数据工程-爬虫采集
系统通过统一界面的爬虫采集步骤,实现界面化爬虫采集。通过界面点击,添加爬虫采集步骤至列表,并在列表中选择步骤进行编辑
步骤配置
点击编辑进入,通过界面填写参数
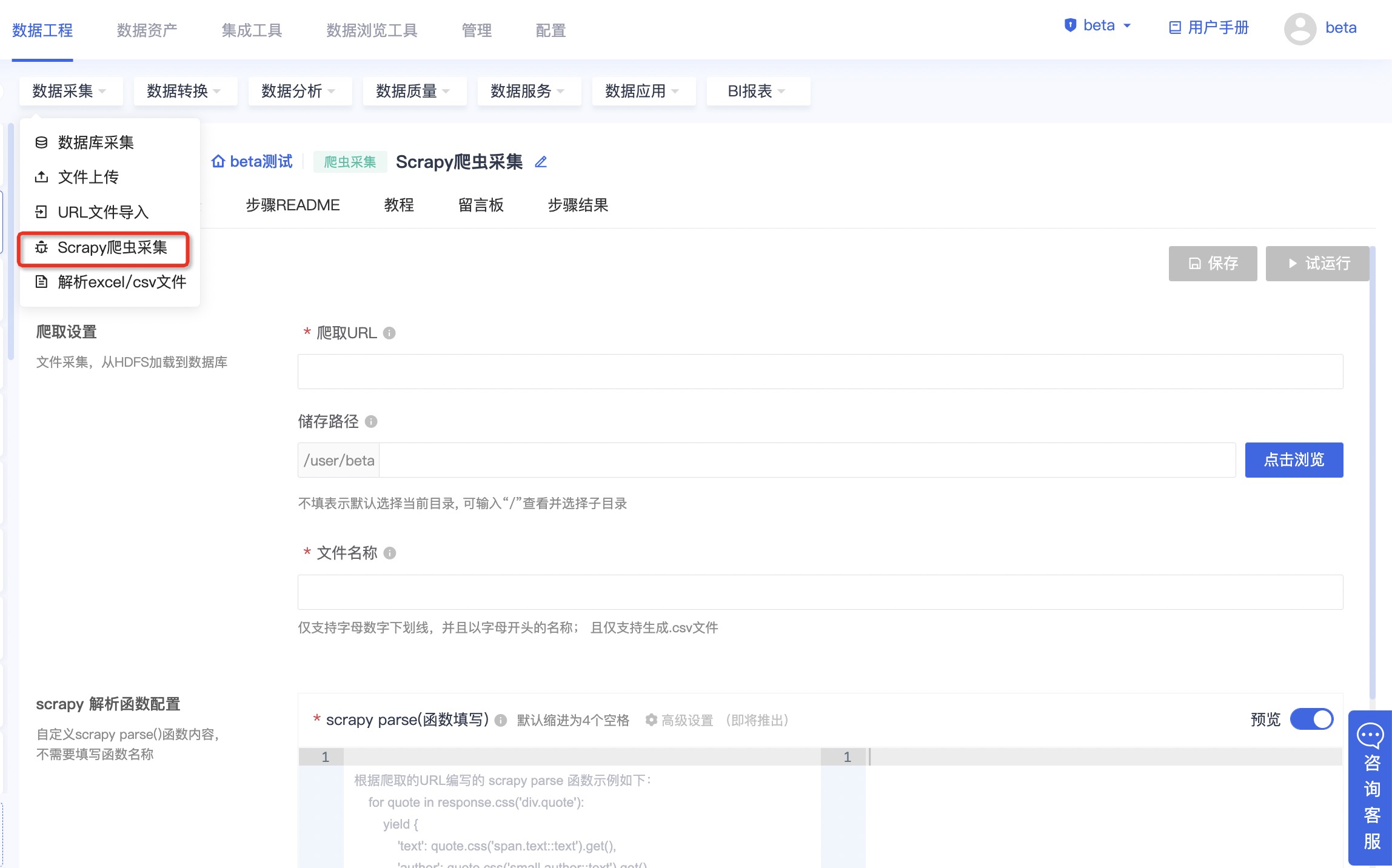
爬取设置
配置爬取的目标URL、爬取内容存储文件及目录
| 信息项 | 内容 | 备注 |
|---|---|---|
| 爬取URL* | 程序爬取的目标URL链接,如示例链接:http://quotes.toscrape.com/page/1/。 | |
| 储存路径* | 存储至系统的HDFS授权目录,可输入“/”查看并选择子目录。不填表示默认选择当前目录。 | |
| 文件名称* | 用户自定义指定文件名称,存储抓取的数据到指定的文件下(仅支持生成.csv文件)。注:仅支持字母、数字、下划线,并且名称须以字母开头; |
参考截图

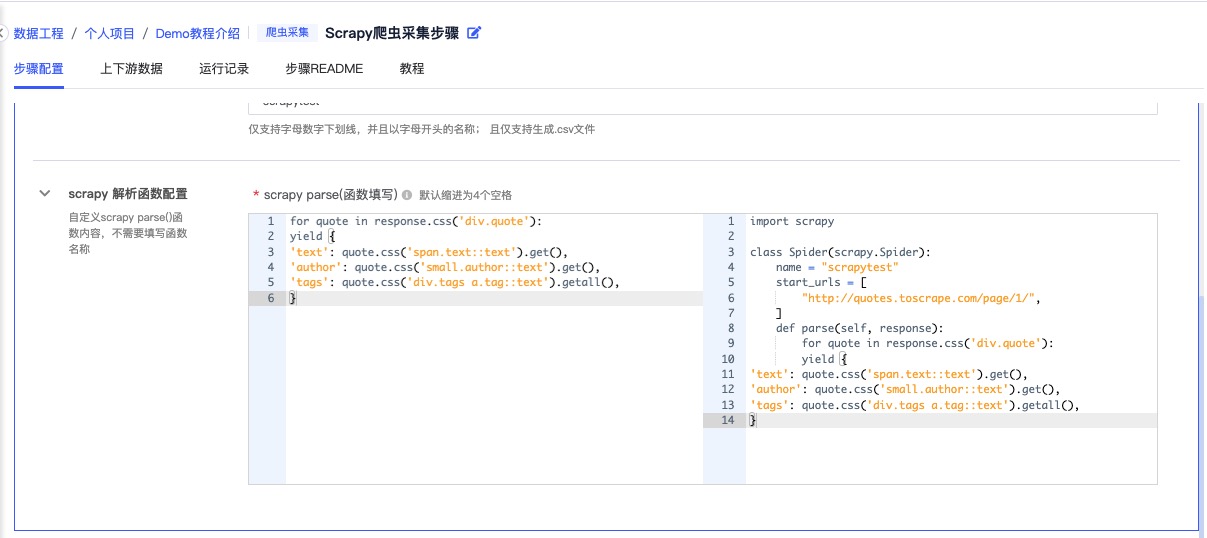
Scrapy解析函数配置
| 信息项 | 内容 | 备注 |
|---|---|---|
| scrapy parse(函数填写) | for quote in response.css(‘div.quote’): yield { ‘text’: quote.css(‘span.text::text’).get(), ‘author’: quote.css(‘small.author::text’).get(), ‘tags’: quote.css(‘div.tags a.tag::text’).getall(), } | 内容仅为爬取链接:http://quotes.toscrape.com/page/1/的示例函数填写,实际需根据目标爬取网站内容的文本结构进行填写。 |
参考截图:
配置完毕后点击保存
点击运行,运行爬虫步骤,并查看运行日志
上下游数据
用户成功执行该步骤后,可通过上下游数据界面查看上下游数据信息。时间同步有时耗,需等待片刻进行查看。
运行记录
用户可通过界面,查看步骤的历史运行记录日志详情
留言
评论
暂时还没有一条评论.