数据流水线在数据分析中的实践示例 | 第九期图文直播文字回放

3月31日晚,智领云第九次社群图文技术直播如约而至。本次直播由智领云高级研发经理 Mike为大家带来了《数据流水线在数据分析中的实践示例》的主题分享,其中主要内容包括:可体验、实践的数据流水线;相关数据流水线解析;基于BDOS实现数据流水线。
最近几期,我的同事们分享了BDOS的核心调度的设计以及基于核心调度数仓建设实践。相信很多朋友,尤其是开始接触数据驱动、大数据分析、对这方面有强烈业务需求的朋友都非常想了解如何能够建设可分析、可应用的数据流水线,并希望能够通过建设流水线的过程“近距离”的熟悉了解相应的开源数据组件以及我们的BDOS对开源数据组件进行容器化及统一安全认证改造后所提供的快速搭建自动化数据流水线的产品功能。 所谓数据流水线,就是从原始数据到最终数据能力(如报表、大屏、数据服务)的整个转换流程和管理系统。自动化流水线则是对数据流水线的自动化实现,能够让数据按照需求自动流转,为上层的业务分析使用的数据提供基础准备。
可体验、实践的数据流水线
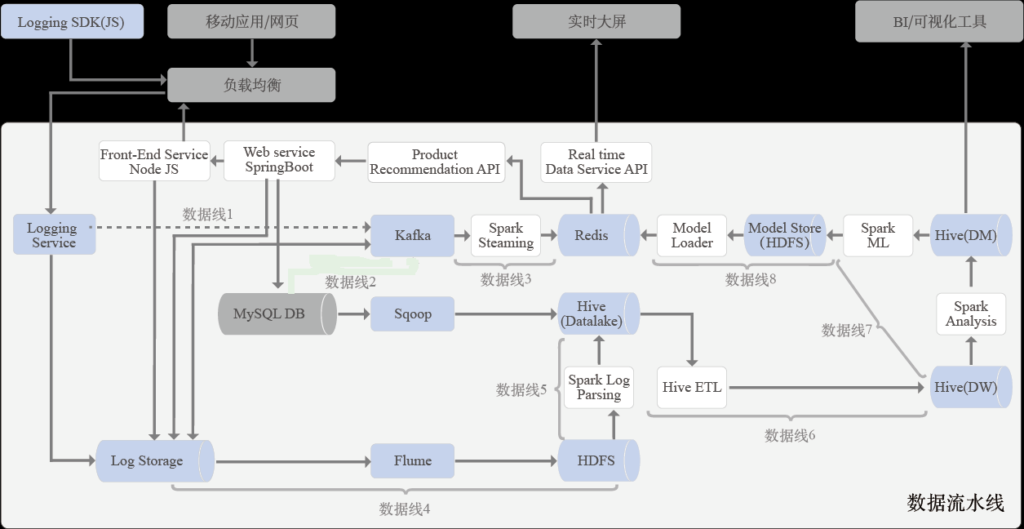
上图这组可实操、可应用的数据流水线是以一个电商平台和销售实时统计情况大屏为应用背景的数据流水线。用户可以通过电商平台的网页进行商品的详情查看、下单购买、选择支付方式、并对商品进行打分评价。用户在电商网页上的所有操作行为数据都会被记录,比如用户浏览情况及时长、购买情况、使用的浏览方式、查看的时间等,通过对这些数据的一系列采集分析后,进行基于用户行为分析的用户画像和商品推荐。
选择这样一个抽象出来的案例来分享数据流水线的构建过程,主要是因为此案例应用背景容易理解,而且其中的流水线会涉及到Sqoop、Hive、Hdfs、Spark、Kafka、Flume等一系列大数据的平台和组件的使用。当然,由于篇幅和时间的限制,本期主要聚焦其中的几组流水线,至于如何构建示例中的电商平台和销售实时统计情况大屏的过程不在本次分享的范围内。
相关数据流水线解析
介绍完流水线产生的应用背景后,我们还要再次看一下这组流水线,本部分会对流水线进行一个解释说明。用户在电商平台上的订单交易、打分详情、商品信息及区域门店信息等数据,通过后台服务(Web Service)使用Mysql进行读写的完成,在电商平台页面上显示商品和相关数据,也会记录订单打分等数据在Mysql中;电商平台还可以通过Redis来提供用户个性化推荐商品的服务;销售情况大屏主要使用Redis实时读取当前销售情况的各种数据。
电商平台中嵌入的用户行为追踪代码会将用户在平台中的浏览和购买以及点击行为数据实时发送给日志服务并存储在日志文件中,同时日志服务会将用户的各类动作信息写入Kafka,供流式数据处理的需求使用。

下面我们具体说明一下各个数据线的作用和功能:
- 数据线1:通过发布自定义应用服务(LogService),将在线商城网站页面中将嵌入的用户行为追踪包(Logging SDK(js))追踪到的各种用户行为数据(停留、点击、购买、刷新等一系列行为)实时发送到后台的 Logging Service服务上,该服务会将访问、刷新、购买、打分、停留的所有记录到行为日志外,还会将购买信息实时发送到kafka Topic中,供后续的流式数据线使用。
- 数据线2:通过Sqoop,将MySQL中的订单数据、用户数据、商品数据等相关数据同步到Hive数据湖中。
- 数据线3:通过SparkStreaming将Kafka中用户购买行为的Topic实时数据进行解析处理,把有关实时销售情况的数据进行解析提取,并结合Redis进行一定的汇总,供销售情况大屏使用。
- 数据线4:通过Flume读取用户行为日志文件,将后台日志数据通过 Flume 进行采集,并通过Kafka Connector将数据批量存储到HDFS的指定目录中(既可以做分析也可以对所有日志进行备份)。
- 数据线5:通过Spark的自定义程序对来HDFS中的用户日志数据进行解析,并按照事件类型存储到Hive数据湖中。
- 数据线6:通过Hive ETL工作流,对Hive数据湖中的数据进行加工、汇总、转换处理后并存放在Hive数据仓库中。
- 数据线7:通过Spark自定义分析作业,对来自Hive数据仓库中的数据进行分析处理完成用户画像,并结合相关订单数据、点击数据、停留时长数据等通过Spark机器学习作业,进行线下模型训练,并完成商品推荐(这个示例进行完计算后会将推荐商品的结果存入Redis中)。
- 数据线8:将商品推荐模型存储到HDFS中,并通过在线推荐服务动态加载该模型,进行在线推荐。
根据上面的解释,相信大家应该能够看到,这组数据线所形成的数据流水线涉及到了多个大数据组件以及各自所要实现的业务目标。下面我们将基于BDOS平台进行该组数据流水线的设计和实现。
基于BDOS实现数据流水线
BDOS的架构和基本功能在前面几期的直播中都有过介绍,这里将不再赘述,仅对具体的使用过程进行简要说明。在具体实现中,会根据业务需要,把各个数据线形成不同类型的数据流水线,有流式数据流水线、有批量数据流水线;有单个数据处理作业形成的流水线,也有多个数据处理作业形成的有强依赖关系的数据流水线。
3.1、单个数据作业形成的流水线
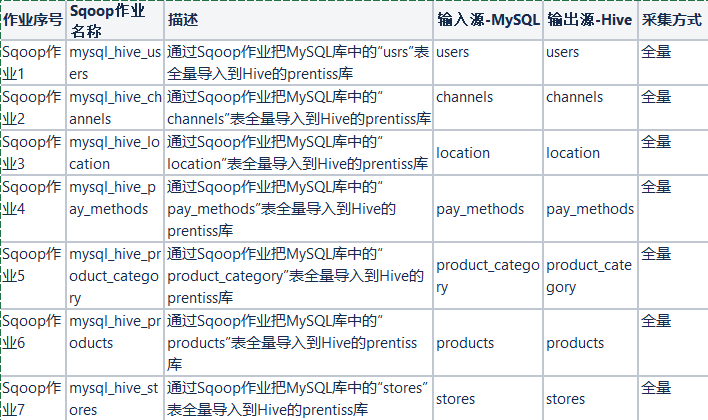
第二部分中的数据线2(通过Sqoop,将MySQL中的订单数据、用户数据、商品数据等相关数据同步到Hive数据湖中),有多个相关数据处理作业都构成了这类流水线,它们相互独立且同其它作业之间没有依赖与被依赖关系。
具体实现方式就是使用BDOS中的采集作业进行新的采集作业创建,过程如下(以一个数据表的处理为例),按照如下方式进行配置,点击保存并运行,单个作业的流水线就会按照设定时间自动执行。

3.2、通过应用服务输入数据到Kafka中的相关数据线
第二部分中的数据线1(通过发布自定义应用服务(LogService),将在线商城网站页面中将嵌入的用户行为追踪包(Logging SDK(js))追踪到的用户购买信息实时发送到kafka Topic中),数据线4(通过Flume读取用户行为日志文件,将后台日志数据通过 Flume 进行采集,并通过Kafka Connector将数据批量存储到HDFS的指定目录中),都使用了Kafka。
数据线1是通过自己编写的应用服务把数据直接写入Kafka的topic中,这里不对自定义应用发布的过程做过多描述,只是重点说明在BDOS中,一旦写入Kafka的Topic中,就可以从Kafka的Topic界面中看到写入的数据,如下图所示,完全可以作为判断自定义应用执行正确与否的方式(数据直接可见)。

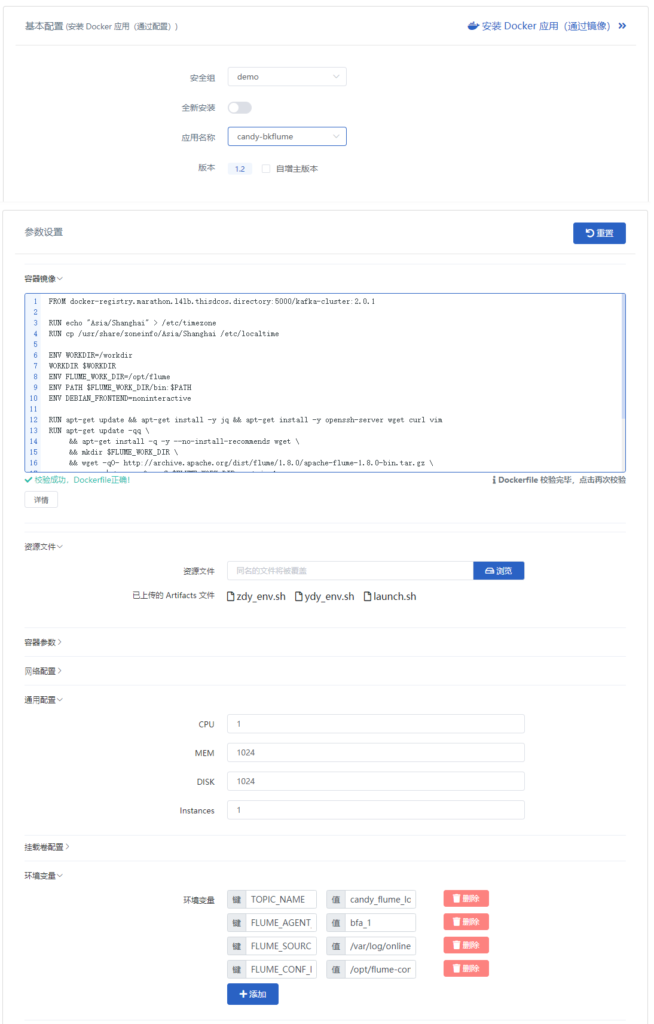
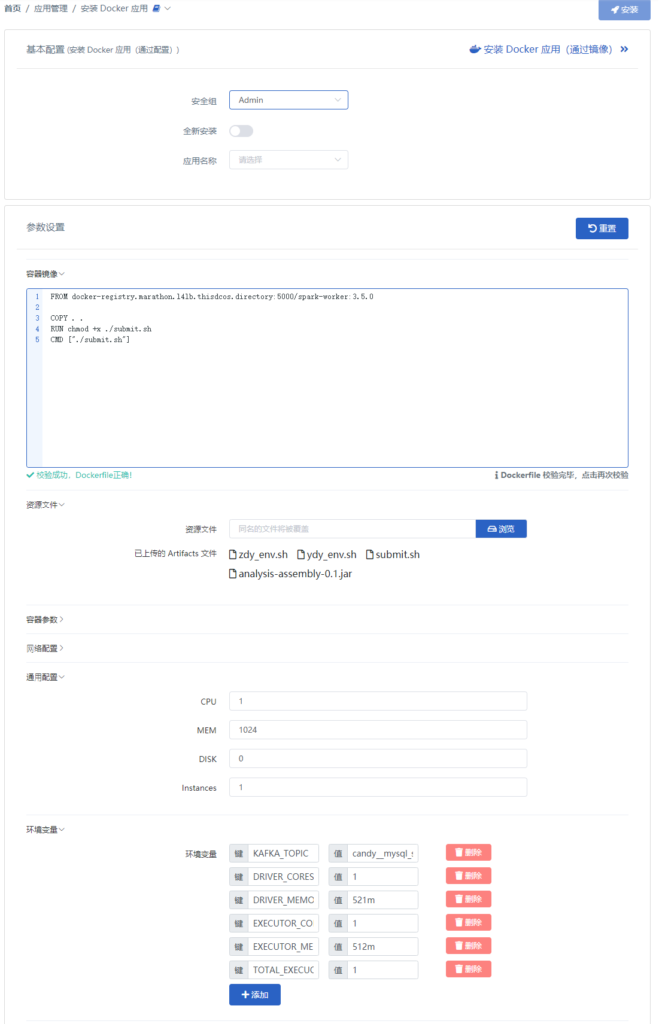
数据线4是通过发布自定义Flume应用实时读取日志文件到Kafka中并写入HDFS的指定目录中。这里稍微说明一下,Flume在本示例中是作为一个外部的自定义应用发布,目的就是来直接实时读取解析日志文件,并把日志文件中的数据通过配置写入Kafka中。Flume自定义应用的基本配置信息如下(非常简单,直接利用以有关的方式完成)
应用执行后在相应的kafka的topic中会看到数据(如同前面所示),并使用Connecotor将日志文件数据存入HDFS目录中,供后续处理使用。
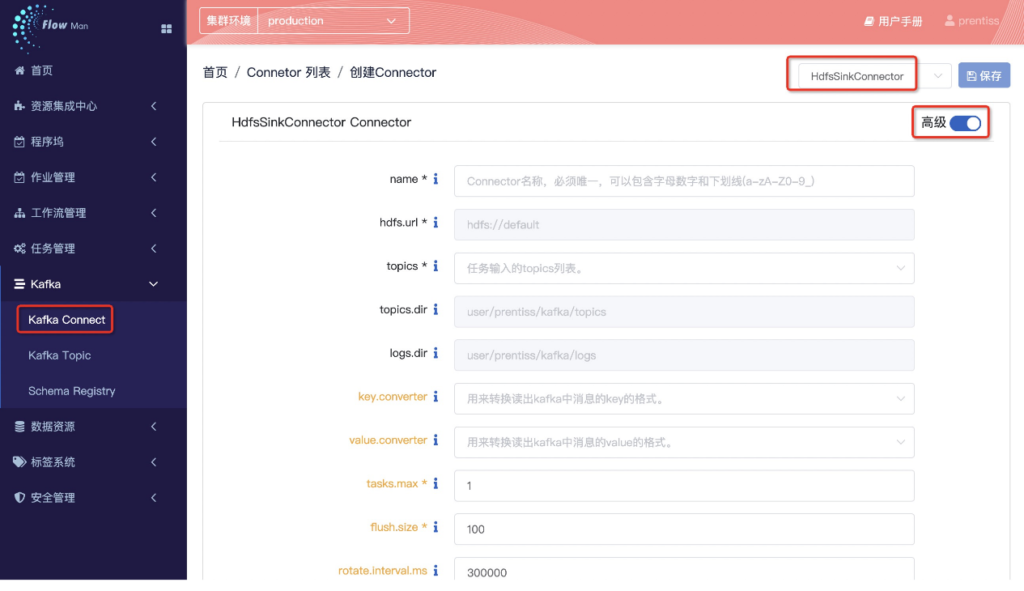
3.3、多个数据作业形成的批量流水线
第二部分中数据线2中的两个增量数据作业(增量更新销售数据、购买后打分数据的Mysql数据表中的数据采集到Hive数据湖中)

处理方式就是使用BDOS中的采集作业进行新的采集作业创建,过程如下(以一个数据表的处理为例),按照如下方式进行配置,点击保存。
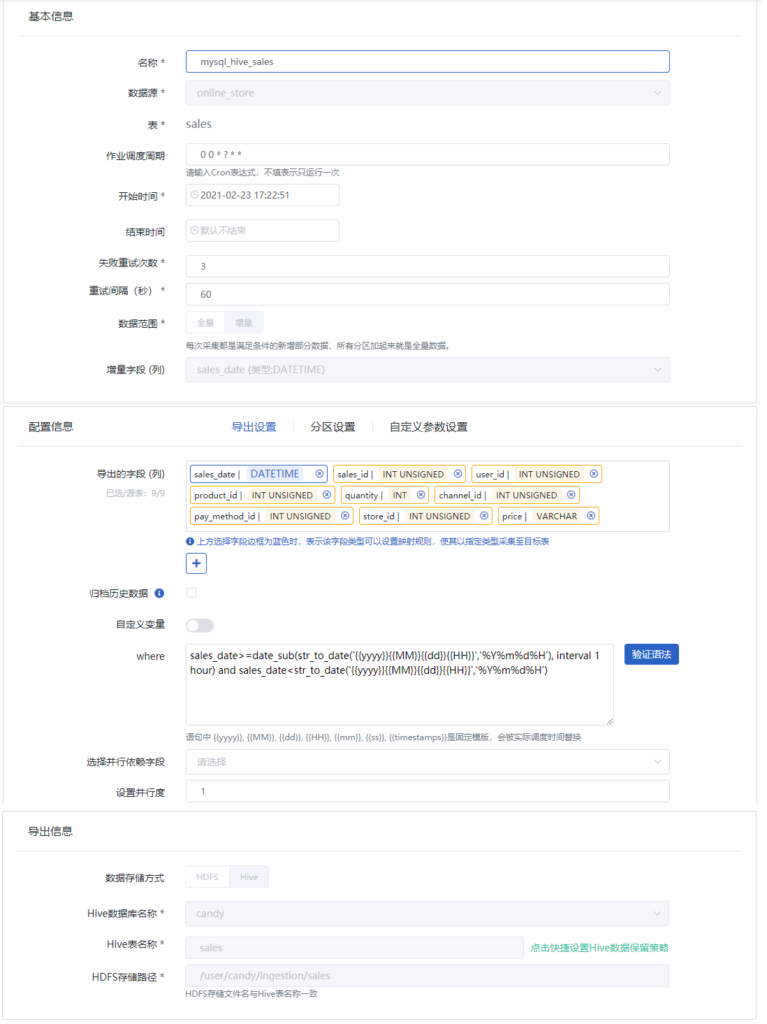
第二部分中的数据线5,需要通过Spark的自定义程序对经过上面步骤存储在HDFS中的用户行为日志数据进行解析,形成用户的行为数据和兴趣数据,并存储到Hive数据仓库中。

通过一个用户行为数据的处理过程为例。要在BDOS中新建一个Spark作业,作业填写内容如下,将分析程序提交,并设置运行需要的资源大小,该作业都会启动一个独立容器作为spark的driver驱动spark集群完成处理。
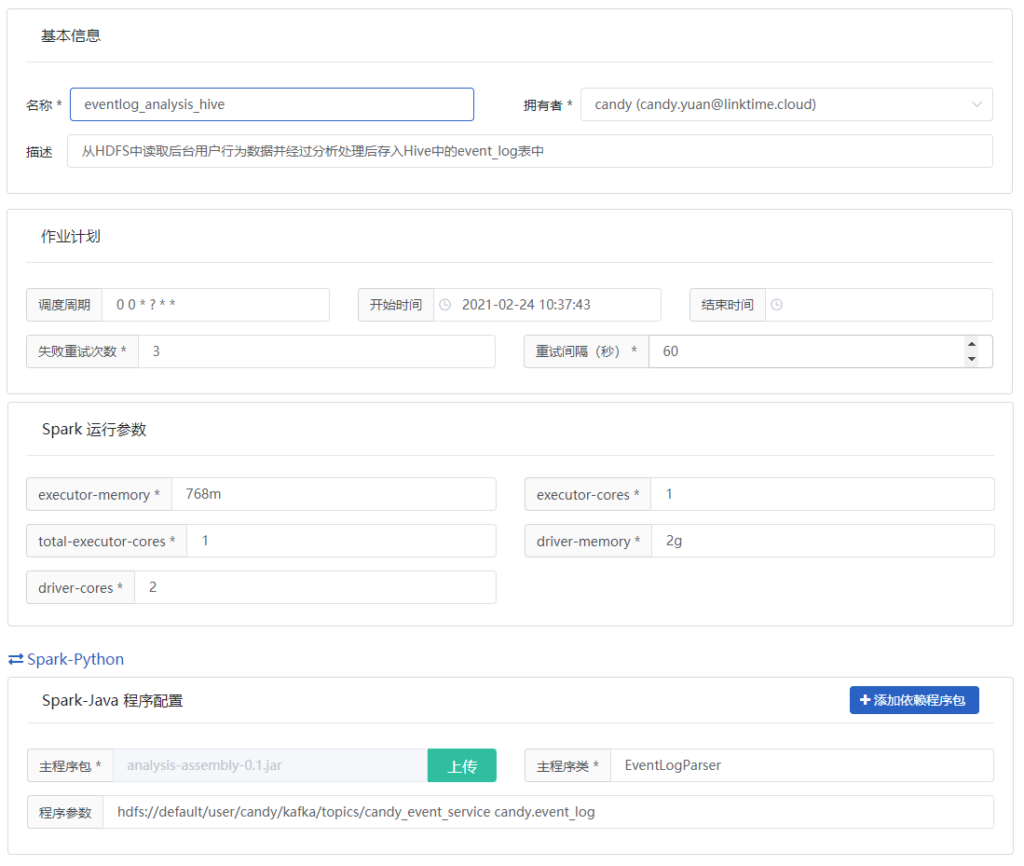
第二部分中的数据线6,需要通过Hive ETL工作流,对数据进行加工、汇总、转换处理后并放入Hive数据仓库中。该过程需要创建如下一系列的通过Hive的加工处理的独立处理作业,作业之间又有强关联性。

以统计每个用户每天每个店铺的访问及消费金额的数据的处理过程为例。要在BDOS中新建一个Hive作业,作业填写内容如下,将加工处理使用的hql语句在Hive作业中提交并保存。
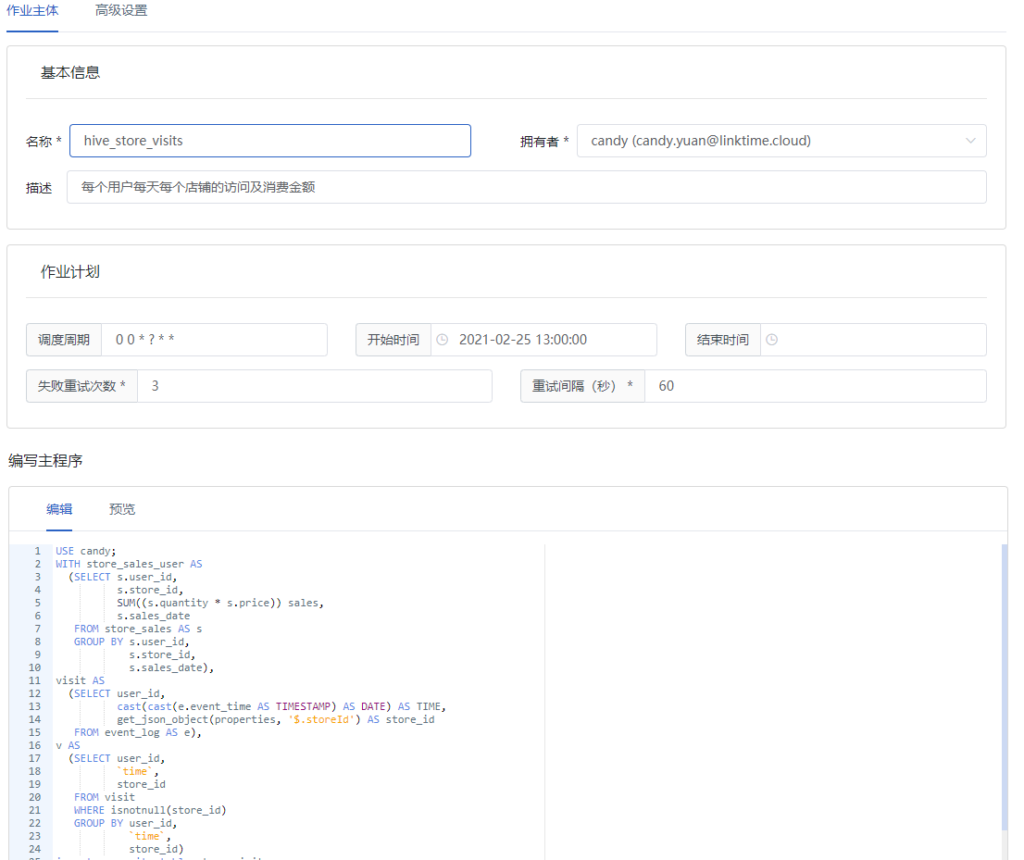
第二部分中的数据线7,需要通过Spark自定义分析作业,对Hive数据仓库中的数据进行分析处理,完成用户画像、用户兴趣分析,并结合相关订单数据、点击数据通过Spark机器学习作业,进行线下模型训练,并完成商品推荐。

以分析用户兴趣和对用户画像的Spark数据分析过程为例。需要在BDOS中新建一个Spark作业,作业填写内容如下,将分析程序提交,并设置运行需要的资源大小,该作业都会启动一个独立容器作为Spark的Driver驱动Spark集群完成处理。
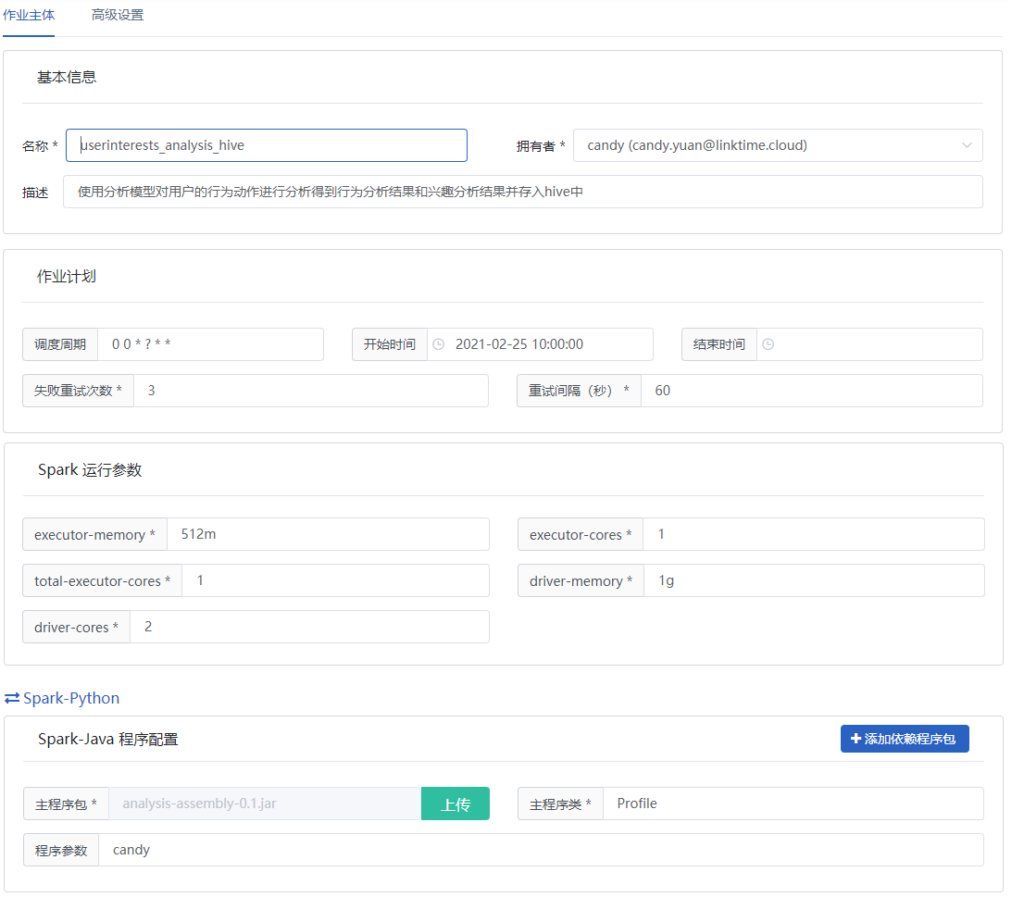
在完成上述所有数据作业后对其进行一下整理,并建立这些数据作业之间的依赖关系,通过BDOS创建一个数据流水线,将这些作业进行统一管理、统一调度,整条数据流水线就会按照设定时间以流水线中的依赖关系进行数据各个作业步骤的自动处理分析。
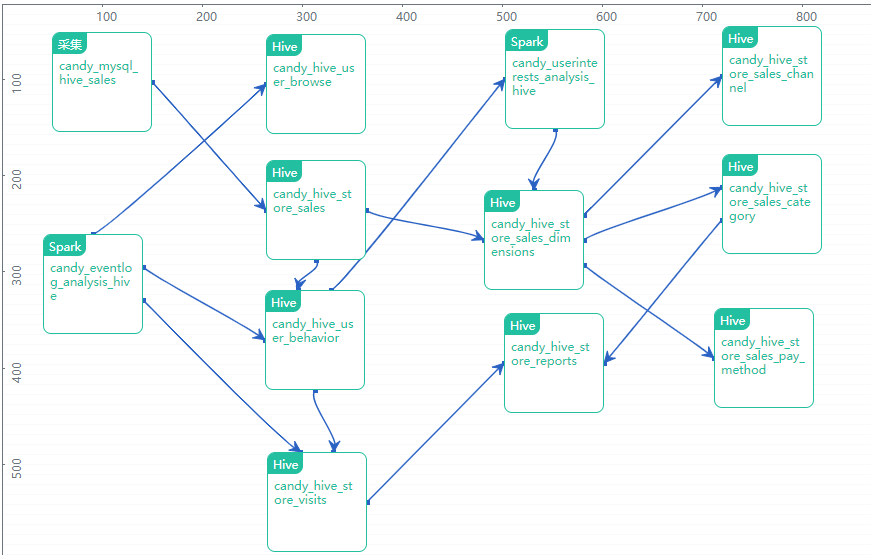
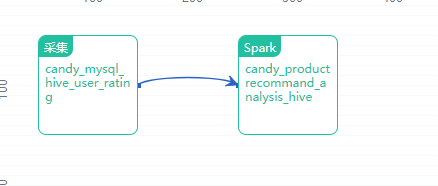
在整条数据流水线动态执行过程中,如果遇到某个作业无法完成,整个流水线将会暂停,并会对该作业进行标注,此时该作业下游的数据处理作业都将不会执行,这样就有效确保整条数据流水线执行的完整性和易运维性。每单个作业都有每次执行的详细日志保留,以便在流水线自动执行出现问题时进行问题定位。
3.4、流式数据处理
在第二部分中还有一条数据线是数据线3,通过SparkStreaming将Kafka中用户购买行为的Topic实时数据进行解析处理,并结合Redis进行一定的汇总,供销售情况大屏使用。由于Log Service已经在实时写入Kafka,在Kafka相应的Topic中能够动态看到电商平台实时销售的订单相关数据,要形成实时的流式数据处理,这里分享使用SparkStreaming来实时提取Kafka的数据,进行分析汇总到Redis中,可以供大屏实时展示使用。
本次分享的例子没有使用流水线的方式来完成,而是通过发布一个SparkStreaming的自定义应用进行实时处理指定Topic的数据、再经过汇总统计后记录进入Redis中,达成实时大屏展示销售情况和一些基本统计汇总的实时展示的作用。
总结
经过第一部分的介绍说明让大家了解了本期分享的数据流水线的作用和应用背景;再经过第二部分的解析,相信很多朋友都应该比较清晰整个数据流的处理过程和每个过程要实现的数据处理分析目的;第三部分是通过我们公司的BDOS产品对上述流水线进行实现的一个简要介绍(由于时间和篇幅限制,就不进一步展开说明,有兴趣的朋友可以联系我们来领取相关资料)。
其实在去年,我们曾经对这个过程做过一个使用纯开源软件、自搭建的实现过程,说实话搭建起来的复杂度还是很高的。下面的列表列出了只是流水线中所使用的大数据框架和组件,中间不包含我们的云平台层的内容(也就是不包含涉及资源调度的部分)。
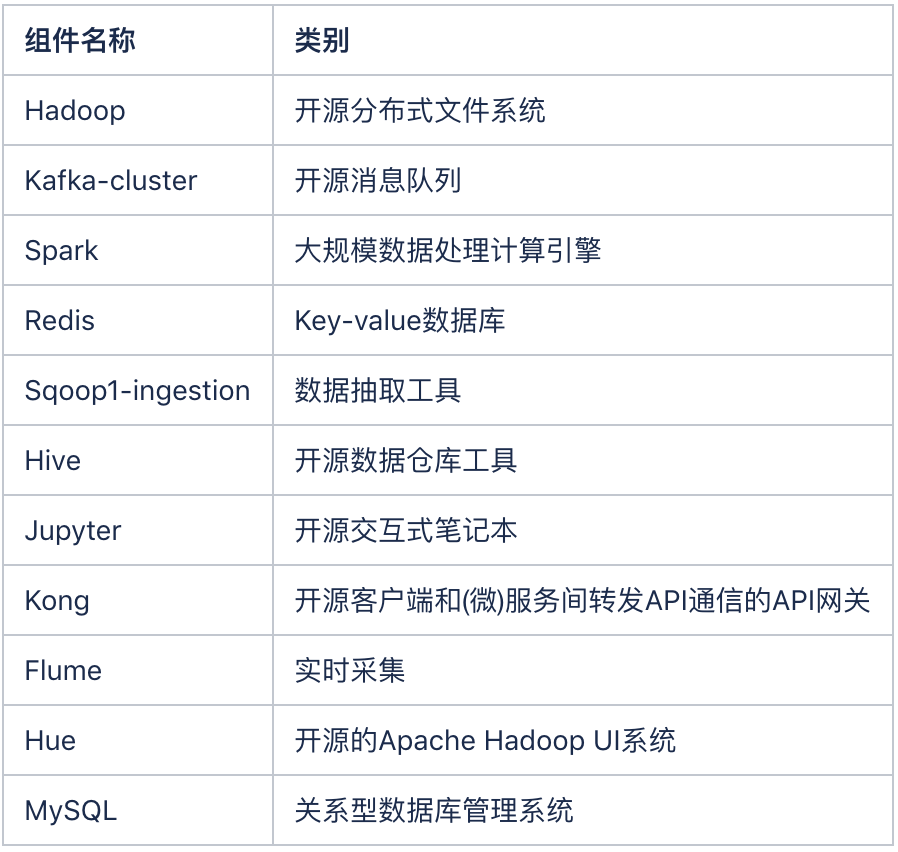
在实现过程中我也省去了有关Jupyter的使用来协助编写Java、Python程序以及通过Hue来测试Hql正确性的过程。看到上面的列表就是本期中涉及的开源组件和工具,如果不具备一定的沉淀,很难能够快速启动步入大数据分析和数据驱动之路。列表中我还没有列出Kerberos和Ranger两个能够实现多租户功能的组件(使用的BDOS中,多租户是标配)。
后面有时间,可以针对这组流水线,再专门介绍如何使用开源组件从零搭建实现的步骤。谢谢大家!
留言
评论
暂时还没有一条评论.