JupyterLab深度定制开发实践 | 第十三期图文直播

智领云第13次社群图文技术直播文字回放:本次直播由智领云大数据后台开发工程师 Zery,为大家带来了主题分享《JupyterLab深度定制开发实践》,主要内容包括:了解JupyterLab内部架构实现;了解JupyterLab与Spark集成原理;了解JupyterLab与作业调度系统结合方案。
JupyterLab定制开发背景
数据开发痛点分析
在大家日常的数据开发工作过程中,主要的步骤就是: 1、获取要分析的任务。2、根据数据分析任务,准备数据集,并编写获取相关数据集的导数SQL语句。3、在公司数据仓库内,执行导数任务,输出相关csv数据集。4、在本地利用单机python/R来进行探索性数据分析。5、完成数据分析,获得相关数据模型,并完成模型验证。6、将分析模型转变成相关的自动运行作业,提交到作业调度系统。 整个流程如下图所示:

在这个过程中,我们会发现存在如下问题:
1、需要操作各种不同的大数据组件平台,比如ETL作业清洗平台,导数平台,本地开发环境。
2、采集的数据集只能单机运行,而最后提交的作业是分布式运行。
3、单机分析的数据集有限,而最终模型任务是全量数据集。
而这些问题,对于数据开发人员来说都是日常很普遍碰到的问题,而我们的数据中台产品,则是要提高开发人员最大的工作效率,能减少他们在数据之外的事情上精力的消耗。
同样的问题,在我们做其他数仓项目,也都存在,我们可能需要在本地做很多的调试和测试工作,然后再将相关作业,可能是jar包,可能是python文件,可能是SQL文件,上传到数据平台上运行,大家习以为常的数据开发日常,其实很多地方都存在了工作效率的浪费。
在这种情况下,我们希望能找到一个解决方案,来解决这些痛点问题,以实现:
- 体验流畅:数据任务可以在统一的工具中完成,或者在可组合的工具链中完成。
- 体验一致:数据任务所用工具应该是一致的,不需要根据任务切换不同工具。
- 使用便捷:工具应是开箱即用,不需要繁琐的前置配置。
- 结果可复现:分析过程能够作为可执行代码保存下来,需要复现时执行即可,也应支持修改。
- BDOS集成:作为ETL作业编写调试的IDE,简化开发流程。
基于该目标,我们选取了JupyterLab作为主要解决方案,然后基于JupyterLab,我们对其做源码级别改造及增加自定义的插件开发,来完成该目标。改造内容如下:
- 接入Spark:取数与分析均在JupyterLab中完成,达到流畅、一致的体验。
- 接入调度系统:方便沉淀分析结果。
- 接入Gitlab/知识分享平台:方便分享和复现。
- 预配置环境:提供给用户开箱即用的环境。
- 用户隔离环境:避免用户间互相污染环境。
JupyterLab 架构原理分析
在确定改造内容之后,我们要开始进行开发,首先就要对JupyterLab进行深入的理解。只有了解了JupyterLab的整个工作原理和代码结构框架,才能基于之上做随心所欲的开发改造工作。
项目组件介绍
JupyterLab是由若干个组件组合完成的,所有组件都是单独的repo,每个组件都是完成自己相应的功能。
其中,比较重要的几个组件是jupyter_core,jupyterLab,jupyter_server,jupyter_client, notebook。
其中,jupyter_core提供jupyter命令行命令,主要处理配置文件和读取目录等相关操作。
jupyterLab主要提供前端集成IDE开发环境,他会提供notebook,terminal终端,text文本编辑器,文件浏览器,富文本输出等等自定义的notebook,还会提供丰富的前端接口,方便用户开发扩展。
jupyter_server主要提供后台接口服务,前端应用和后台通信的主要接口,都在jupyter_server中。常见的jupyter web应用有jupyter notebook, jupyterLab,和voila。
jupyterlab_server主要给jupyterLab或者类似jupyterLab的应用提供服务组件。jupyter_client 主要是notebook和kernel之间通信的桥梁,会提供各种通信协议和kernel管理操作API。notebook repo 提供notebook的主操作界面,提供交互式计算环境等相关。
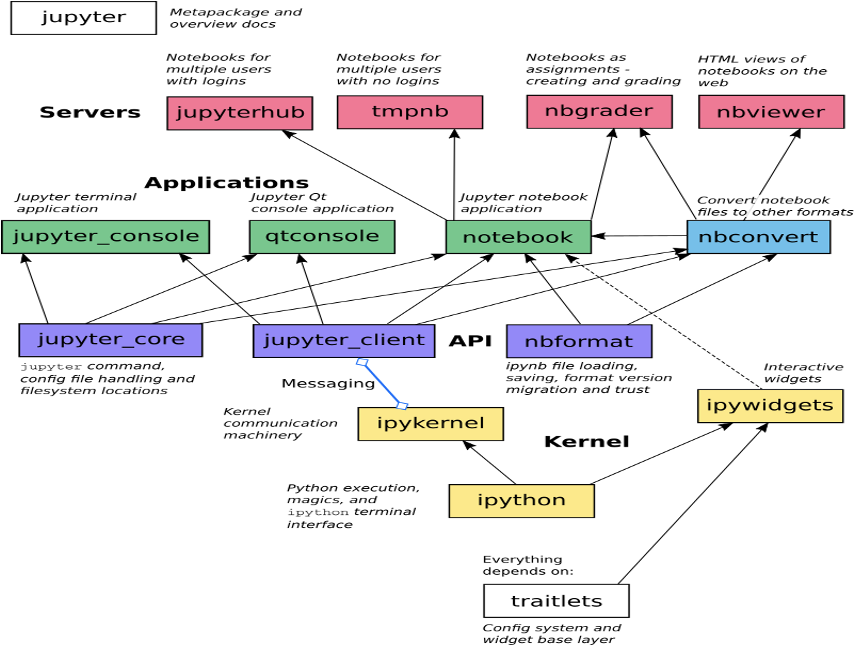
如上图所示,我们要改造,主要关注jupyter_client和jupyter_server这两个repo。因为jupyter_client提供了前端notebook和后端运行代码kernel的中间件,如果我们想修改用户的代码逻辑,或者在用户的代码中增加额外的配置逻辑等等,就可以在jupyter_client中实现。
而jupyter_server提供了后台服务的执行流程,如果想更改jupyterLab的运行逻辑,比如token维护等,则需要修改jupyter_server相关代码。至于扩展notebook的界面UI,在jupyterLab中新增页面,我们可以直接进行jupyterLab插件开发,而不需要修改jupyterLab的源码。
JupyterLab Client功能原理
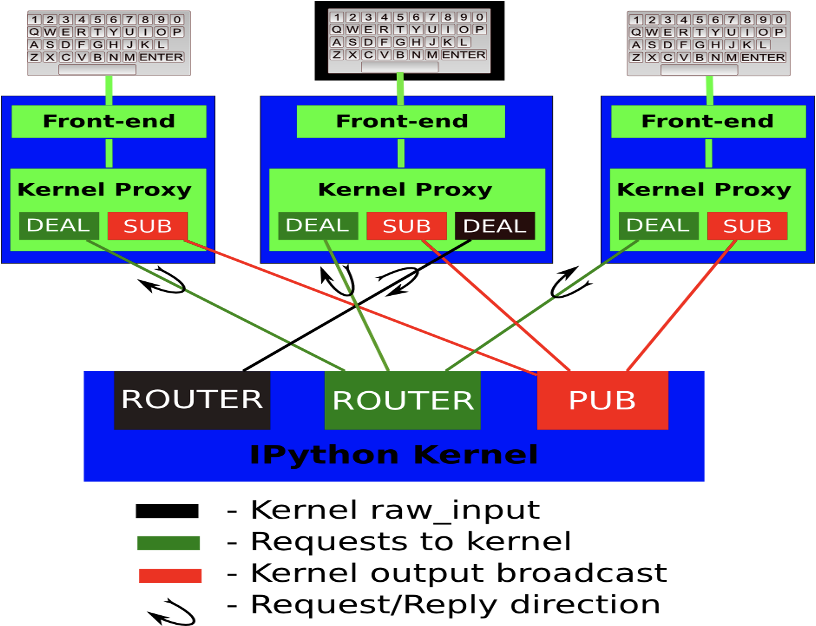
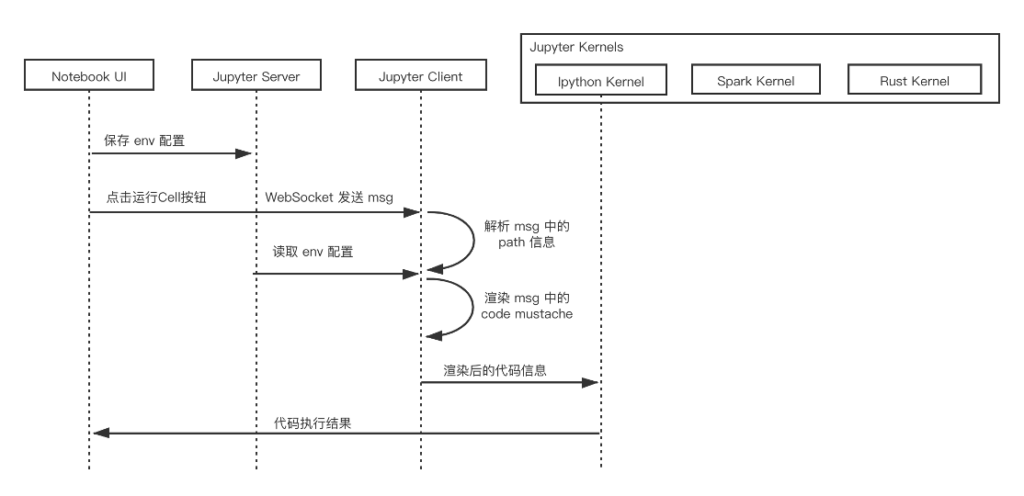
当用完成代码编辑后,点击notebook的运行cell按钮,notebook会将代码通过jupyter client的channel发送到kernel,这个过程中使用的是web socket协议。
web socket 消息体包含几种类型:
1、Shell 执行代码,获取目标信息,kernel相关指令等等都使用该通道。
2、IOPub 主要是广播通道,主要是kernel发布一些需要广播的信息,比如stdout/stderr/debugging event等等。
3、Stdin 主要是命令行方式和kernel通信时使用。
4、Control 和Shell通道类似,但是主要是传输控制命令,比如重启kernel,关闭kernel等等,也会用来传输debugging消息。
5、Heartbeat 该通道用来维护服务端和前端的心跳包。 jupyter_client 架构原理如下图所示。
前端组件介绍
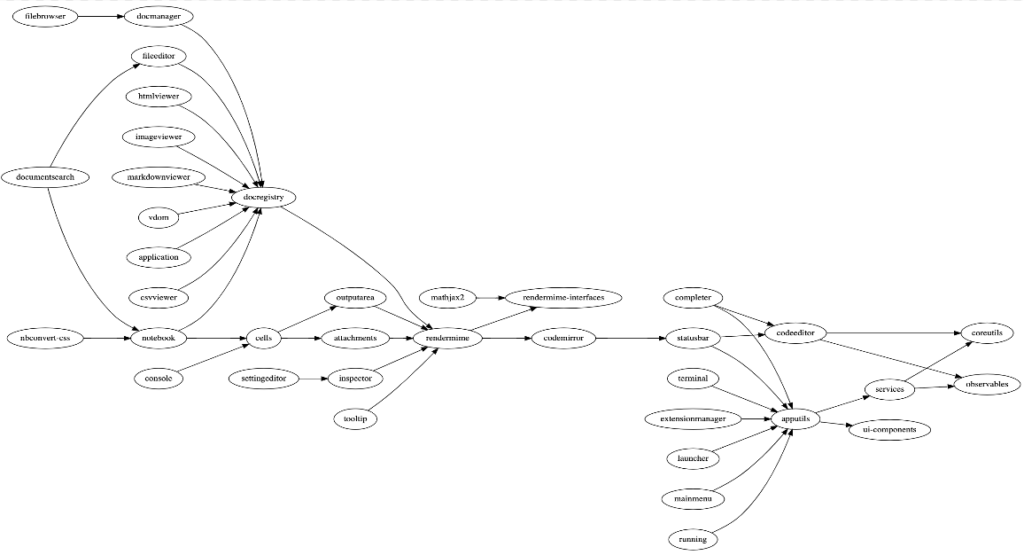
而jupyterLab的前端组件,我们都可以在自定义扩展开发过程中来调用使用,我们可以从下图中来观察各个组件的依赖实现。
其中比较重要的几个组件依赖是,docregistry组件来负责管理所有的文件格式浏览,包括图片/html/notebook/csv/markdown等等格式,而notebook包括所有的cells管理,rendermime组件负责所有的显示渲染输出,包括代码结果,数据结果,侧边栏,工具栏等等。而apputils包含了界面上所有的可扩展元素管理,包括launcher主页面管理,mainmenu主菜单管理,terminal,statusbar状态栏等等组件。
了解前端组件依赖,我们可以比较顺畅进行jupyterLab插件开发,jupyterLab插件开发主要开发语言是Typescript,具体的开发文档可以访问:https://jupyterlab.readthedocs.io/en/stable/extension/extension_dev.html。
LinkTime JupyterLab 架构
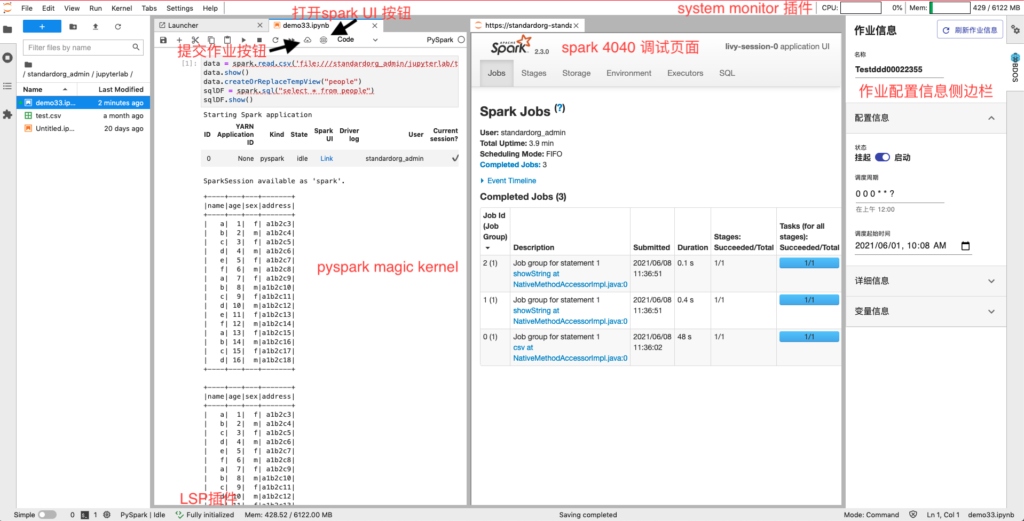
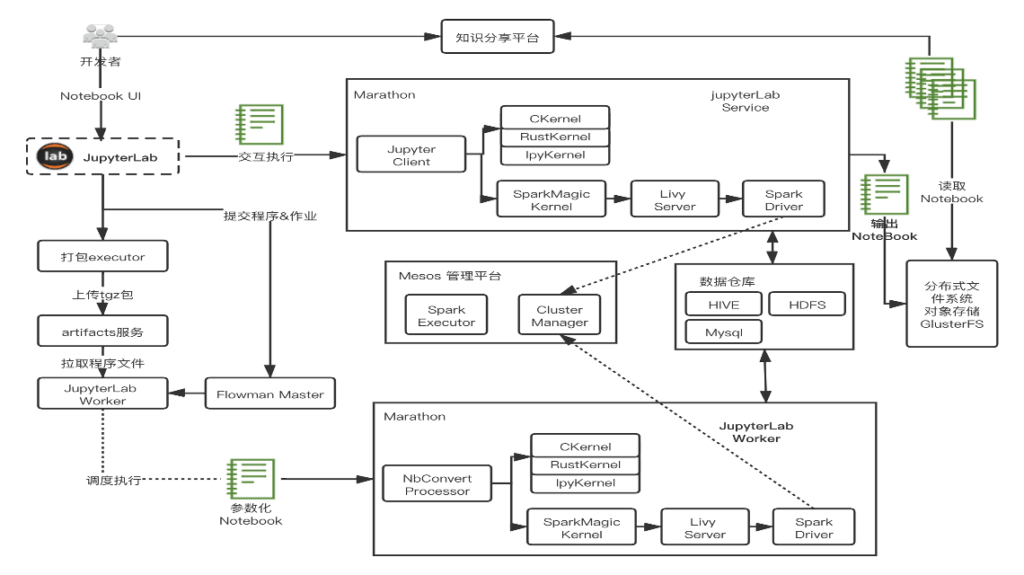
在开始讲解LinkTime JupyterLab架构之前,可以看看我们改造后的JuPyterLab界面。如下图所示,我们增加了一个react widget的侧边栏用来展示和配置作业信息。在notebook的菜单栏增加了提交作业和打开spark UI 两个按钮。点击spark UI按钮后,会开启一个iframe展示spark 4040 debug页面。
我们增加了spark magic kernel来运行spark程序,增加了LSP server创建来做代码的提示补全,增加了system monitor插件来监控jupyterlab容器的内存和CPU。其他的部分,我们改造了spark magic kernel,使其支持运行多行hive sql语句。
方便运行ETL作业。整个界面如下图所示:
支撑整个界面展示及后台运行的,是整个LinkTime JupyterLab的架构设计。 如下图所示,开发者打开LinkTIme JupyterLab界面后,有两条路径可以做。第一条是运行交互式程序开发,直接运行cell中的代码。另一条是将当前的notebook提交到BDOS集群中调度运行。对应着就是大家先使用集群的数据来进行开发和测试,测试成功后 ,可以将其变成定时运行的作业,提交到BDOS云平台调度运行。
对于交互性代码运行线路,我们在服务端集成了sparkMagic kernel,IpythonKernel,RustKernel等等kernel,用户可以选择相应的kernel来进行相应的代码开发。而sparkMagic kernel通过LivyServer来提交spark任务到BDOS云平台,而我们的BDOS云平台是使用Mesos来做容器资源调度管理的。spark任务提交后,在mesos框架内调度执行。
对于hadoop集群的访问,我们直接集成到了spark服务中,可以通过sparkMagic kernel的magic命令来运行hive查询命令,可以直接通过spark代码来访问hdfs文件或者集群的mysql数据库等数据源。
而用户的notebook文件,我们是存放到glusterfs分布式文件系统上,映射到用户的容器内目录,用户保存后可以持久化存储。对于提交BDOS调度作业线路,我们新增了JupyterLab worker服务,其和BDOS中的调度系统Flowman的master服务进行通信,来调度执jupyterLab作业。
在这里我们使用了nbConvert组件来执行ipynb notebook文件,nbConvert组件会将代码通过jupyter_client提交到集群运行。而对于notebook的分享,我们是通过glusterfs分布式文件系统来完成,分享平台会读取glusterfs分布式文件系统上的不同用户对应的notebook,来进行索引和展示。
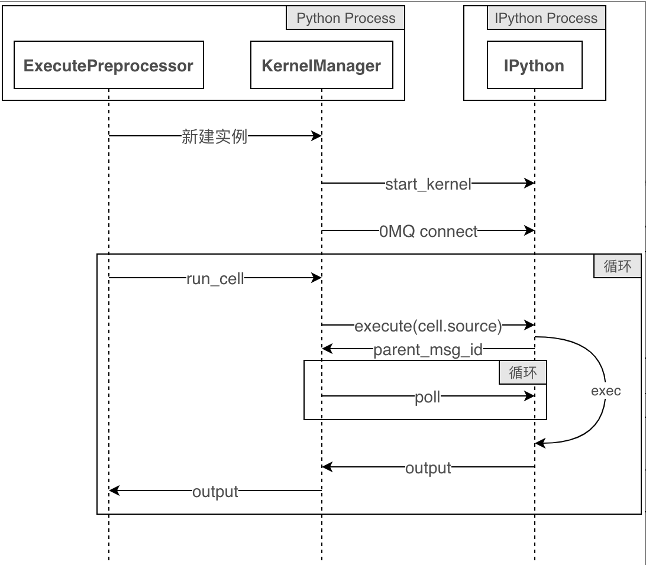
ipynb作业执行原理
JupyterLab worker内,调用nbConvert组件,通过ExecutePreprocessor函数执行notebook文件,他会通过jupyter_client的KernelManager接口来创建一个notebook对应的kernel进程,然后创建相应的socket通信,调用run_cell函数后,循环遍历执行所有的cell中的代码并输出相应的结果。整个流程如下图所示。
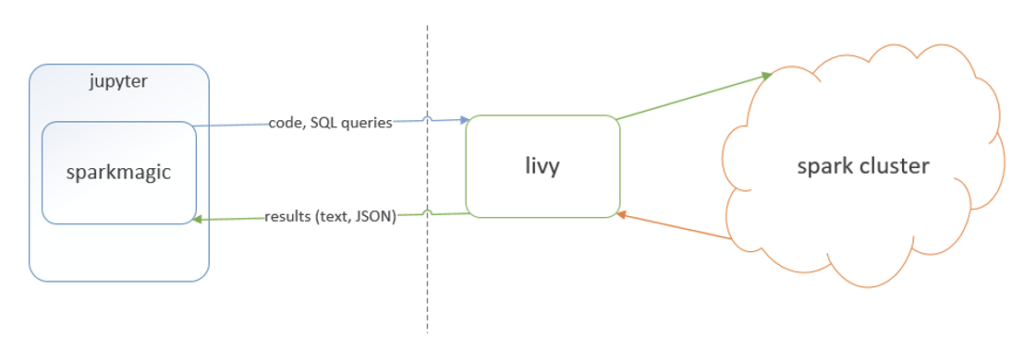
spark 作业执行原理
而spark作业,主要通过sparkmagic kernel来实现,他会和livy server来进行通信,一个notebook会对应一个livy session,而livy和后端spark集群的集成方式,sparkmagic并不关心。
也就是说spark部署模式,不管是mesos还是k8s或者standalone,都是livy服务来维护管理的。整个过程如下图所示 :
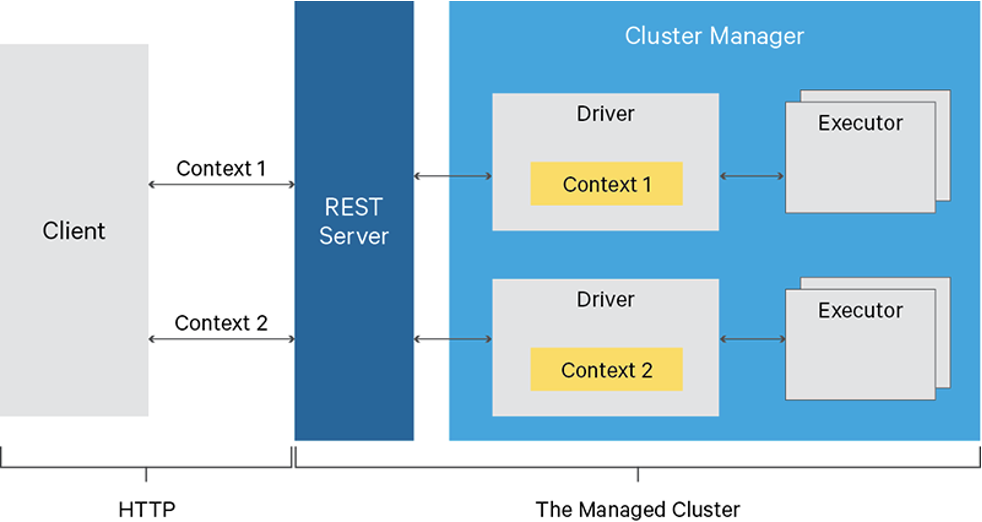
Livy服务,相当于一个使用Rest api来提交spark任务的服务,他维护了context,方便客户端提交代码片段来执行。
spark 4040界面展现实现原理
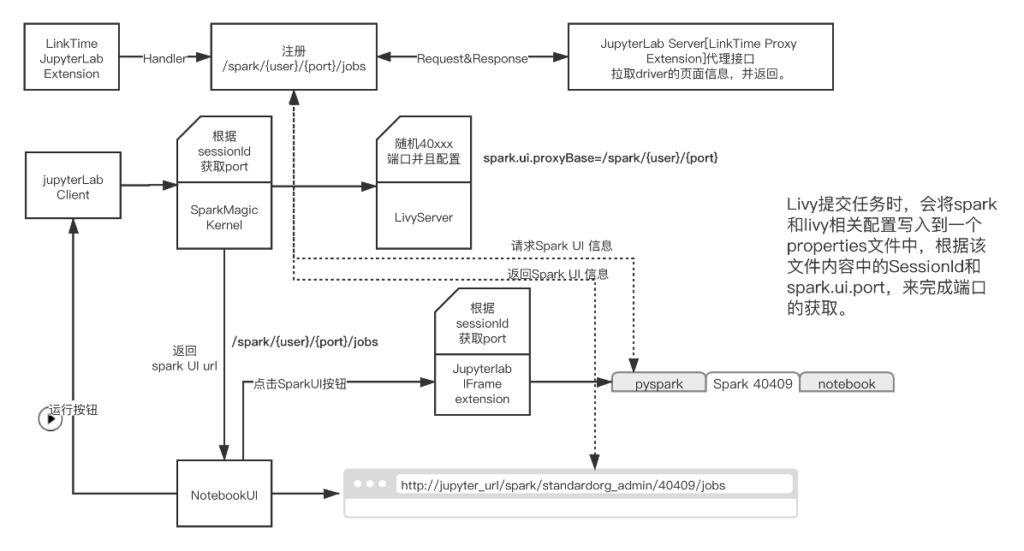
定制化中比较复杂的还有spark 4040页面调度改造。我们的Livy配置的是spark on mesos with client模式,也就是说spark的driver是运行在livy服务容器内的。而spark的4040页面中所有page的跳转,他都会在当前页面URL后去找跳转路径。利用这些特点,我们做了如下改造:
1、在jupyterLab server内增加一个代理,会注册一个/spark/{user}/{port}/的代理路径,用户请求该路径后,将数据转发到127.0.0.1:{port}/spark/{user}/{port}路径中。
2、更改livy提交spark作业逻辑,增加driver端口预先分配的逻辑,并配置spark.ui.proxyBase路径为/spark/{user}/{port}。也就是说用户点击spark UI的page后,都会自动加上该前缀路径。
3、当用户点击打开spark UI按钮,会去服务端请求该spark任务对应的路径信息/spark/{user}/{port},并调用IFrame插件在jupyterlab中打开该页面。
4、修改spark magic返回spark Link信息URL,用户可以点击Link,直接跳转到spark UI 界面。
这些改造内容,实际上归纳起来,主要是做了三件事:
1、livy更改spark任务的base url增加代理路径信息+固定端口。
2、sparkmagic拿到spark的UI路径返回给前端。
3、后台服务增加代理接口代码提供前端页面访问。 整体流程如下图所示:
变量支持实现原理
由于支持提交作业调度运行,所以我们引入了变量的概念,用户可以定义外部参数变量,然后在cell代码中引用该变量,达到变量复用,方便用户编写作业调度逻辑的目的。
在代码中,使用'{{}}’双大括号的mustache格式来表示变量。而变量支持的实现原理,最主要是改造Jupyter Client服务,利用websocket中的代码消息,在发送到kernel之前,完成mustache变量的渲染,而 kernel 接收到的code,是渲染后的,替换了变量内容的代码,所以对其执行过程没有任何影响。
整个流程如下图所示。
用户权限控制实现原理
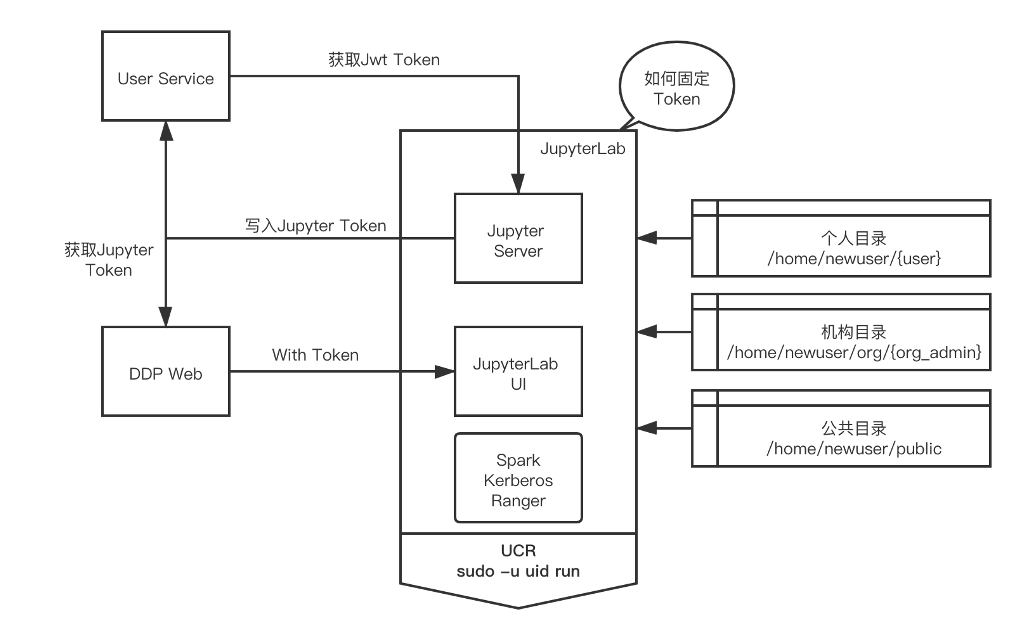
目前我们的Jupyter没有使用jupyterHub来管理用户权限,主要是我们的模式是每个用户启动一个docker容器的jupyterLab服务,每个人使用自己的jupyterLab服务,互相不会有干扰,而且JupyterLab我们定义为用户的IDE和工作平台,所以独立容器保证了独立性,也方便后续用户资源计费。
在此架构下,jupyterlab token作为用户认证主要途径,在jupyterLab系统启动时,会将用户的token存储到user service的用户表字段中,前端页面跳转jupyterlab web UI时,会去user service获取该用户的jupyterLab token,根据此token登录jupyterLab服务,完成认证。
而目录权限的控制,主要是不同的用户和机构目录挂载到不同的目录。对于hadoop的访问权限控制,我们会把kerberos/ranger相关配置集成到了app中,并且jupyterLab服务和livy服务都会使用对应的用户USER ID来启动。
留言
评论
暂时还没有一条评论.