渠道分析-操作指南
数据分析是广告优化的基础能力,广告投放过程中通过数据分析挖掘改进点,可以数倍降低用户获取的成本,同时量化广告投放的ROI。本项目以某电商的广告渠道投放及生产系统的Demo数据为例(Demo样例数据约5万条),对渠道数据和生产数据进行采集,将投放的广告数据与生产数据进行深度的关联,得到渠道数据模型,并从广告点击率、获客成本等维度对数据进行分析。
BDOS Online提供一套数据工作流系统,能够根据时间或数据可用性来运行这些程序和查询,实现任务的编排、调度、监控。并以DAG拖拉拽的方式,全任务管理、监控作业及其依赖关系,提供数据采集、数据处理及数据导出等步骤初始化后的定时自动化调度运行,并支持任务排队和插队机制。包括步骤如下:
第一步: 数据库采集,采集行业广告渠道信息和业务数据到指定 Hive 库 第二步: Hive 程序,从广告点击率、获客成本等维度对数据进行分析 第三步:ETL 程序,把数据从数仓导入到指定的 MySQL 库,对结果数据的可视化展示进行数据准备 第四步: Superset,通过集成工具- Superset 对结果数据进行 BI 可视化展示
用户只需克隆本项目,通过几次简单的点击,即可完成端到端的渠道分析数据场景。
完整文档下载链接
步骤介绍
1. 克隆公共项目
用户登陆 BDOS Online 后,通过项目类型筛选公共项目,选择渠道分析-场景体验进行克隆
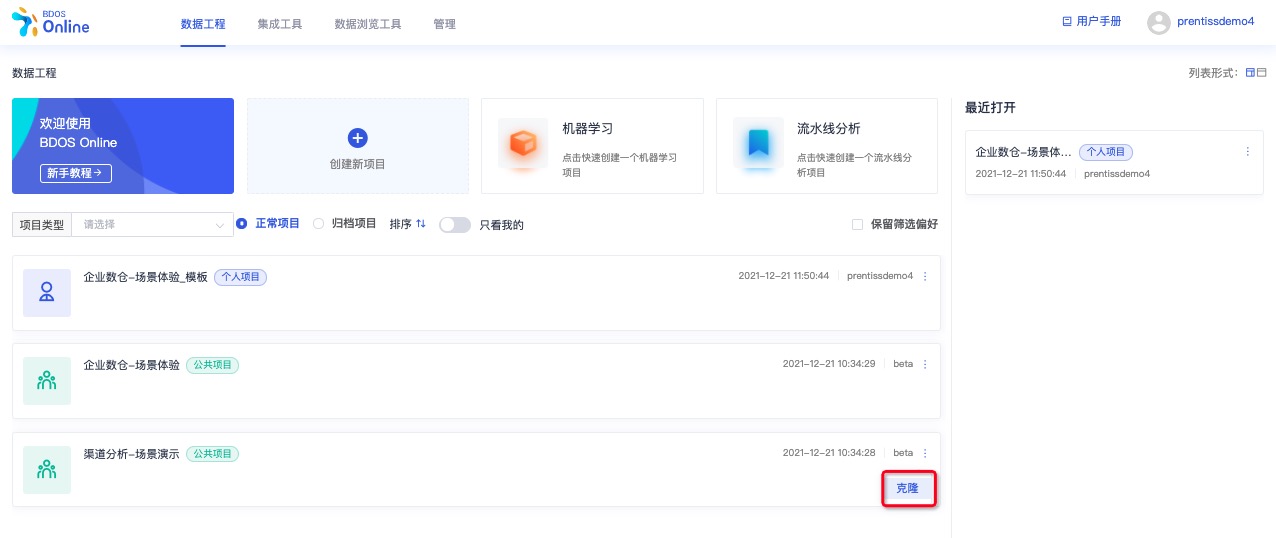
点击克隆,并自定义项目名称

进入项目主页
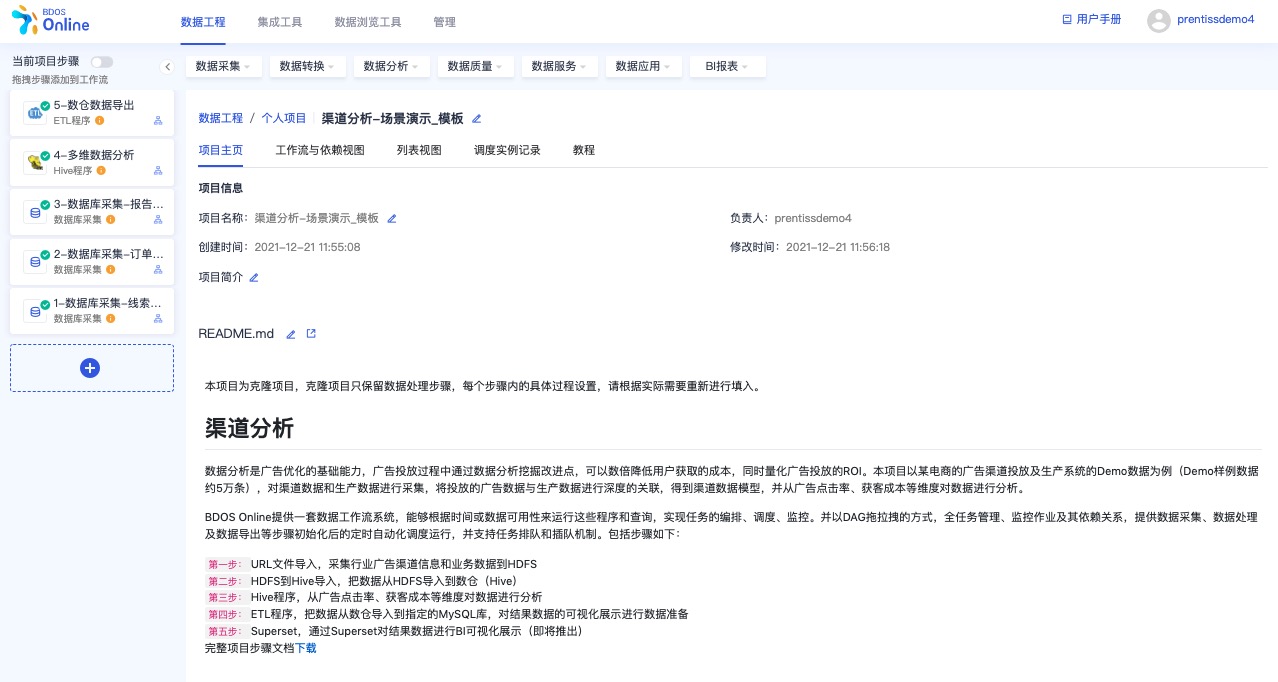
2. 启动项目步骤
2.1 数据库采集,采集线索表到指定 Hive 库
克隆公共项目-渠道分析后,进入步骤1:数据库采集-线索表(channel_clue_source),点击进入编辑界面
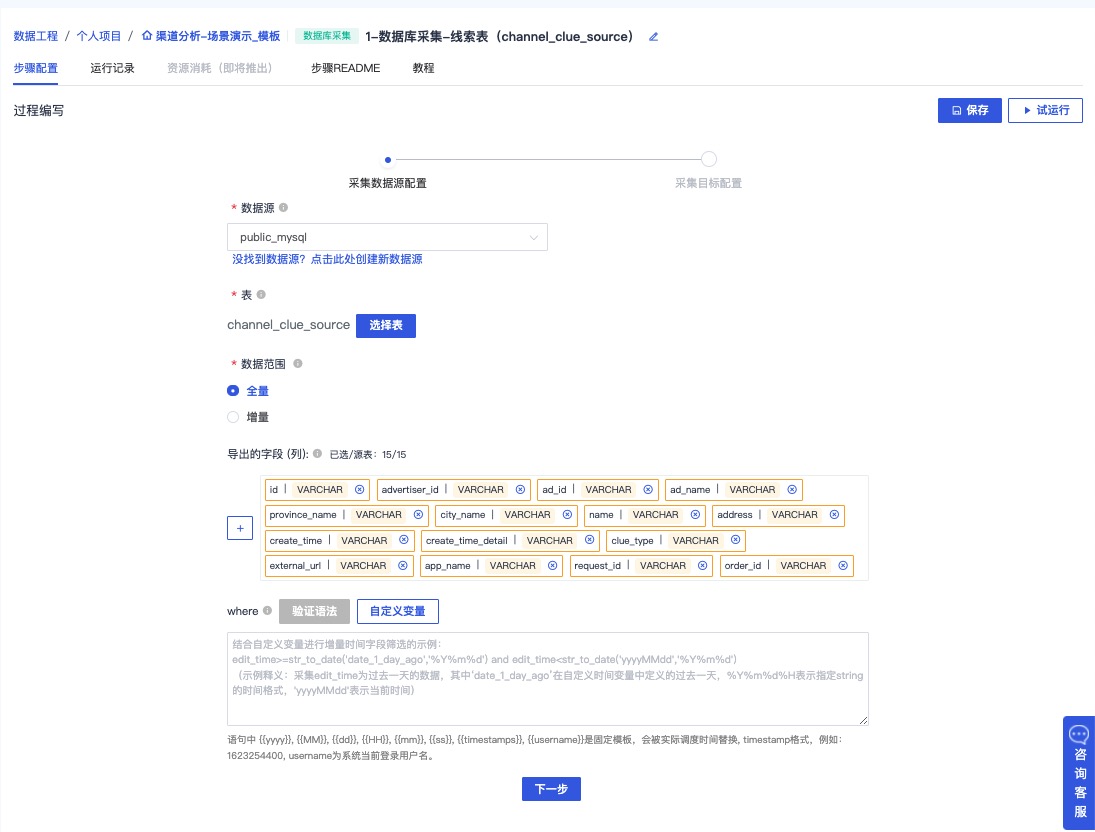
保持配置内容并点击下一步
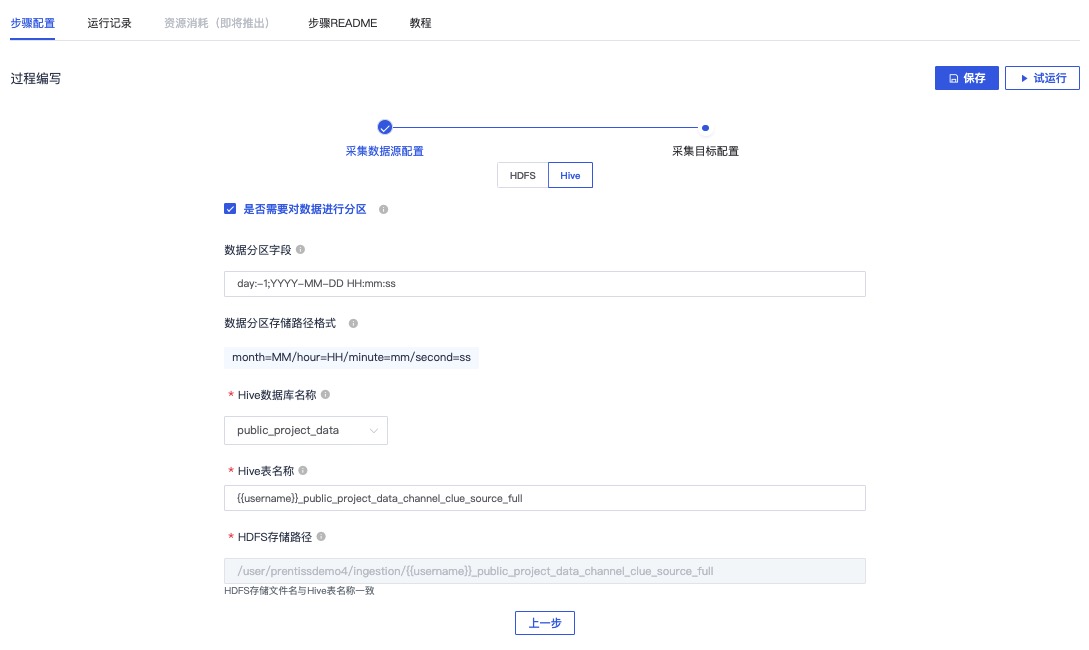
点击保存后,点击试运行
查看运行记录
2.2 数据库采集,采集订单表到指定 Hive 库
进入步骤2:数据库采集-订单表(channel_order_source),点击进入编辑界面
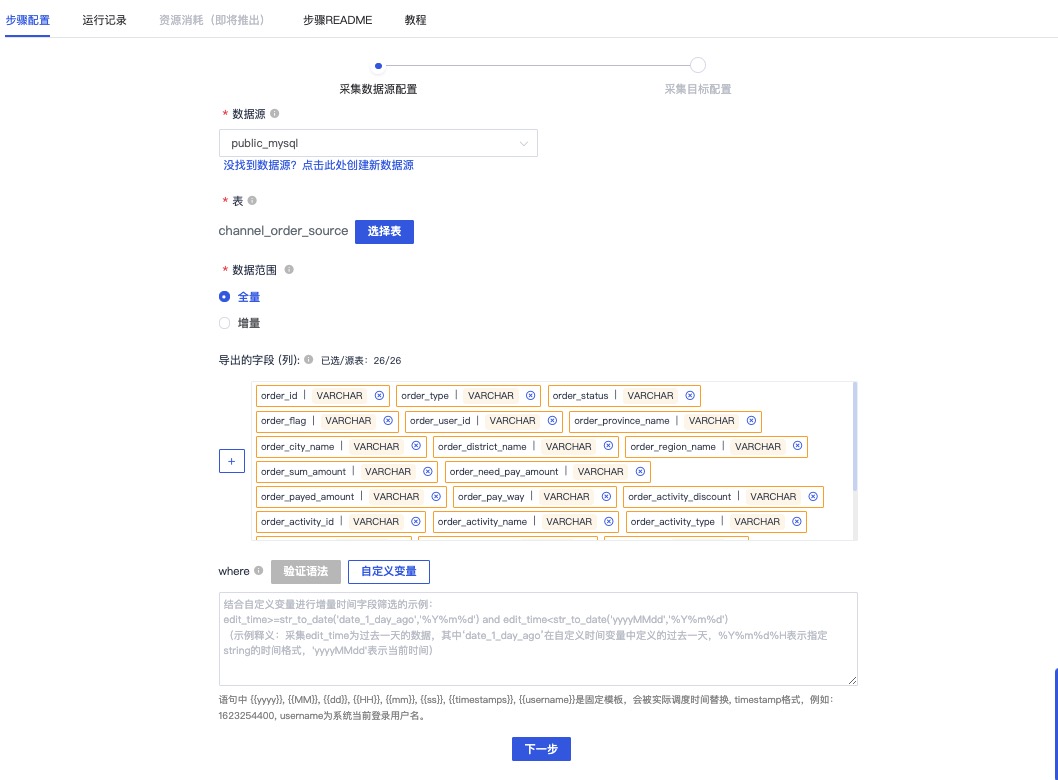
保持配置内容并点击下一步
点击保存后,点击试运行
查看运行记录
2.3 数据库采集,采集订单表到指定 Hive 库
进入步骤3:数据库采集-报告表((channel_report_source)),点击进入编辑界面
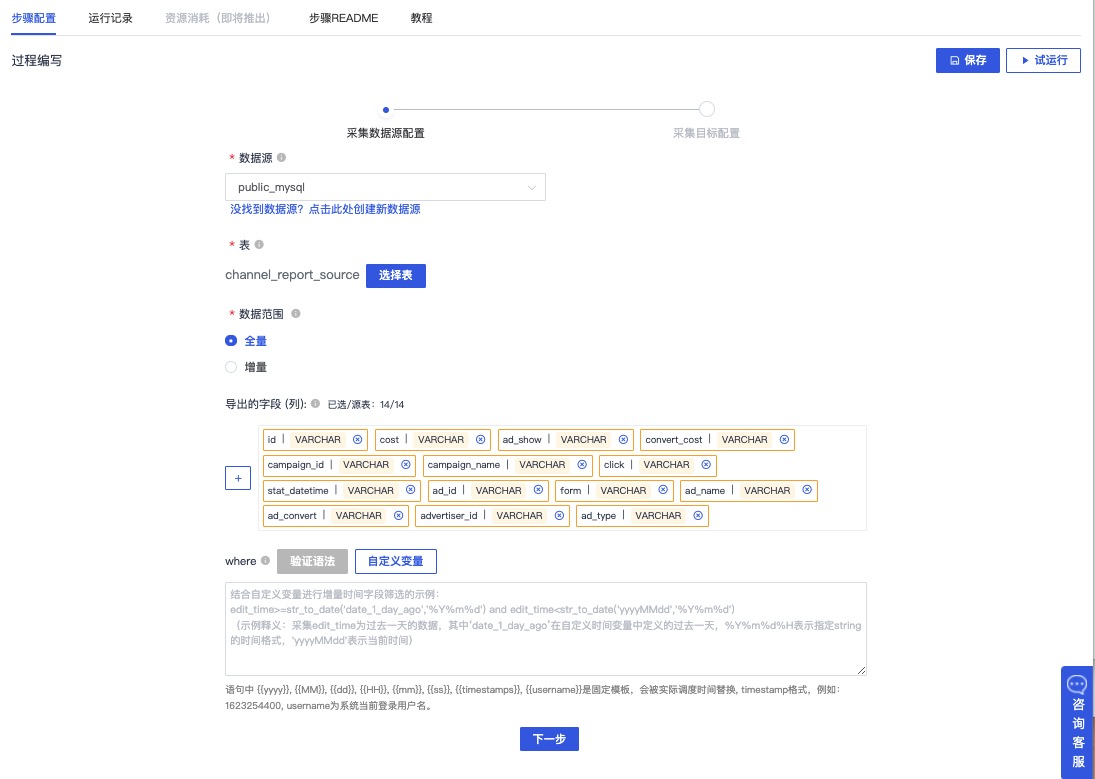
保持配置内容并点击下一步
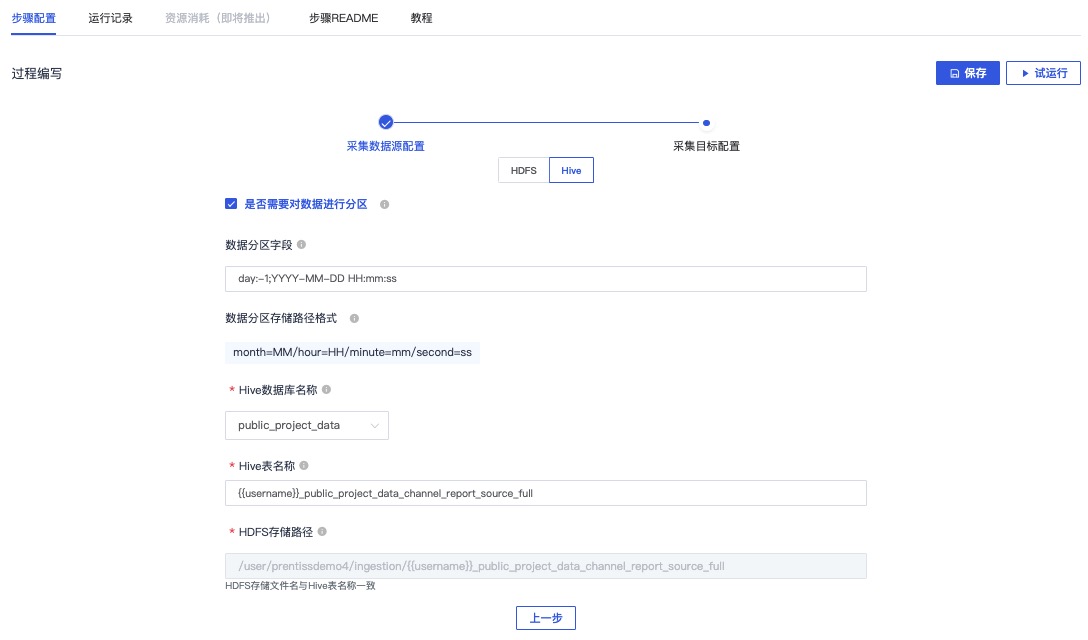
点击保存后,点击试运行
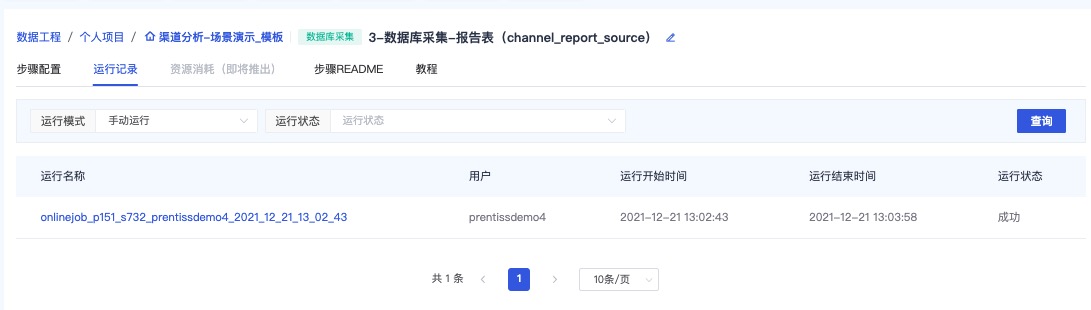
查看运行记录
2.4 Hive程序,从广告点击率、获客成本等维度对数据进行多维分析
进入步骤4:多维数据分析,点击进入编辑界面

保持默认,点击保存后,点击试运行
编写主程序
--创建渠道数据输出表, 并设定输出的字段名称、 类型和描述
CREATE TABLE
if not exists public_project_data.{{username}}_channel(
`id`
int COMMENT '唯一ID',
`ad_type`
string COMMENT '渠道类型',
`cost`
float COMMENT '展现数据-总花费',
`ad_show`
int COMMENT '展现数据-展示数',
`convert_cost`
float COMMENT '转化数据-转化成本',
`advertiser_id`
int COMMENT '广告主ID',
`campaign_name`
string COMMENT '广告组name',
`click`
int COMMENT '展现数据-点击数',
`stat_datetime`
string COMMENT '数据起始时间',
`ad_id`
int COMMENT '计划id',
`form`
int COMMENT '落地页转化数据-表单提交',
`ad_name`
string COMMENT '计划name',
`ad_convert`
int COMMENT '转化数据-转化数',
`ad_order`
int COMMENT '订单数',
`ad_amount`
float COMMENT '订单总金额'
);
set hive.exec.dynamic.partition = true;
set hive.exec.dynamic.partition.mode = nonstrict;
set hive.exec.max.dynamic.partitions.pernode = 3000;
set hive.exec.max.dynamic.partitions = 3000;
set hive.exec.max.created.files = 3000;
--设置中间表: report_clue_table, 并选择report表和clue表中需要的字段进行中间表存储
WITH report_clue_table AS(
SELECT report.*, clue.order_id FROM public_project_data.{{username}}_public_project_data_channel_report_source_full report LEFT JOIN(SELECT ad_id, order_id from public_project_data.{{username}}_public_project_data_channel_clue_source_full) clue ON report.ad_id = clue.ad_id
),
--对中间表进行字段处理
report_clue_order_table AS(
SELECT rc.*, orders.order_payed_amount FROM report_clue_table rc LEFT JOIN(SELECT * FROM public_project_data.{{username}}_public_project_data_channel_order_source_full) orders ON rc.order_id = orders.order_id
)
--把处理的结果及筛选的字段写入目标表
insert overwrite table public_project_data.{{username}}_channel
select
jr.id,
jr.ad_type,
jr.cost,
jr.ad_show,
jr.convert_cost,
jr.advertiser_id,
jr.campaign_name,
jr.click,
jr.stat_datetime,
jr.ad_id,
jr.form,
jr.ad_name,
jr.ad_convert,
rco.ad_order,
rco.ad_amount
FROM public_project_data.{{username}}_public_project_data_channel_report_source_full jr
LEFT JOIN(
SELECT ad_id, count(1) as ad_order, sum(order_payed_amount) as ad_amount FROM report_clue_order_table where order_id is not null and order_payed_amount > 0 GROUP BY ad_id
) rco
ON jr.ad_id = rco.ad_id
查看运行记录
参考截图查看Hive程序运行记录,可点击运行名称查看日志详情

预览数据表
用户从【管理-个人-数据表管理】菜单进入,通过数据源类型和数据库筛选,可预览上一个步骤创建的数据表数据

2.5 ETL程序,把数据从数仓导入到指定的MySQL库
进入步骤5:数仓数据导出,点击进入编辑界面
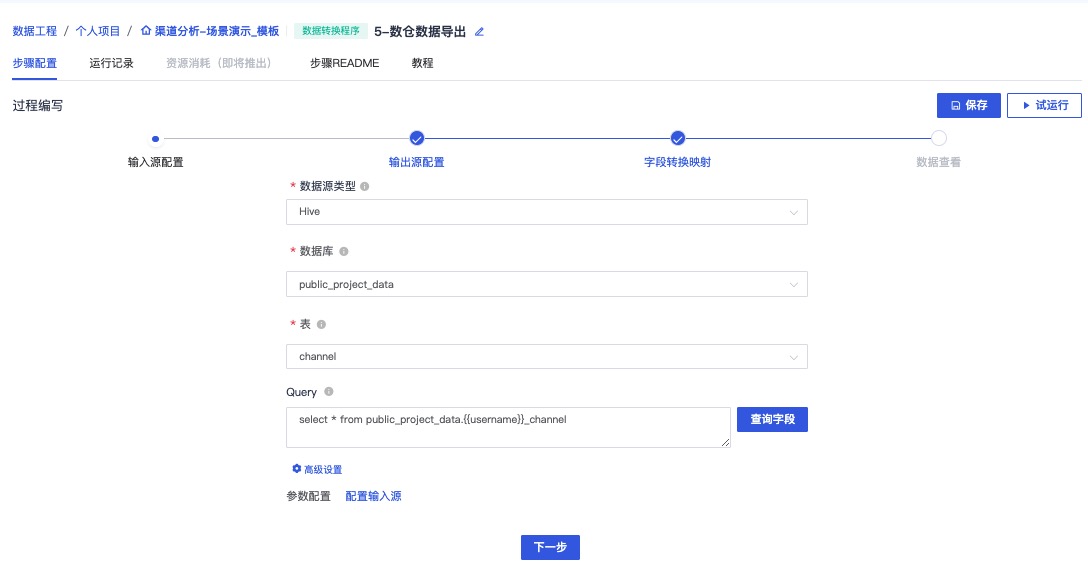
点击下一步
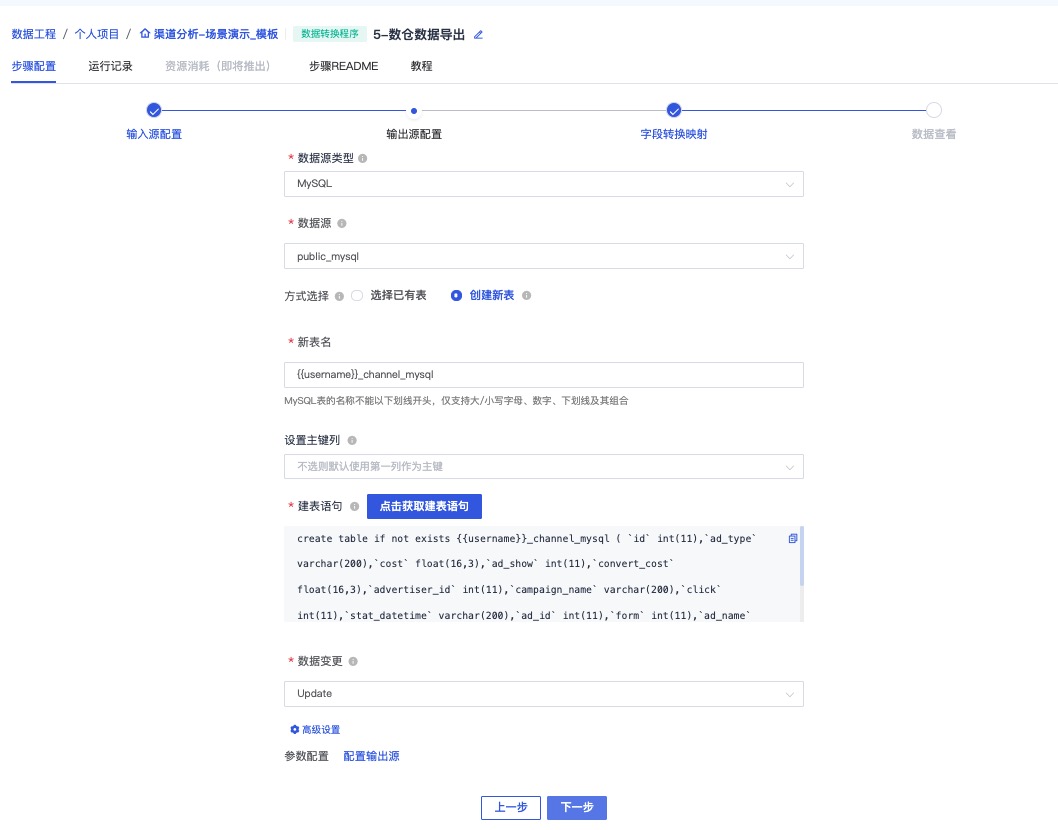
注:请点击获取建表语句
保持默认并点击下一步
选择字段匹配标准,进行输入源字段和输出源字段的映射匹配,点击下一步,对数据进行预览
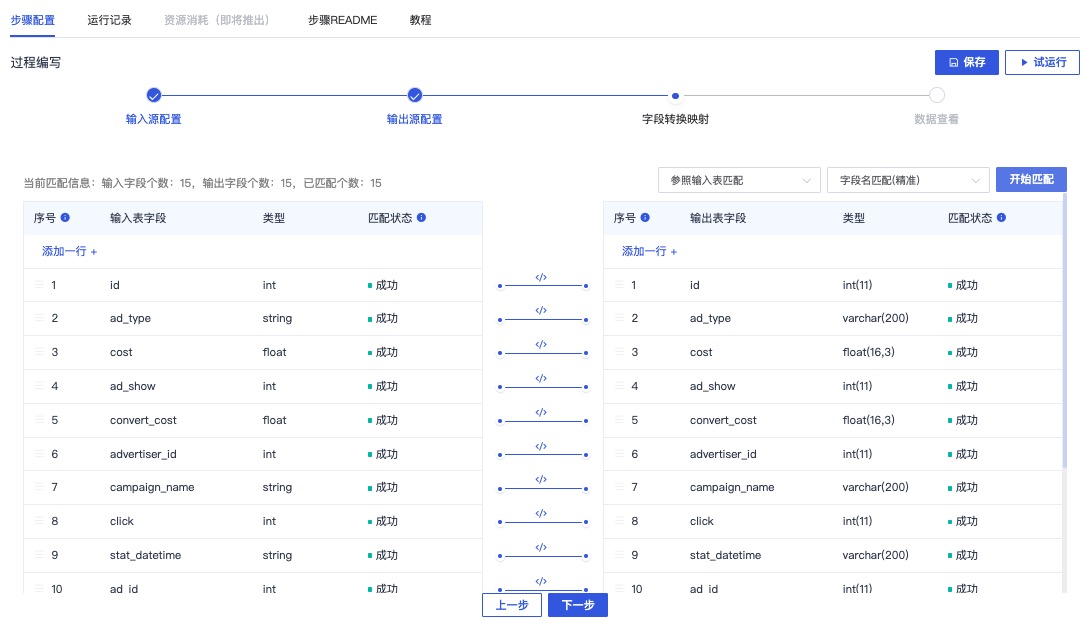
查看真实数据,点击查看
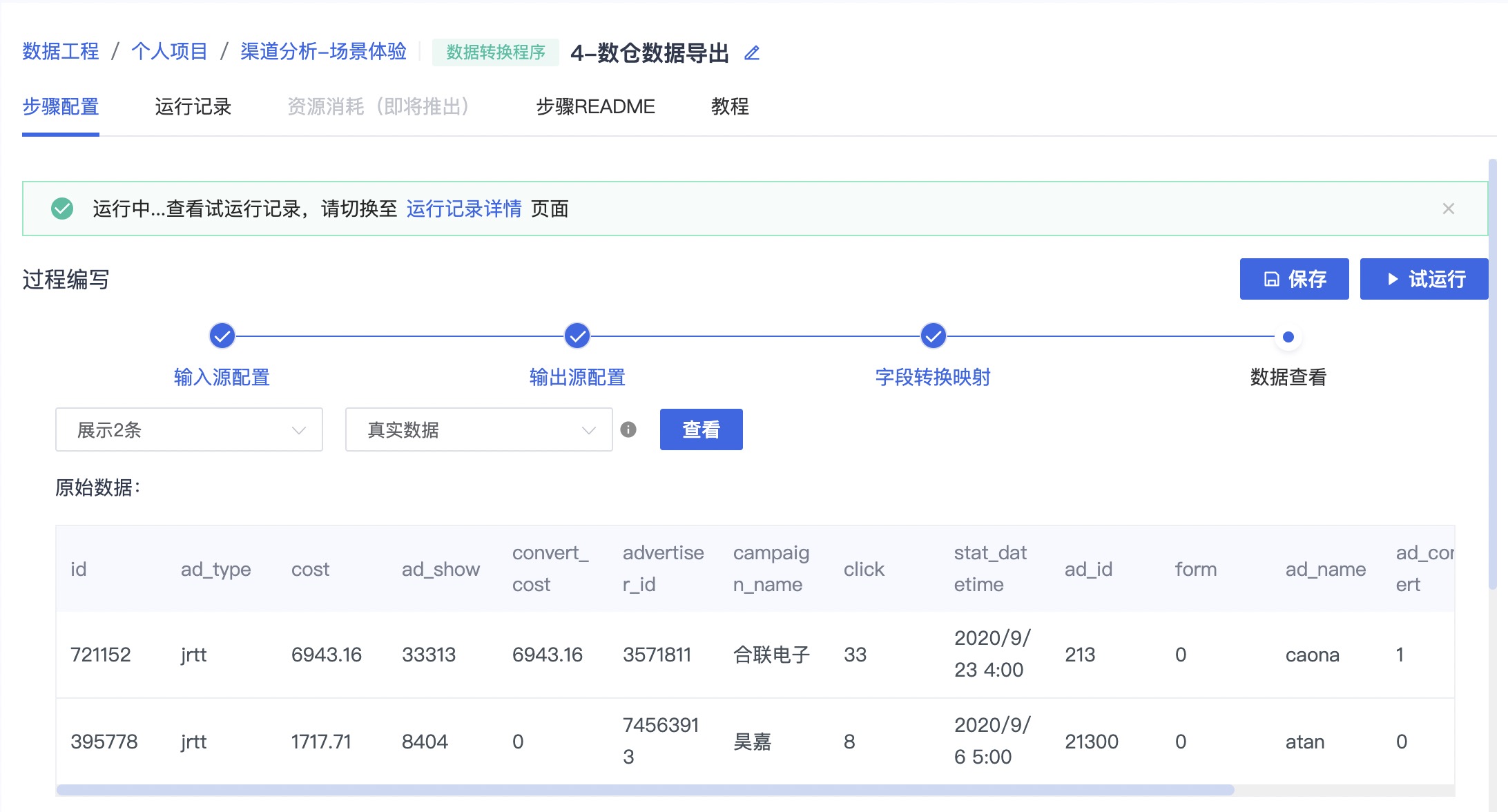
点击保存后,点击试运行
查看运行记录
查看导出到公共MySQL库的结果表

2.6 工作流与依赖视图
从项目【列表视图】Tab 切换至【工作流与依赖视图】
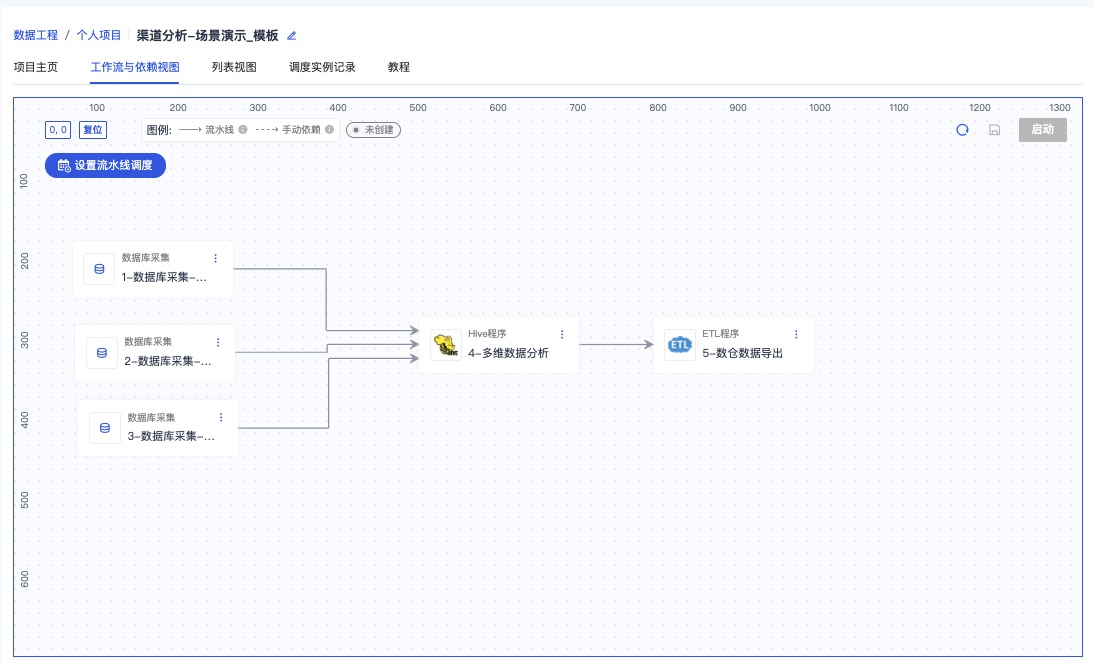
设置调度时间,启动调度后,实现关联的步骤会按顺序按时运行
注:实线为有实际依赖关系的流水线调度步骤,虚线为逻辑依赖关系,不参与调度
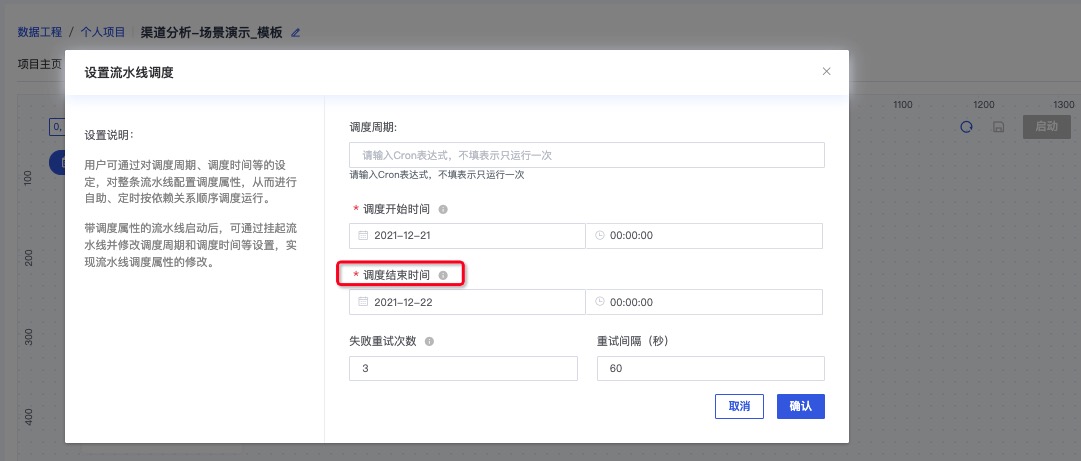
点击保存,并启动
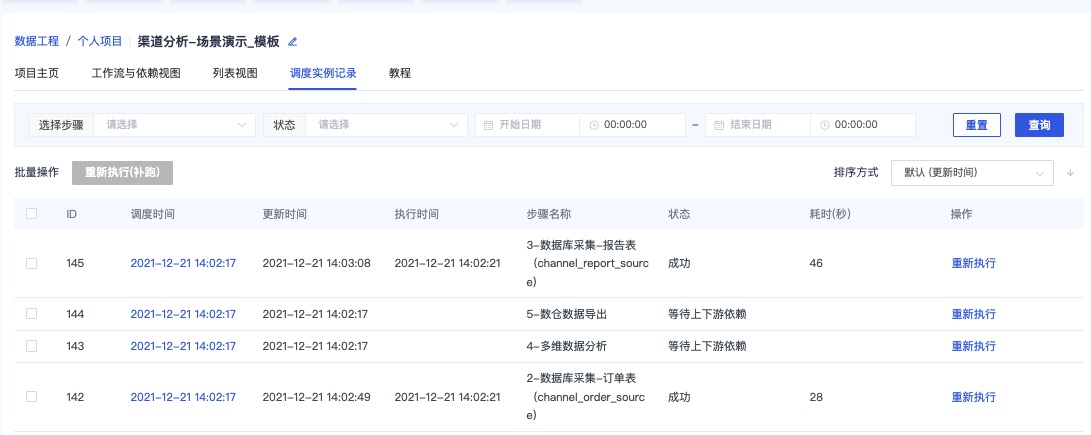
查看调度实例记录
3. 可视化展示(仅限企业账号)
用户通过导航【集成工具-机构工具进入】,点击Superset的进入工具图标,跳转至Superset主界面
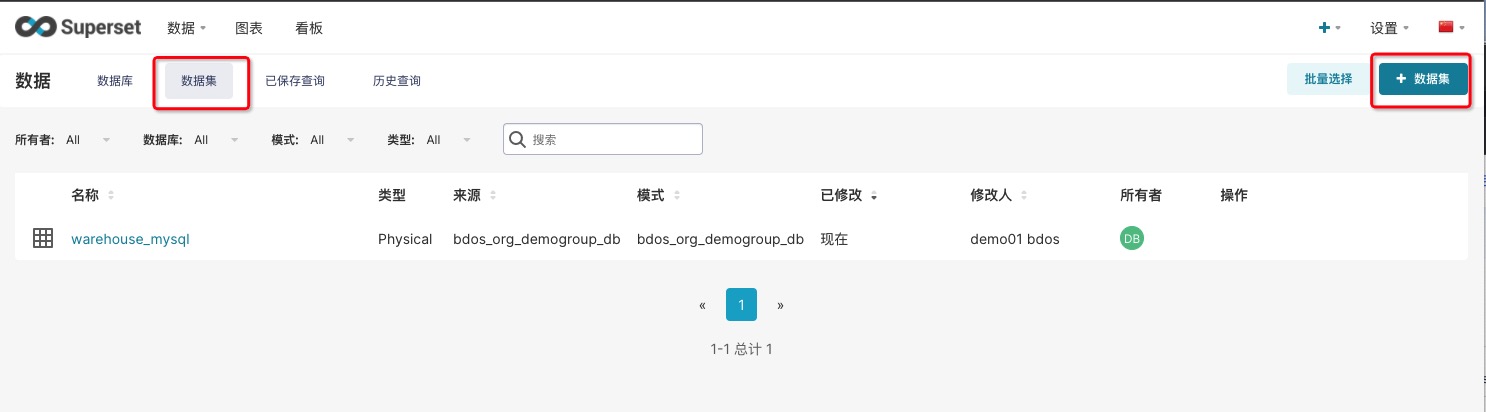
通过Superset导航【数据-数据集】进入,点击+数据集
3.1 添加数据集
| 名称 | 内容 | 描述 |
|---|---|---|
| 数据源 | public_project_data | 选择系统默认提供的MySQL公共数据源 |
| 模式 | public_project_data | 选择系统默认的Schema模式 |
| 表 | 下拉框选择 | 选择需要进行可视化展示的目标表 |

点击新增
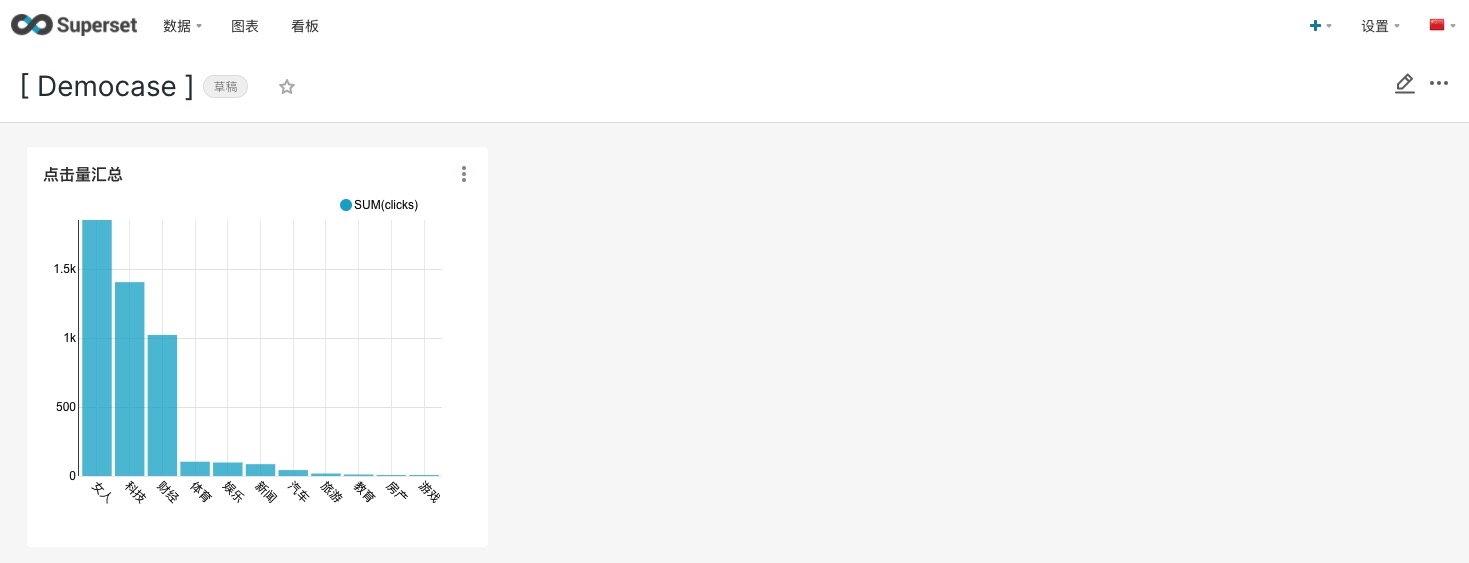
3.2 添加图表
通过菜单导航至【图表】界面,点击+图表

| 名称 | 内容 | 描述 |
|---|---|---|
| 选择数据源 | 下拉框选择 | 选择添加的目标数据集 |
| 表 | 点击选择图表类型 | 选择需要进行展示的图表类型 |
点击创建新图表
| 名称 | 内容 | 描述 |
|---|---|---|
| 指标 | count(*) | 保持默认 |
| 序列 | ad_name、ad_convert | 选择字段作为展示维度,可多选 |
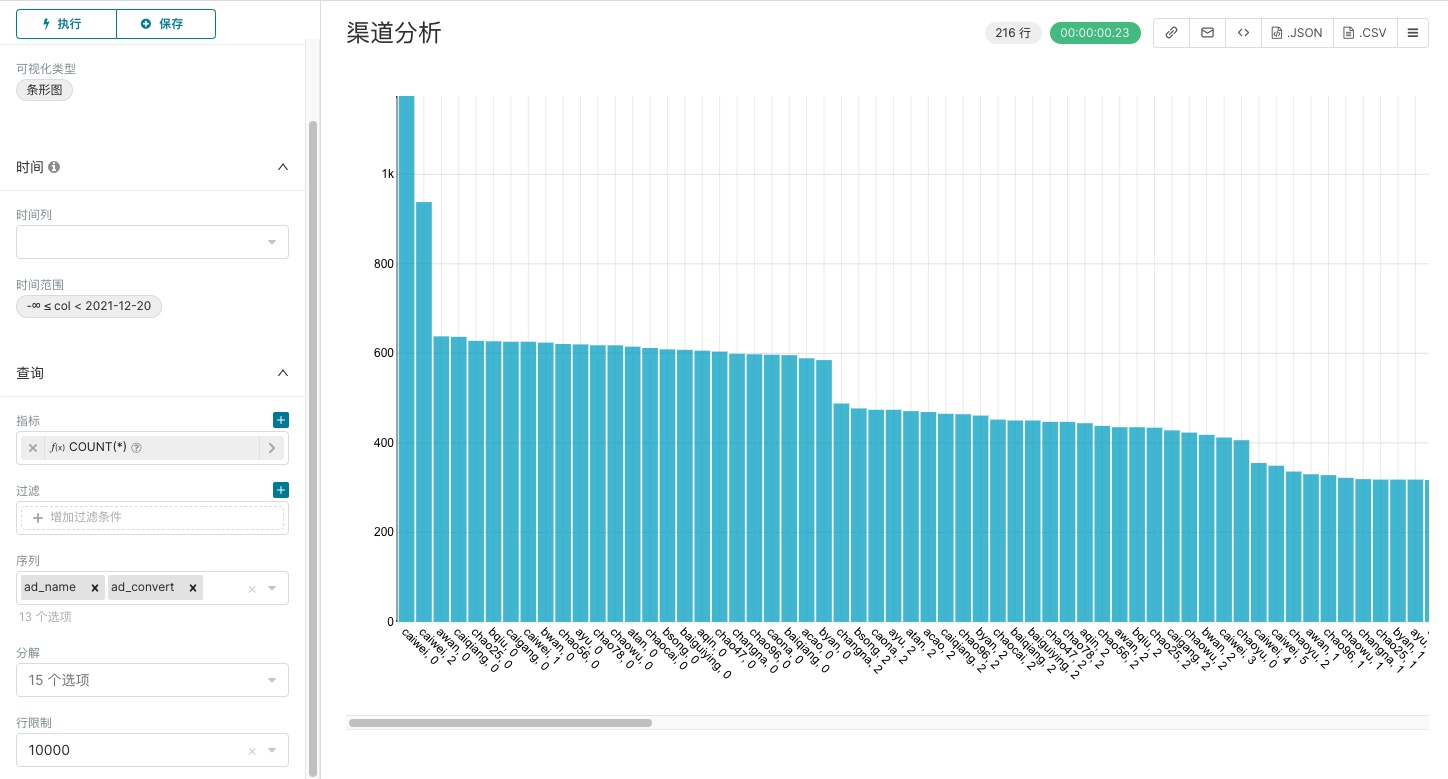
点击执行后,点击保存
3.3 添加看板
通过菜单导航至【看板】界面,点击+看板
点击编辑图标进入看板编辑界面,选择【图表】,把模板图表手动拖拽添加至左侧看板画布

点击保存
欢迎访问网站,注册体验BDOS Online,网站地址:https://bo.linktimecloud.com/

留言
评论
暂时还没有一条评论.