大数据平台智能异常检测系统介绍 | 第十二期社群图文直播
智领云第十二次社群图文技术直播文字回放:本次直播由智领云大数据后台开发工程师Jerry,为大家带来了主题分享《大数据平台智能异常检测系统介绍》,主要内容包括:异常检测智能化的业务需求背景;系统的架构设计;系统的核心功能与业务流程。
智能异常检测产生的需求背景
什么是异常检测? 异常检测是识别数据集中与标准不同的异常数据或事件的过程,不同于常规模式下的问题和任务,异常检测针对的是少数、不可预测或不确定、罕见的事件,它具有独特的复杂性。 异常的特点
- 异常数据跟样本中大多数数据不太一样
- 异常数据在整体数据样本中占比比较小
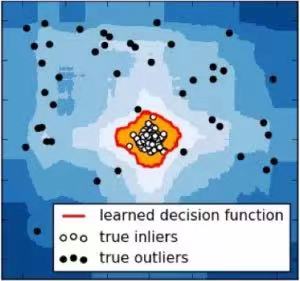
上图是通过聚类机器学习的方法,将某个指标序列进行分类后的数据点分布。其中,少量的异常点(黑色)与正常的点分离的较远,绝大多数正常的数据点聚集在中间小块区域。 异常的分类
- 异常值(Outlier)
- 波动点(Change Point)
- 异常时间序列(Anomalous Time-series)
为什么要进行智能异常检测?
传统的异常检测面对的业务场景是少量的检测指标,短期内检测数据量级不高。在大数据时代,大数据平台上的业务系统和业务组件产生的业务指标量级呈现爆发式增长,传统通过人工配置阀值的指标监控方式,已经无法满足实际的业务需求,大数据系统中需要使用机器学习和数据挖掘技术进行自动化的异常检测。
- 大型集群中存在大量的硬件故障和软件错误
- 系统要求7×24小时运行,进行持续监控至关重要
- 需要不间断地监视大量时间序列数据,以便检测潜在的故障或异常现象
- 大型集群中系统异常或软件bug数量巨大,传统通过人工规则配置的方式几乎不可能
- 系统的复杂性导致异常产生的原因是多维度的,单维度或低维度的检测方式会导致告警误报或重复报警的概率激增
- 监控数据体量的变化,导致异常检测系统从指标采集到分析处理均要以分布式计算的方式进行
系统的架构设计
智能异常检测系统是一个标准的大数据流水线处理系统,包括数据采集、数据处理、数据展示三大核心流程。 海量指标采集、指标统计特征计算与机器训练与预测等计算密集型任务,要求系统的数据采集和数据处理是基于分布式计算,存储和计算资源可以动态扩展。 系统支持对采集的指标数据进行图形化展示,用户可以通过图形界面化的方式对系统的检测结果进行标记。 系统支持将指标检测的结果数据输出到告警系统。 系统支持以插件的方式对算法进行扩展。
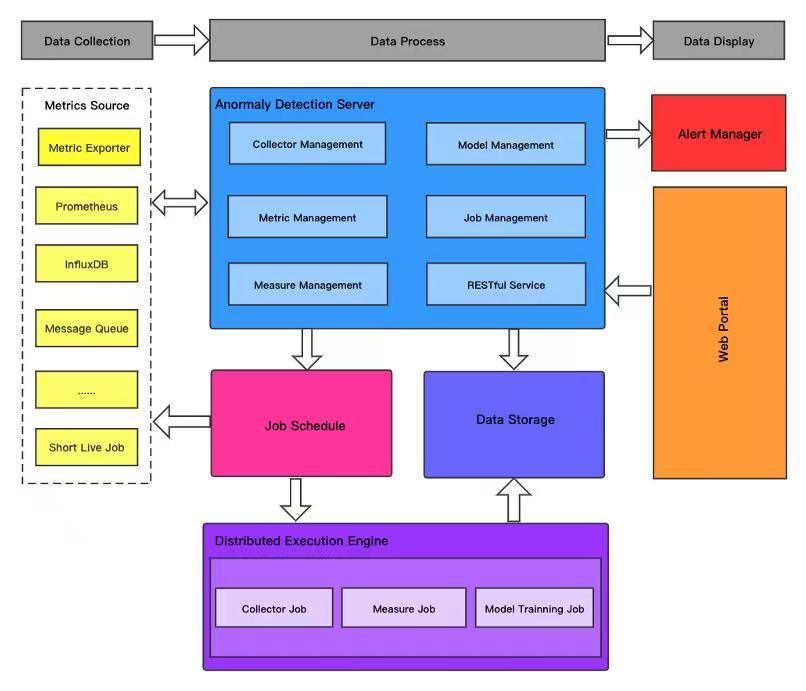
- Anomaly Detection Server主控服务是整个系统平台的控制中枢,主要包括数据源管理,数据采集管理,指标检测管理、指标元数据管理、程序管理、算法模型管理以及其他的可视化服务接口。用户可以通过Rest API或web界面系统,完成系统核心流程的管理。
- Distributed Execution Engine分布式执行引擎是平台的数据采集和指标检测任务的执行平台,调度系统或流处理服务会将批处理任务、流任务分发到引擎上执行。采用分布式计算引擎的优势时,系统中的采集任务或检测任务的资源和性能由分布式计算引擎支撑,充分利用分布式引擎具备资源扩展灵活、高可用等特点。
- Metric collect artifact采集程序包,提供常见的指标数据源的采集功能,如metric exporter,prometheus,InfluxDB,Message Queue,Rest IO,short live Job等。该模块可以根据用户的实际需求,进行扩展开发。它作为一种独立的程序包类型,在系统平台上进行管理。
- Measure artifact检测程序包,包括了平台的核心检测功能流程,算法模型插件功能、算法模型自动化路由插件功能。
- Data Storage数据存储包括系统元数据的存储,指标数据的存储,模型训练数据的存储,它可能是例如mysql,es,HDFS等数据存储系统的集合。
- Job Schedule任务调度组件主要负责编排要在分布式执行引擎上运行的作业。主控服务会与其进行交互,注册作业并跟踪作业的执行状态。
- Web Portal用户需要可视化高频操作的入口。
- Alert Manager警报管理器将处理异常检测系统的告警,并通过发送电子邮件或其他方式推送异常检测告警信息。
系统的核心功能与业务流程
1、系统功能
程序管理:创建、编辑采集程序、检测程序、自定义算法插件程序 算法模型管理:创建、编辑系统内置算法和自定义插件算法 指标源管理:创建、编辑数据源,系统会采集指标数据和指标元数据信息 指标检测管理:选定数据源,创建、编辑算法模型检测和规则检测,系统运行检测任务,根据检测结果产生告警 指标趋势图管理:显示采集的原始指标和检测结果指标趋势图,对数据点进行异常标记反馈 告警管理:告警路由、告警分组、告警静默、告警漏报、误报标记
2、业务流程
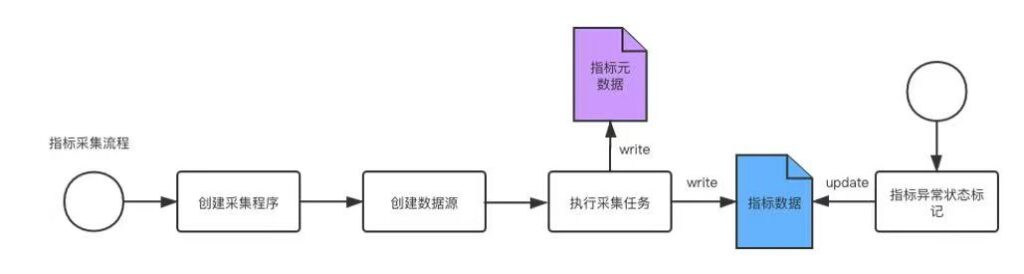
指标采集
- 用户通过web系统创建数据源,选择采集程序版本
- 主控系统向调度组建提交采集任务
- 调度系统周期性执行指标采集任务,将指标元数据存储至元数据存储系统,并将采集的指标序列数据存储至时许数据库
- 用户通过web界面以图表化的方式对采集的指标数据进行主动标记,标记的状态最终会反馈到机器学习算法的模型训练,进行模型的迭代优化
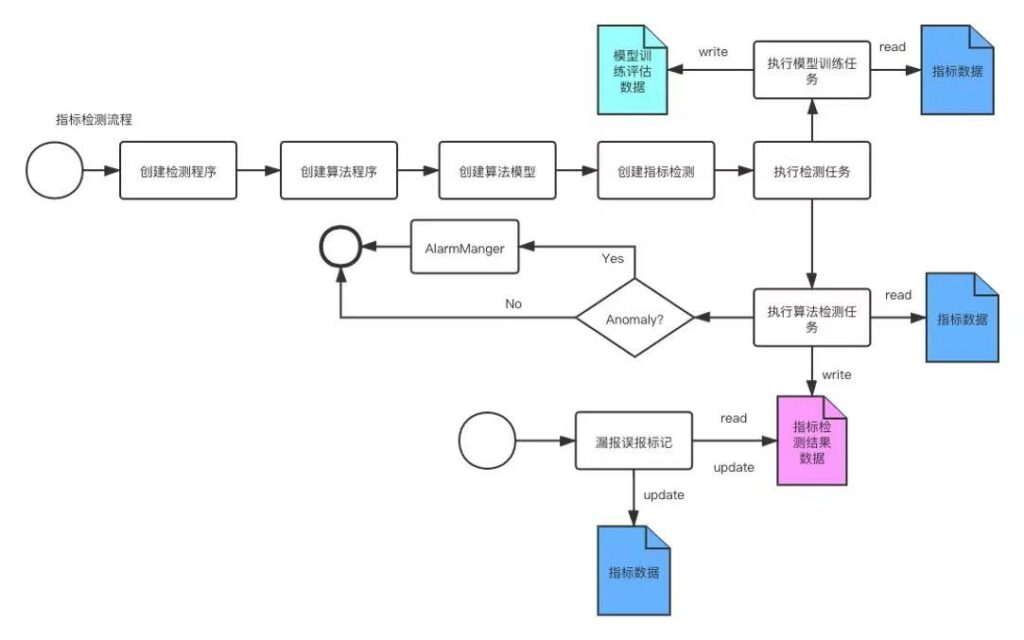
算法检测
- web系统上使用系统内置的算法模型程序或用户上传自定义的算法插件程序,创建算法模型
- web系统上创建指标检测,主控系统向调度系统注册检测任务,调度系统周期性执行检测任务
- 创建指标检测时,主控系统同时会创建一个周期性模型训练任务,调度系统周期性执行模型训练任务,并输出模型训练评估数据
- 算法检测任务执行时,加载最新训练的模型数据,预测指标的异常值,如有异常,向告警系统发送检测告警,并将指标检测的结果数据输出到数据存储系统
- 用户通过web系统对算法检测的结果数据,进行漏报误报标记,标记数据将反馈到下一轮模型的迭代训练优化中。
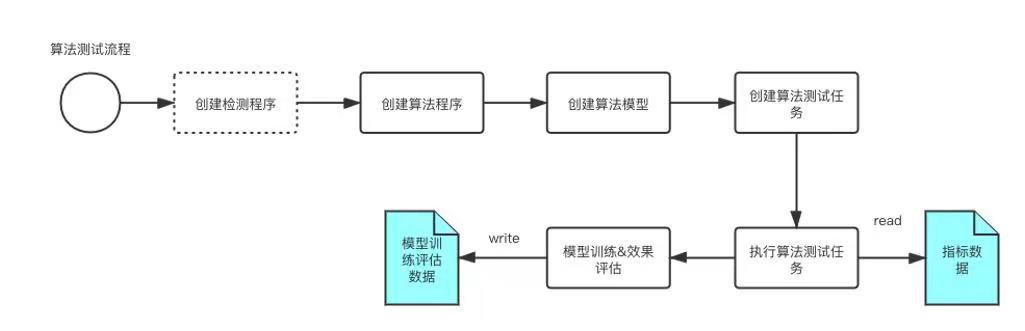
算法测试
- web系统上使用系统内置的算法模型程序或用户上传自定义的算法插件程序,创建算法测试
- web系统上创建指标检测,主控系统向调度系统注册检测测试任务,调度系统执行一次性的检测任务
- 创建指标检测时,主控系统同时会创建一个模型训练任务,调度系统执行模型训练任务,并输出模型训练测试的评估数据
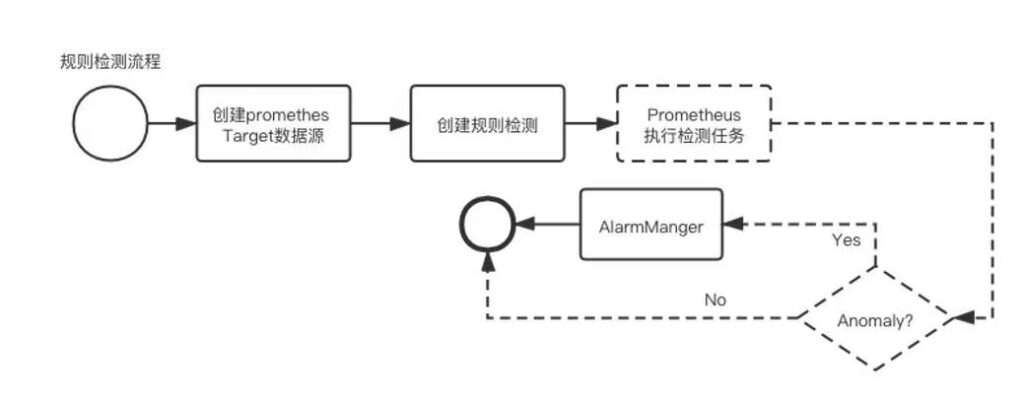
规则检测
系统在提供算法模型检测的同时,对于判断规则简单明确的指标检测,提供以prometheus为基础的规则检测:
- web系统上创建prometheus数据源
- web系统上创建基于prometheus的规则检测
- prometheus处理规则检测任务,并将告警数据输出到告警系统
算法模型自动路由
智能异常检测系统平台以插件化的方式支持算法的扩展,系统提供了内置的常用的机器学习算法,如MAD, iForest,Kmeans,LOF,LSTM等,由于不同行业不同业务领域,其指标数据的特征各不相同,用户可以基于平台提供的算法插件接口,自定义开发适合自身业务的机器学习算法,并通过平台定义的标准化异常检测闭环流程,完成各种指标数据的异常检测。
同时,平台基于内置的算法模型(未来会持续研发扩展),对指标的类型进行自动探测,通过前置的异常波形预测过滤,时序指标数据的统计特征值分析,初步筛选出候选的算法模型集合,对后续集合进行模型训练及参数优化,最终自动选择出最优化的指标检测算法。
总结
本次分享介绍了智能异常检测在大数据时代产生的业务背景,并对系统的架构设计、系统功能、核心流程进行了讲解。智能异常检测系统平台定义了一套标准化的指标异常检测流程,从数据采集、数据处理、数据展示整个数据闭环进行流程化处理。
系统平台的自定义算法插件模块,使得业务域用户只需关注自身的指标检测算法的实现,对于数据的采集、模型的迭代训练与指标预测、异常监控告警,均由平台自动化处理。
算法模型自动路由是系统平台走向高阶智能化的必由之路,算法集合的增长,导致算法的选择优化和指标规则阀值配置一样,无法大规模人工处理。
如何做到算法模型自动路由的智能化是智能异常检测平台未来迭代的目标和方向。
留言
评论
${{item['author_name']}} 回复 ${{idToContentMap[item.parent] !== undefined ? idToContentMap[item.parent]['author_name'] : ''}}说 · ${{item.date.slice(0, 10)}} 回复
暂时还没有一条评论.