详解:大数据存储与索引 | 第十一期社群图文直播
智领云第十一次社群图文技术直播文字回放:本次直播由智领云大数据应用开发工程师Peter为大家带来了主题分享《大数据存储与索引》,主要内容包括:掌握大数据存储与索引的原理;OLTP和OLAP的不同设计理念;分布式数据库针对OLAP的优化;分布式数据库面临的挑战和对策。
磁盘特征
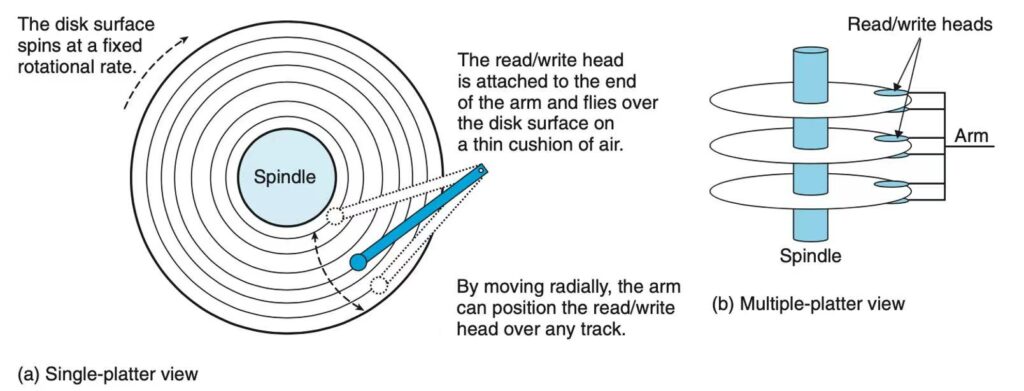
我们今天讨论的前提是:数据保存在磁盘(机械硬盘)上。所以有必要了解磁盘的特征。磁盘由盘片的摆臂组成,摆臂上的磁头用于在指定位置读写数据。进行一次读写操作时,摆臂会先移动到指定轨道,然后磁头在飞速旋转的盘片上进行顺序读写。 上图可以看到磁盘内部有多个盘片和摆臂,但所有摆臂都是一起运动的,所以磁盘同一时间只能进行一个操作:读或者写。磁盘的特征可以总结为:
- 顺序读写远快于随机读写,因为避免了频繁寻轨的操作。
- 同一时间只能进行一个操作。
SSD盘的随机读写速度相比磁盘有大幅提升,但相比它的顺序读写速度还是相差了一个数量级,所以我们接下来讨论的内容大部分也适用于SSD。
世界上最简单的数据库

我们在终端中定义两个方法:db_set() 和 db_get()。db_set() 用于写入 key-value 格式的数据,数据保存到 database 这个文件。而 db_get() 用于通过 key 读出最新的 value。
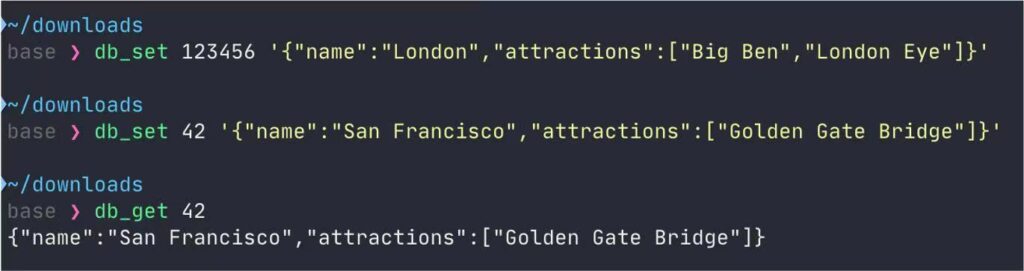
我们先写入两条 key 分别为 123456 和 42 的数据,然后读出 key=42 的数据。

我们再将 key=42 这条数据进行更新,可以看到读出的是最新值。

浏览 database 文件,发现内容是我们依次写入的三条数据。 这样我们就实现了一个最简单的数据库。因为数据是顺序写入到文件,所以这个数据库的写速度非常快。但读取数据时需要遍历整个文件,所以读取速度很慢。

为了解决这个问题,我们可以在内存中维护一个简单的哈希索引。这个索引的 key 就是每条数据的 key,value 则是每条数据的位置。这样我们便实现了快速查找。 但是这个数据库还有一个严重的问题:数据一直往文件 database 中追加,总有一天会将磁盘写满。

为了解决这个问题,我们可以如上图所示,定期对数据文件进行压缩,只保留每个 key 最新的数据。

不但可以对单个文件压缩,还可以合并多个文件,同样只保留合并后的最新数据,这样就显著降低了磁盘占用,并减少了文件碎片。
追加日志 VS 更新文件
可能有人觉得追加数据的方式有些浪费磁盘空间,直接对数据进行更新不行吗?实际上相比更新文件,追加日志的方式有以下好处:
- 追加和分段合并主要是顺序写入,比随机写入快得多。
- 如果分段文件时追加的活不可变,则并发和崩溃恢复要简单的多。
- 合并分段文件可以避免数据文件碎片化。
哈希表索引的局限性
刚才我们给数据库添加了一个简单的哈希索引,但这个索引有一些局限性:
- 哈希表必须全部放入内存。如果 key 非常多,可能会造成超出容量或哈希冲突的问题。
- 区间查询效率不高。比如查询 key 在 10000 到 20000 之间的值,需要每条数据做一次检索。
有没有办法既保留追加日志的高速写入特性,又突破哈希表的局限性呢?
如果日志数据是有序的,即数据是按照 key 升序排列,我们就不用为每条数据维护一个索引,而是可以间隔一定数量维护一条索引,这样可以显著减少索引的大小。查询时可以根据前后两条索引来定位数据。比如每100条数据维护一个索引,如果要查找 id 为 150 的数据,因为我们知道 150 在 100 和 200 之间,那么我们可以找到 id 为 100 的那条数据,然后向后顺序读取文件,直到找到 id 为 150 的那条数据。因为文件中的数据都是有序的,而且是顺序读,所以速度也非常快。
但是日志数据有序,和顺序写入似乎是矛盾的。要实现这一点需要有巧妙的解决办法。
如何构造有序的日志文件
写入数据时,我们先将数据插入内存中的一个平衡数数据结构中(比如红黑树),成为内存表。红黑树的特点是数据可以快速插入,还可以快速排序并导出。当内存表的数据量大于阈值,就将其写入到新的磁盘文件,得益于红黑树的特点,文件中的数据也是有序的。
查询时,先尝试在内存表中查找,然后是最新的磁盘文件,接下来是次新的文件。
后台进程周期性的将文件合并和压缩,并丢弃已被覆盖和删除的值。合并操作也需要保证合并后的数据是有序的。

合并时先取每一个文件的第一条数据进行比较,将最排序最靠前的数据写入新文件,然后依次比较后面的数据。如果有相同的 key,取较新文件中的数据,因为我们知道文件是顺序写的,较新文件中的数据一定是较新的。这个算法被称为 Merge Tree。
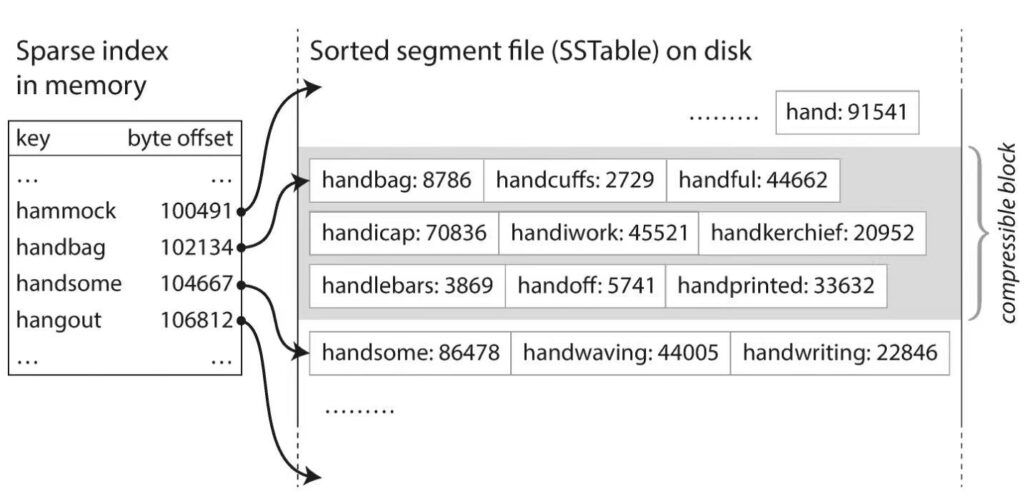
这样我们就可以用一个稀疏索引来维护数据库。有序的数据文件被称为 SSTable (Sorted segment file),而这种合并、压缩日志文件的数据引擎被称为 LSM-Tree。在大数据领域 LSM-Tree 越来越受到重视,非常多的分布式数据库都用到了 LSM-Tree.
使用最广泛的索引:B-Tree
虽然 LSM-Tree 越来越受重视,但使用最广泛的索引却是 B-Tree。几乎所有关系型数据库都使用 B-Tree 作为索引。
B-Tree 将索引划分为若干层级,每个层级包含若干个 page。最顶层的根 page 只有一个,而且相对非常稀疏,每一个索引指向一个子 page。检索时会先从根 page 开始,一层层向下查找,直到找到数据。
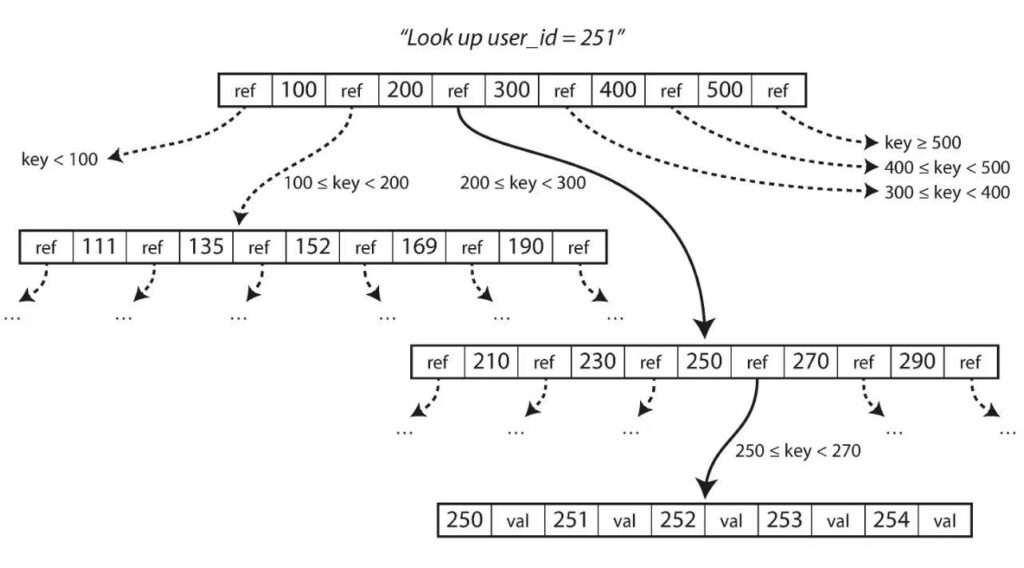
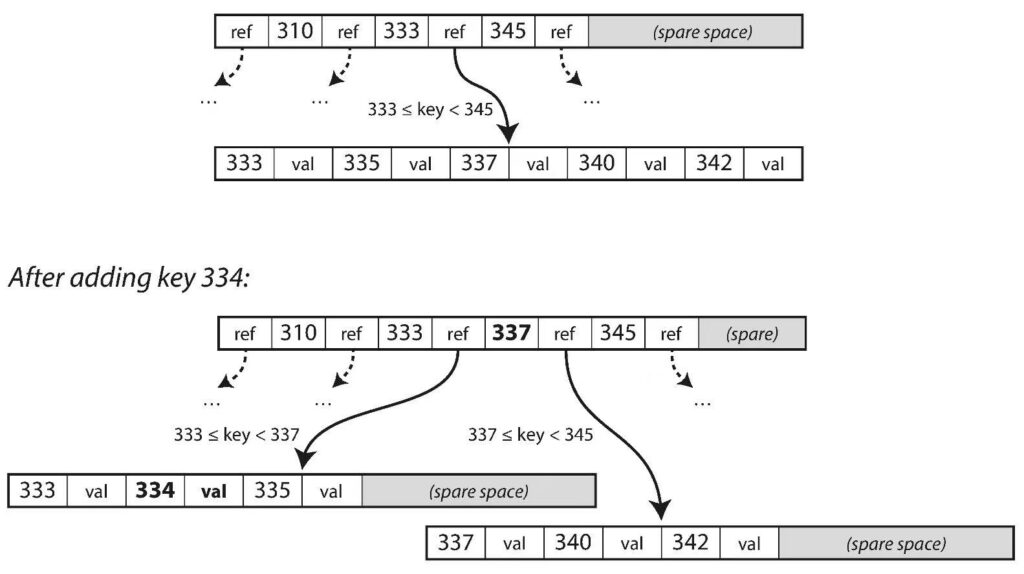
插入数据时,如果数据的 key 所在的 page 刚好满了,就要对 page 进行分裂,如上图所示。分裂是一个比较昂贵的操作,所以建表时要避免创建不必要的索引,以免插入数据时频繁分裂 page。 大体上讲,LSM-Tree 的写操作比 B-Tree 更快,因为没有分裂 page 的问题。但读操作比 B-Tree 慢,因为 LSM-Tree 在压缩合并日志文件时,是一个磁盘写操作,查询的读操作要等写操作结束才能进行。
事务处理和分析处理
数据处理大致可以分为两大类:
- OLTP,联机事务处理 On-Line Transaction Processing。OLTP 是传统的关系型数据库的主要应用,主要是基本的、日常的事务处理,记录即时的增、删、改、查,比如在银行存取一笔款,就是一个事务交易。
- OLAP,联机分析处理 On-Line Analytical Processing。OLAP 是数据仓库的核心,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。典型的应用就是复杂的动态报表系统。
上图中的 OLTP 包含了对销售、仓储、物流数据库的增删改查操作,这些数据汇总到数据仓库后,就可以进行 OLAP 操作。OLTP 和 OLAP 的差异非常大。OLTP 主要是对行操作,实施性要求比较高;而 OLAP 主要是对列进行运算,实施性要求不高。
列存储

为了提高 OLAP 列运算效率,产生了列存储数据库。上图中的每一列数据都保存在一个文件中,比如 date_key 这一列保存在 date_key file ,内容是 140102, 140102, 140102 等等。这样做有几个好处:
- 列运算时只需要读取这一列的文件,而不是像行存储一样要读整张表,相比之下速度会显著提高。
- 每一列中的数据有大量重复,这样就可以用一些算法进行列压缩,让文件更小,这样即可以提高读取速度,也能节省存储空间。
分布式系统
到目前为止我们讨论的都是单机的情况,到了分布式集群上,事情就变得更加有趣了。分布式集群会给我们带来许多显而易见的好处,比如
- 数据可以保存多个副本,以免单个节点出问题时数据丢失。
- 表可以拆分为多个分区,放在多个节点上,提高吞吐速度。
但是也带来了许多挑战。比如多副本如何保证一致,分区怎么尽量均匀,索引要怎么构建等。
复制
主从复制
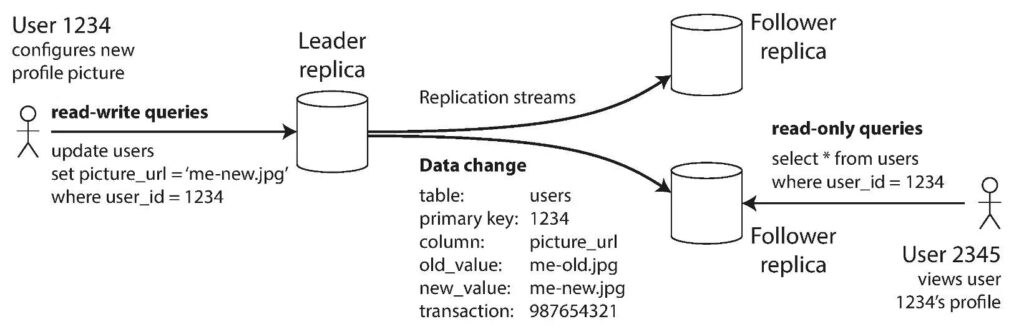
主从复制是一种相对比较常见的复制方式,大部分关系型数据库都支持主从复制。如上图所示,写入时只向主副本写,然后将数据同步到多个从副本,读取时就只在从副本读取。这样就实现了读写分离。主从复制应用非常广泛,不仅在数据库,其他系统比如 Kafka 也采用了主从复制。
多主复制

如果客户分布在全球各地,可能会考虑在全球建立多个数据中心,以提供比较好的网络速度。这时每个数据中心都有自己的主副本和从副本。数据写入主副本,同步到从副本后,还需要同步到其他数据中心。同步到其他数据中心时就可能面临数据冲突的问题。所以多主复制比主从复制要复杂很多,如果只有一个数据中心,一般不采用多主复制。
无主复制

无主复制采用了一种完全不同的设计理念:没有主从之分,读写都要同时访问多个副本。如上图所示,写入时同时向多个副本写,如果其中一个写失败了,不用管。读取时同时从多个副本读,如果发现不同副本的数据不一致,那么需要更新版本号较低的数据。这种策略被称为读时修正。后台也可以运行一个程序,定时检查所有副本数据,如果发现有不一致就进行同步。
分区
我们可以将一张表拆分成多个分区,放在多个节点上。每一条数据只属于某个特定分区,每个分区都可以视为一个完整的小型数据库。分区的主要挑战是,数据如何均匀的分布在各个节点上。
基于关键字区间分区
想象数据存放在一套百科全书中,并且按字母排序。百科全书每一本覆盖不同字母序,并且页数非常接近。注意第一本只涵盖了 A 到 B 两个字母开头的条目,最后一本涵盖了 T 到 Z 7 个字母的条目,这是因为 T 到 Z 开头的单词相对比较少。基于关键字区间的分区与此类似,我们首先要了解数据特点,知道大致的分布情况,然后设计好每个分区涵盖哪些关键字,尽量让每个分区的数据量保持接近。
基于关键字哈希值分区
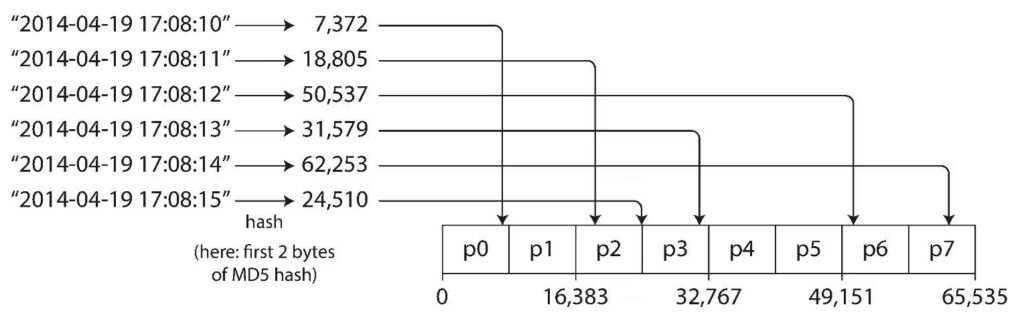
也可以给每个关键字计算一个哈希值,然后依据哈希值放入不同分区。这样做的好处是数据分布非常均匀,坏处是无法高效进行区间查询。
折中策略
有一种折中策略是用多个列组成复合主键,复合主键只有第一部分用于哈希分区,其他列作为组合索引进行排序。这种策略在特定场景非常有用。比如类似微博的系统,用 user_id 和 每一条微博的时间戳 组成复合主键,user_id 用于哈希分区,时间戳用来排序,这样就能非常高效的查询到某一个用户在一个时间段内的所有微博。
分区与二级索引
数据库中除了主键,我们还会根据业务需要创建二级索引来满足查询的需要。在分布式数据库中,我们要考虑创建本地索引还是全局索引。
本地索引
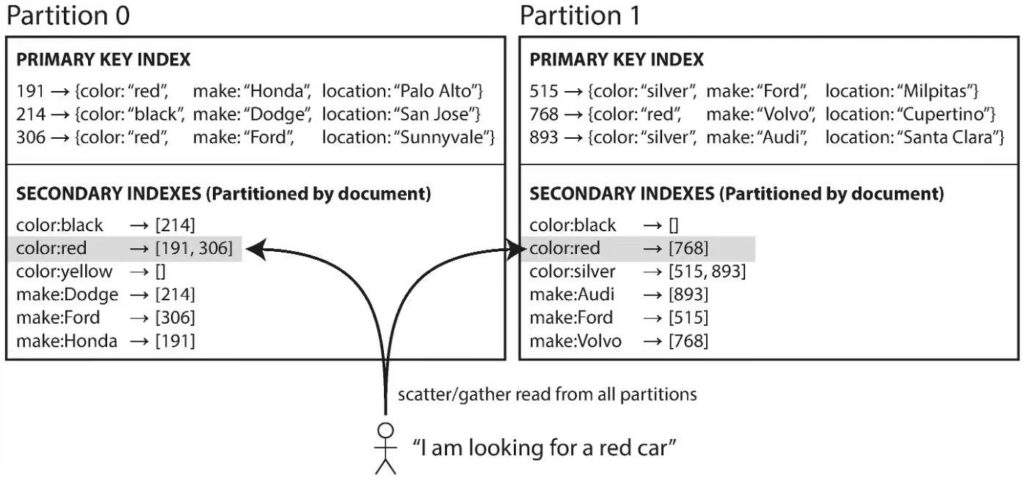
上图数据库保存了车辆信息,包含了颜色、制造商、所在地。除了主键,还创建了颜色和制造商的二级索引。可以看到每一个分区都有自己的二级索引,维护本分区的数据,这叫做本地索引。如果要查询所有红色的车辆,需要在每个分区进行查询,再将结果汇总。本地索引是为写进行优化,写入数据时只需向主键所在分区进行写操作。而读取时需要查询所有分区,相对比较慢。
全局索引
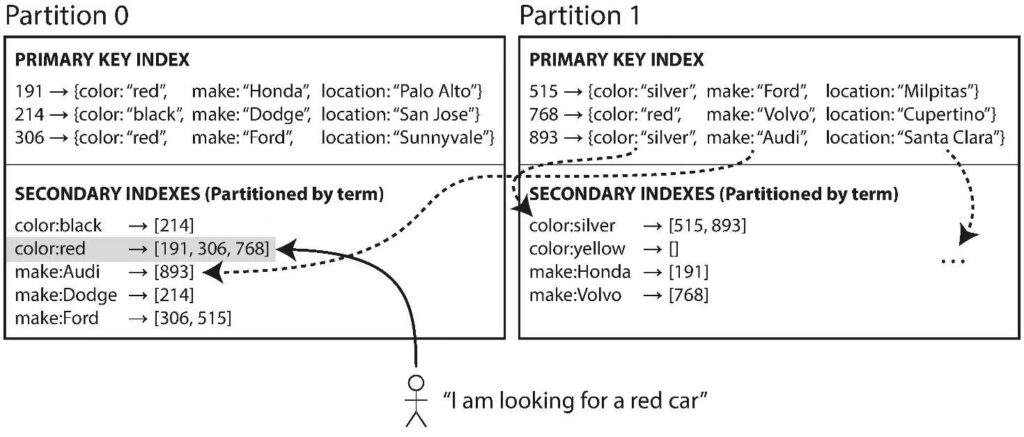
上图是同样的数据,创建了全局索引。注意全局索引本身也是要分区的,所以分布在两个分区上,但红色车辆的索引全都在第一个分区。全局索引是为读进行优化,查询红色车辆只需要读第一个分区。但写入一条数据可能需要更新多个分区的索引,相对比较慢。
总体来讲,如果需要高速写,就选择本地索引;如果需要高速读,就选择全局索引。
留言
评论
暂时还没有一条评论.