森林分类,梯度提升决策树分类,线性支持向量分类,对数据集进行拟合,完成预测,并将预测的评估结果打印。
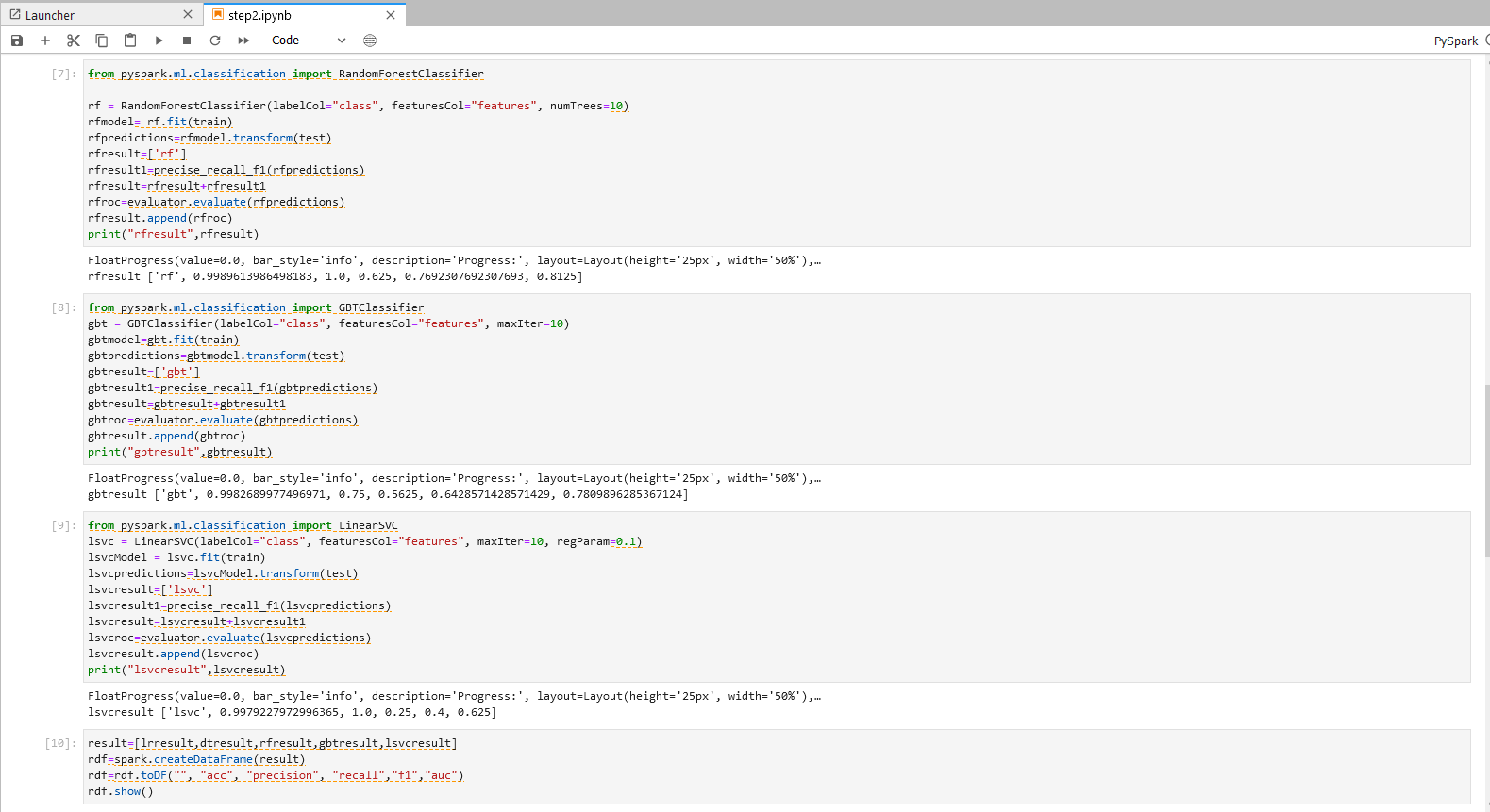
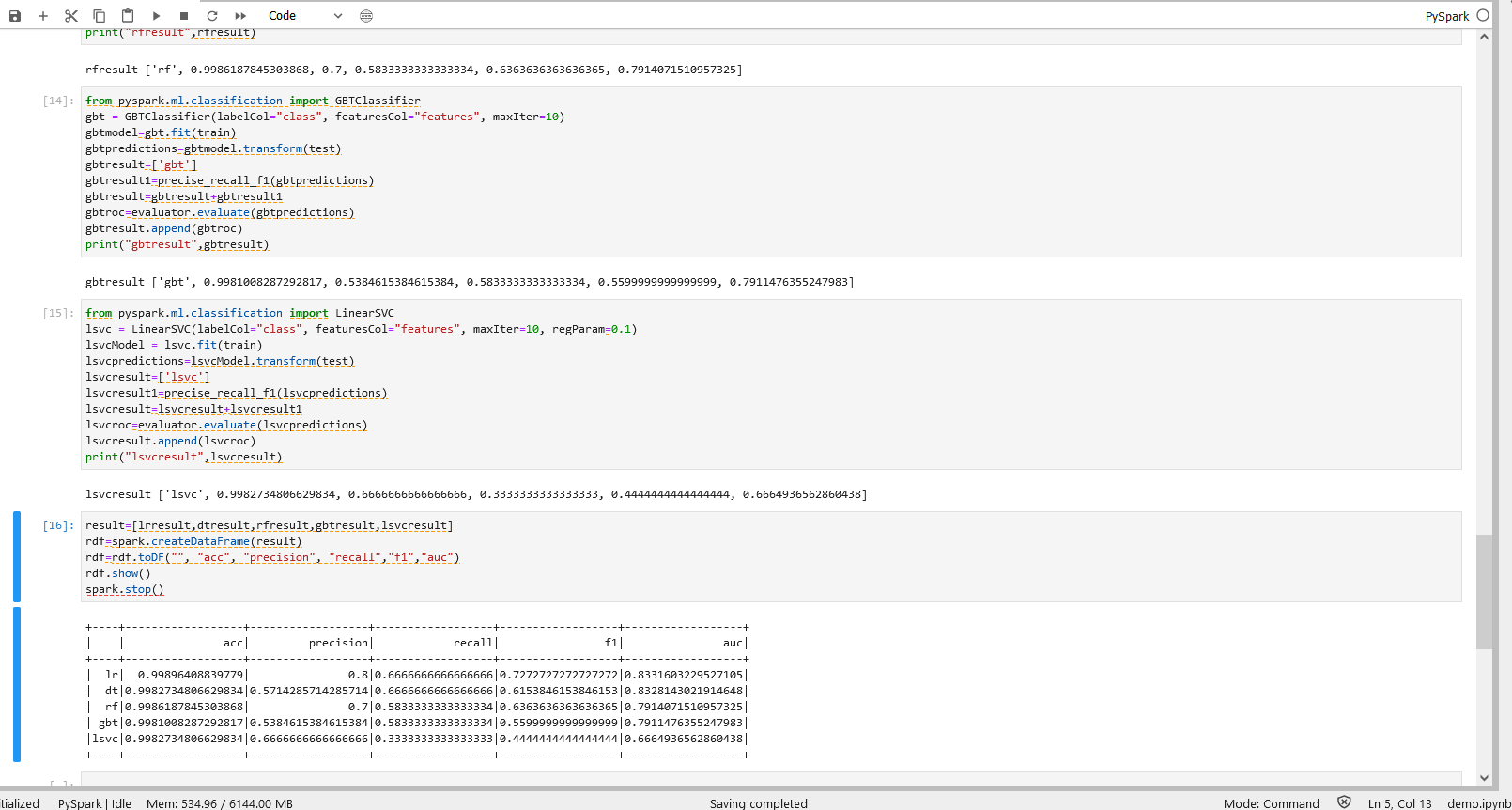
操作五
result=[lrresult,dtresult,rfresult,gbtresult,lsvcresult]
rdf=spark.createDataFrame(result)
rdf=rdf.toDF("", "acc", "precision", "recall","f1","auc")
rdf.show()
spark.stop()
操作五说明 – 评估表格
整合五个模型分别评估的计算结果
运行操作和结果可参考下图:
步骤六:GBT分类模型调参
继续在上一步的PySpark notebook中,进行后续操作。在Pyspark程序中针对GBT模型,测试不同的参数组合,最后将表现最优的模型以及该模型的预测结果导出。
操作一
注: 机构项(xxx_xxx为org_xxx) 1.替换org_xxx的xxx为机构名称 2.table1为Hive目标表名,用户可自定义目标表名。 个人项(xxx_xxx为user_xxx) 1.替换user_xxx的xxx为当前登录用户名 2.table1为Hive目标表名,用户可自定义目标表名。
from pyspark.ml.classification import GBTClassificationModel
from pyspark.ml.feature import VectorAssembler
df=spark.sql("select * from xxx_xxx.table1")
for col in df.columns:
df= df.withColumnRenamed(col, col.lower())
df_assembler = VectorAssembler(inputCols=['time','v1','v2','v3','v4','v5','v6','v7','v8','v9'
,'v10','v11','v12','v13','v14'
,'v15','v16','v17','v18','v19','v20'
,'v21','v22','v23','v24','v25','v26','v27','v28','amount'],outputCol='features')
df= df_assembler.transform(df)
df=df.withColumnRenamed('class', 'label')
(train, test) = df.randomSplit([0.8, 0.2],seed = 11)
print('success')
操作一说明 - 数据转换与导入
导入上一个步骤的输出到Jupyter,将给定的多列转换为一个向量列,并将数据分成测试集和训练集。
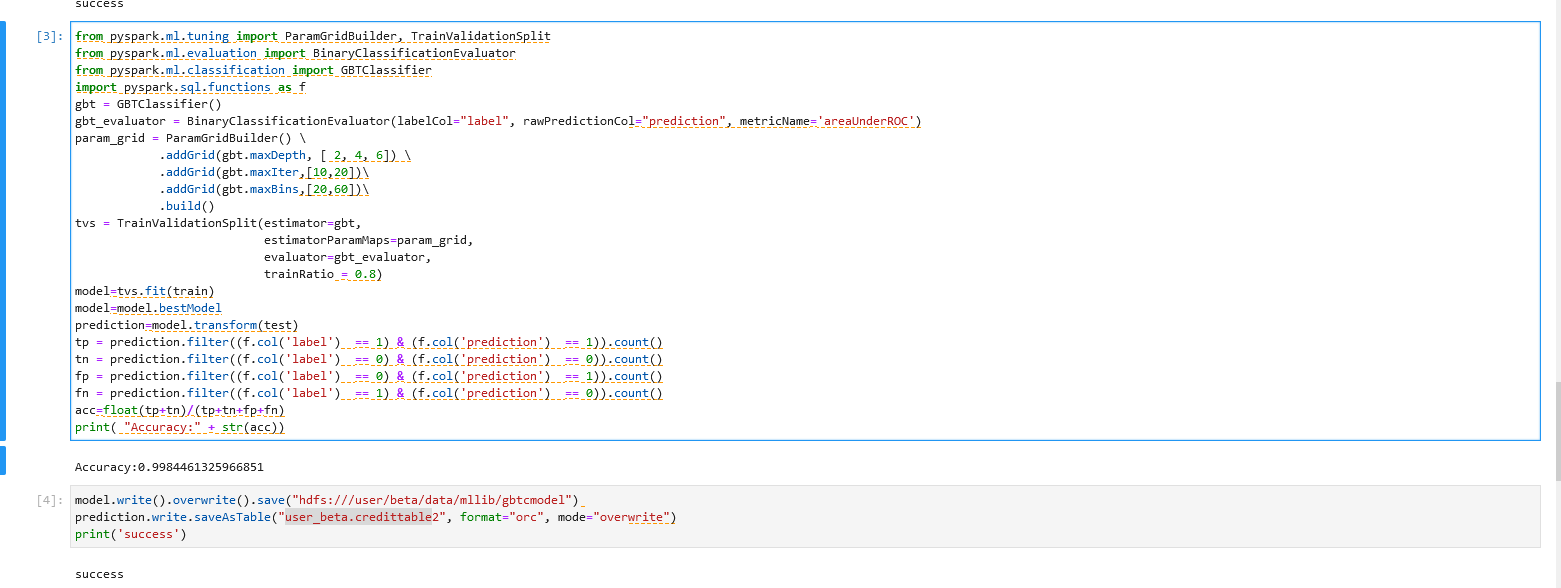
操作二
from pyspark.ml.tuning import ParamGridBuilder, TrainValidationSplit
from pyspark.ml.evaluation import BinaryClassificationEvaluator
from pyspark.ml.classification import GBTClassifier
import pyspark.sql.functions as f
gbt = GBTClassifier()
gbt_evaluator = BinaryClassificationEvaluator(labelCol="label", rawPredictionCol="prediction", metricName='areaUnderROC')
param_grid = ParamGridBuilder() \
.addGrid(gbt.maxDepth, [ 2, 4, 6]) \
.addGrid(gbt.maxIter,[10,20])\
.addGrid(gbt.maxBins,[20,60])\
.build()
tvs = TrainValidationSplit(estimator=gbt,
estimatorParamMaps=param_grid,
evaluator=gbt_evaluator,
trainRatio = 0.8)
model=tvs.fit(train)
model=model.bestModel
prediction=model.transform(test)
tp = prediction.filter((f.col('label') == 1) & (f.col('prediction') == 1)).count()
tn = prediction.filter((f.col('label') == 0) & (f.col('prediction') == 0)).count()
fp = prediction.filter((f.col('label') == 0) & (f.col('prediction') == 1)).count()
fn = prediction.filter((f.col('label') == 1) & (f.col('prediction') == 0)).count()
acc=float(tp+tn)/(tp+tn+fp+fn)
print( "Accuracy:" + str(acc))
操作二说明 – GBTC模型的调参与预测
运用TrainValidationSplit(TVS)来进行参数调优。运用param_grid方程来定义TVS检测的参数,对12种参数组合模型进行测试。
使用最优检测模型对数据进行拟合并输出最佳预测结果。
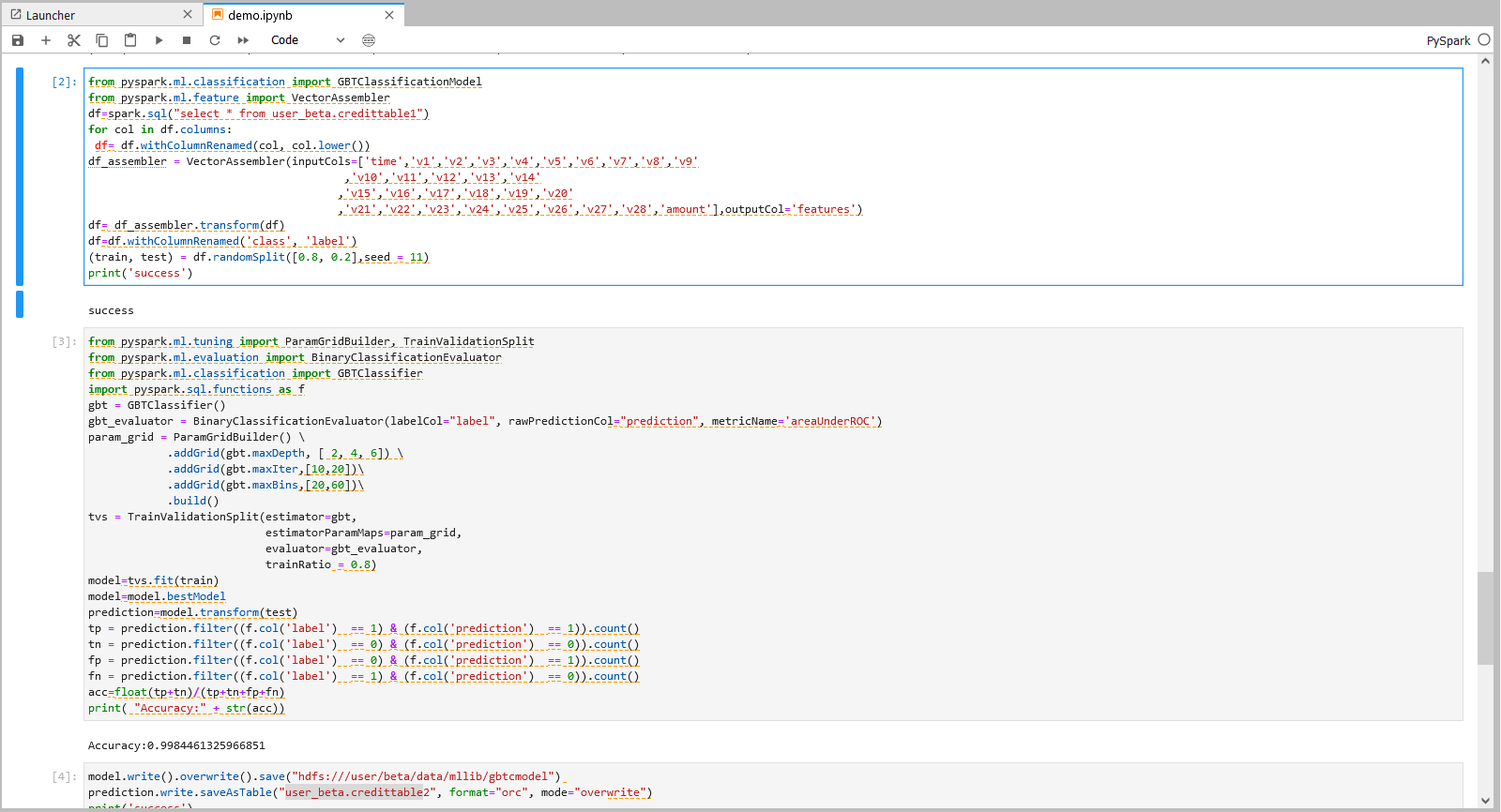
操作三
注:机构项目时: 1.”hdfs:///xxx/xxx/data/mllib/gbtcmodel” 为
hdfs:///org/xxx/data/mllib/gbtcmodel,xxx替换为当前机构名。 2.”xxx_xxx.table2″为org_xxx,xxx替换为当前机构名,table2为Hive目标表名,用户可自定义目标表名。
个人项目时 1.”hdfs:///xxx/xxx/data/mllib/gbtcmodel” 为
hdfs:///user/xxx/data/mllib/gbtcmodel,xxx替换为当前登录用户名。 2.”xxx_xxx.table2″为user_xxx,xxx替换为当前登录用户名,table2为Hive目标表名,用户可自定义目标表名。
model.write().overwrite().save("hdfs:///xxx/xxx/data/mllib/gbtcmodel")
prediction.write.saveAsTable("xxx_xxx.table2", format="orc", mode="overwrite")
print('success')
spark.stop() 操作三说明 – 结果数据存储
将训练完成的最佳模型存入HDFS以便后续使用。
将最佳预测结果存入hive表中。
具体操作和结果可以参考下图:
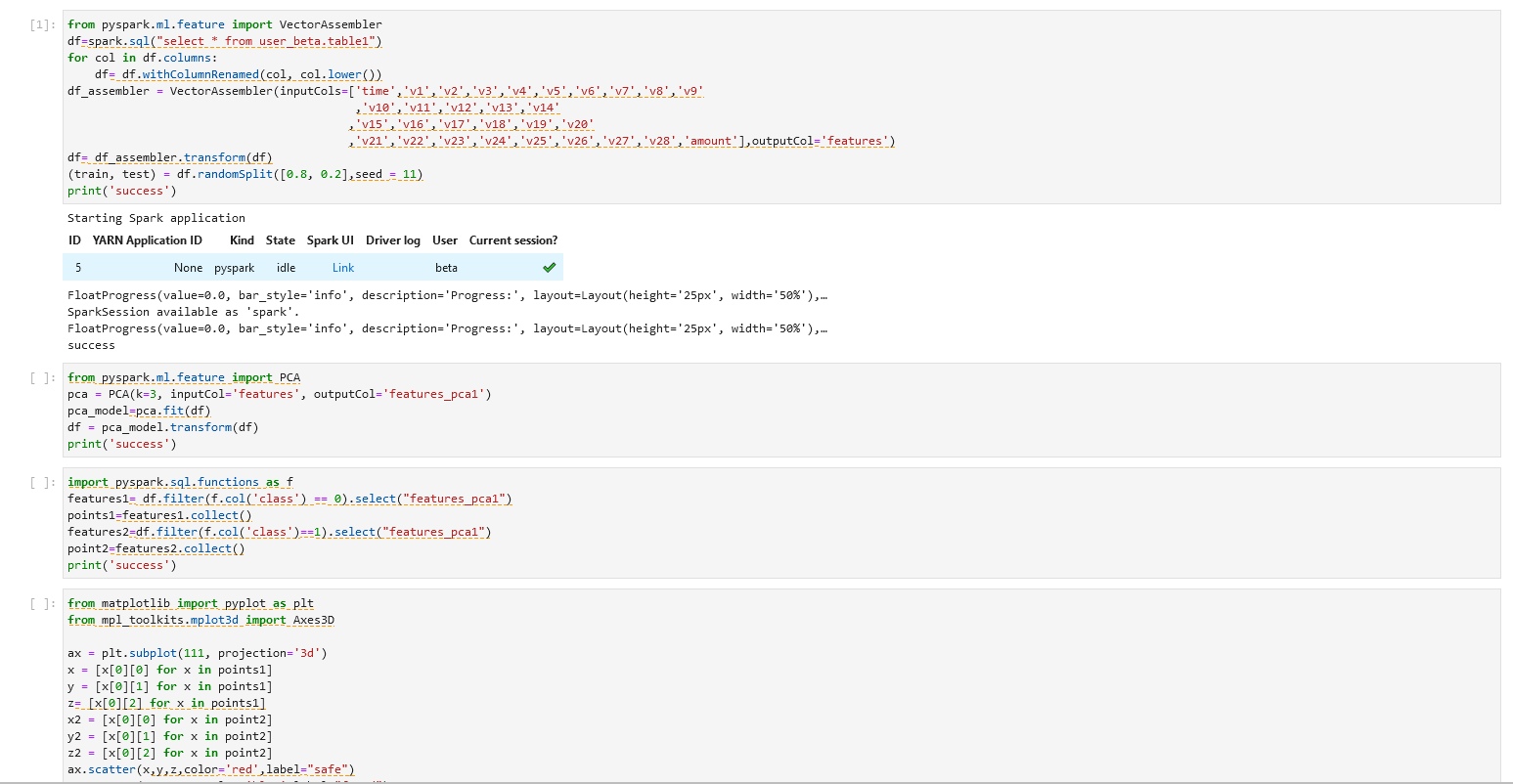
步骤七:PCA降维视觉化
继续在上一步的PySpark notebook中,进行后续操作。在Pyspark程序中运用PCA对于特征数据进行降维处理,使多维数据降至三维,并将三维数据用图像的方式呈现。
操作一
注:
机构项(xxx_xxx为org_xxx)1.替换org_xxx的xxx为机构名称 2.table1为Hive目标表名,用户可自定义目标表名。个人项(xxx_xxx为user_xxx)1.替换user_xxx的xxx为当前登录用户名 2.table1为Hive目标表名,用户可自定义目标表名。
from pyspark.ml.feature import VectorAssembler
df=spark.sql("select * from xxx_xxx.table1")
for col in df.columns:
df= df.withColumnRenamed(col, col.lower())
df_assembler = VectorAssembler(inputCols=['time','v1','v2','v3','v4','v5','v6','v7','v8','v9'
,'v10','v11','v12','v13','v14'
,'v15','v16','v17','v18','v19','v20'
,'v21','v22','v23','v24','v25','v26','v27','v28','amount'],outputCol='features')
df= df_assembler.transform(df)
(train, test) = df.randomSplit([0.8, 0.2],seed = 11)
print('success')
步骤一说明 - 数据转换与导入
导入上一个步骤的输出到Jupyter,将给定的多列转换为一个向量列,并将数据分成测试集和训练集。
操作二
from pyspark.ml.feature import PCA
pca = PCA(k=3, inputCol='features', outputCol='features_pca1')
pca_model=pca.fit(df)
df = pca_model.transform(df)
print('success')
步骤二说明 - 主成分分析(PCA)
定义PCA将特征向量转换为长度为k的特征向量。
步骤三操作
import pyspark.sql.functions as f
features1= df.filter(f.col('class') == 0).select("features_pca1")
points1=features1.collect()
features2=df.filter(f.col('class')==1).select("features_pca1")
point2=features2.collect()
print('success')
步骤三说明 - 数据筛选
通过对class的筛选,选出诈骗类数据和非诈骗类数据,并将PCA转化后的特征vector进行保存。
步骤四操作
from matplotlib import pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
ax = plt.subplot(111, projection='3d')
x = [x[0][0] for x in points1]
y = [x[0][1] for x in points1]
z= [x[0][2] for x in points1]
x2 = [x[0][0] for x in point2]
y2 = [x[0][1] for x in point2]
z2 = [x[0][2] for x in point2]
ax.scatter(x,y,z,color='red',label="safe")
ax.scatter(x2,y2,z2,color='blue',label="fraud")
ax.set_zlabel('Z')
ax.set_ylabel('Y')
ax.set_xlabel('X')
plt.show()
print('success')
%matplot plt
spark.stop()
步骤四说明 - 绘制三维图像
将PCA转化后的长度为3的vector看做一个点的x,y,z坐标,并绘制成一个三维图像进行展示。
具体可以参照下图。
备注:建议完成整个步骤后将该项工程暂停,可参考下图。

留言
评论
暂时还没有一条评论.