机器学习,为什么如此重要?| 第十五期社群图文直播
智领云第15次社群图文技术直播文字回放:本次直播由智领云大数据应用开发工程师 Peter,为大家带来了主题分享《机器学习,为什么如此重要?》,主要内容包括:什么是机器学习、机器学习分类、机器学习的主要挑战,以及一些真实案例。
在介绍机器学习之前,首先我来给大家分享一篇划时代的论文,2006年,Geoffrey Hinton等人发表了一篇论文,展示了如何训练能够高精度(>98%)识别手写数字的深度神经网络。他们将这种技术称为“深度学习”。
在当时,深度神经网络的训练被普遍认为是不可能的。这篇论文重新激起了科学界的兴趣。不久之后,许多新的论文展示了深度学习不仅是可行的,而且能取得令人瞩目的成就。大数据、高性能硬件和新的算法,一同推动机器学习快速发展。

那么,什么是机器学习呢?
1959年Arthur Samuel将它定义为“机器学习研究如何让计算机不需要明确的程序也具备学习能力”
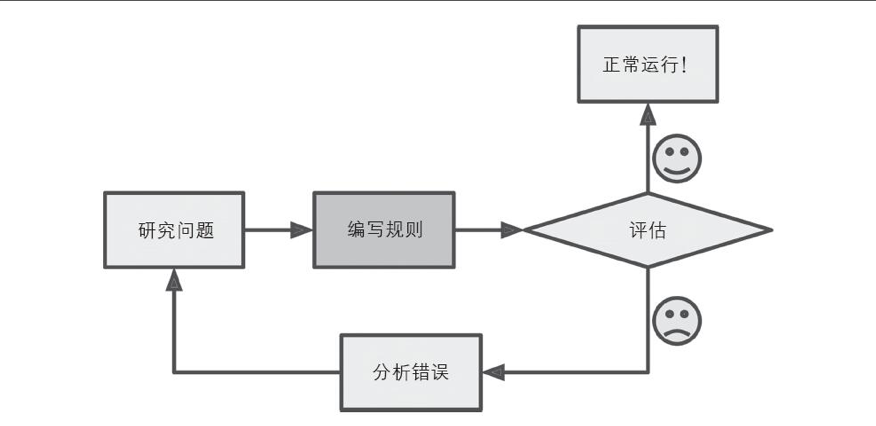
传统编程方法
如果用传统编程技术来编写一个垃圾邮件过滤器,你会怎么做?
1、看看垃圾邮件长什么样。可能会注意到某些词汇出现的频率非常高,比如“免费”,“低息”,“抵押”等,也许还会发现一些其他模式。
2、为每个模式编写检测算法。
3、测试这个程序,不断重复1和2。
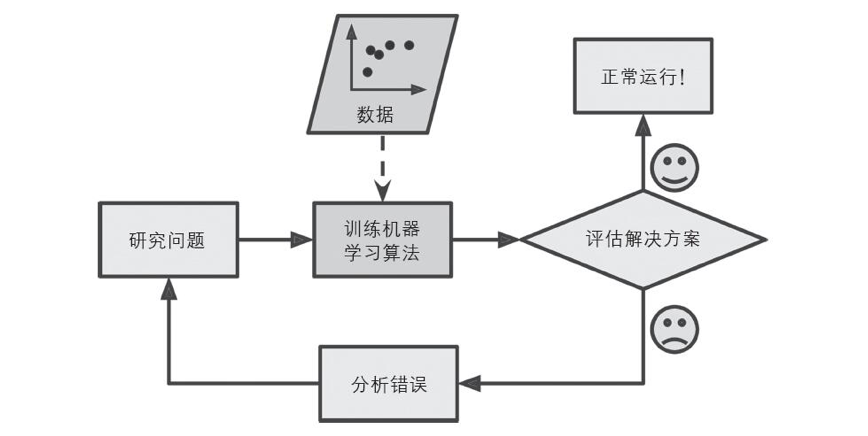
机器学习解决方法
*自动检测异常频繁的词汇
*自动学习哪些词汇可以作为垃圾邮件的预测因素
*易于维护
*更准确
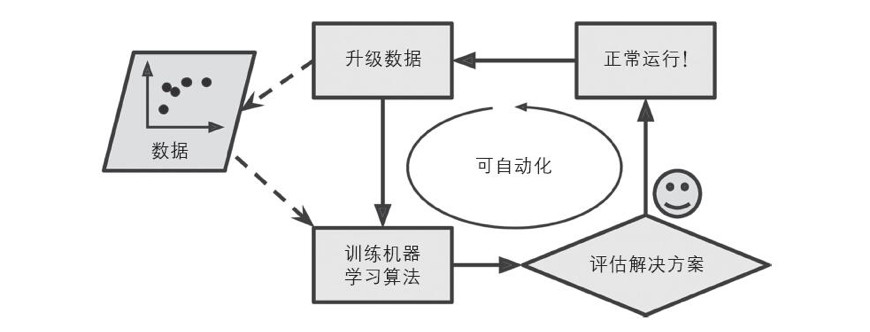
自动适应变化
*自动注意到新的关键词
*可以处理传统方法难以解决的问题,比如语音识别。
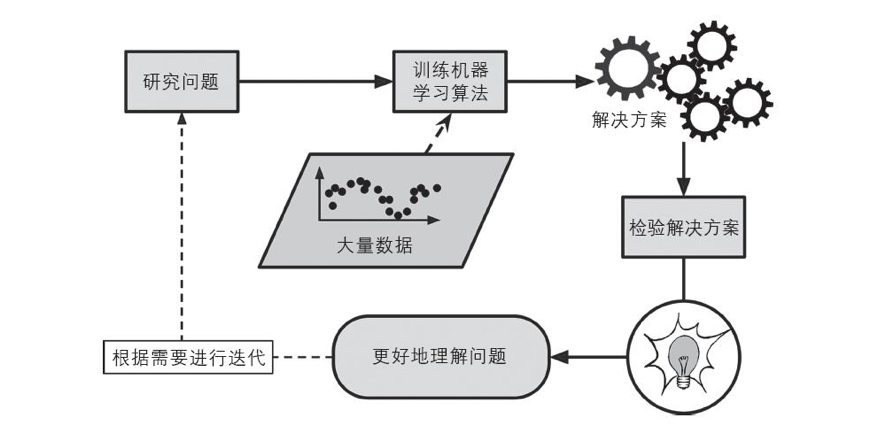
帮助人类学习
可以通过检视机器学习算法以了解它们学到了什么。
比如查看可以作为垃圾邮件最佳预判因子的词汇。
有时候,这可能会揭示出人类未曾意识到的关联性或是新趋势。
应用机器学习技术来挖掘数据,可以帮助我们发现此前并非显而易见的模式。这个过程称为数据挖掘。
机器学习分类
*监督式学习
*无监督式学习
*半监督式学习
*强化学习
监督式学习/无监督式学习
在监督式学习中,提供给算法的训练数据是经过标记的,相当于有了题目和答案,寻找解题过程。
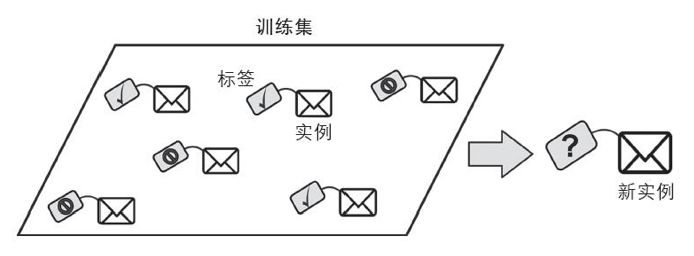
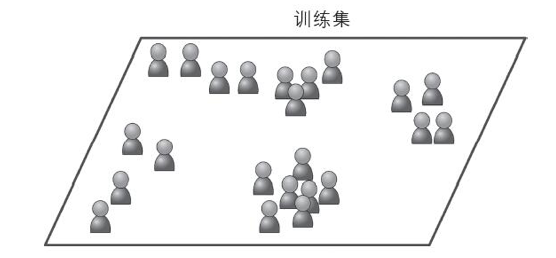
无监督式学习的训练数据都是未经标记的。系统会在没有答案的情况下进行学习。
半监督式学习/强化学习
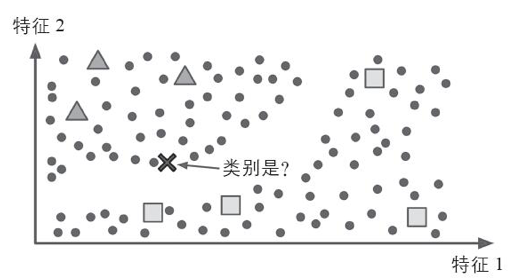
半监督式学习可以处理部分标记的训练数据——通常是大量未标记数据和少量标记数据。例如云相册。
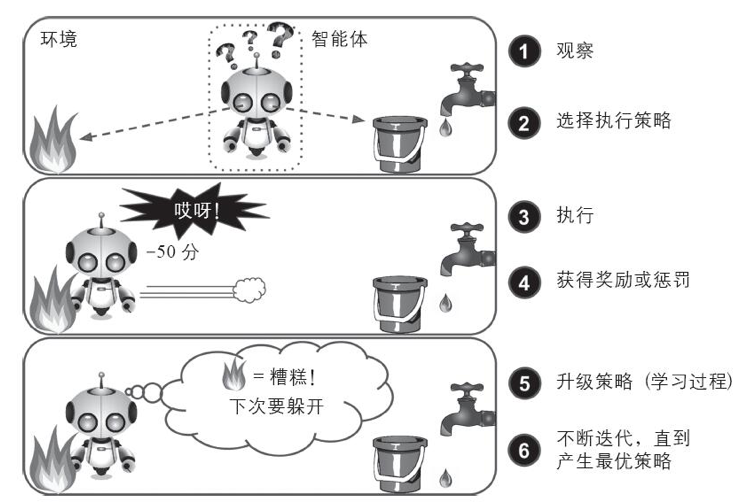
强化学习能够观察环境,做出选择,执行操作,并获得回报,或者是以负面回报的形式获得惩罚。所以它必须自行学习什么是最好的策略。例如AlphaGo。
监督式学习算法:
*K-近邻算法
*线性回归
*逻辑回归
*支持向量机
*决策树和随机森林
*神经网络
无监督式学习算法
*聚类算法
*k-平均算法
*分层聚类分析
*最大期望算法
*可视化和降维
*主成分分析
*核主成分分析
*局部线性嵌入
*关联规则学习
测试与验证
如何对模型进行评估?
将数据分割成两部分:训练集和测试集。
用训练集的数据来训练模型,然后用测试集的数据来测试模型。
通常使用80%的数据进行训练,20%来做测试。
线性回归
相比凉爽的天气,蟋蟀在较为炎热的天气里鸣叫更为频繁。右图是每分钟虫鸣声与温度的关系。此曲线图表明温度随着鸣叫声次数的增加而上升。
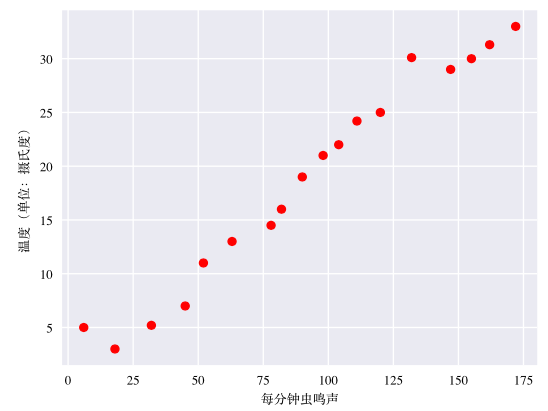
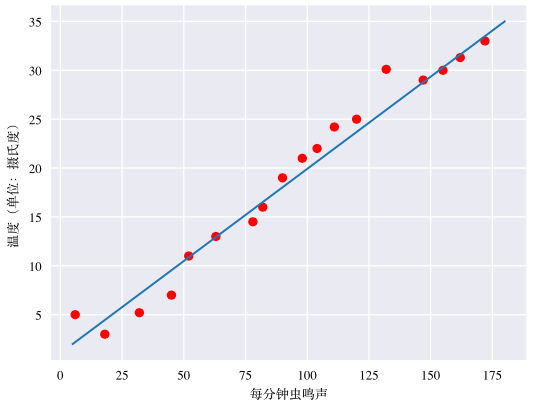
鸣叫声与温度之间的关系是线性关系吗?是的,我们可以绘制一条直线来近似地表示这种关系。
这条直线可以用线性代数表示:
y = mx + b
y 指的是温度,即我们试图预测的值
m 指的是直线的斜率
x 指的是每分钟的鸣叫次数,即输入特征的值
b 指的是 y 轴的截距
在机器学习领域,需要写一个存在细微差别的模型方程式:
y^′=b+ w_1x_1
其中:
y’ 指的是预测标签(理想输出值)
b 指的是偏差(y轴截距)
w1 指的是特征1的权重
x1 指的是特征(已知输入项)
如果有多个特征,比如三个特征的模型可以采用以下方程式:
y^′=b+ w_1x_1+w_2x_2+w_3x_3
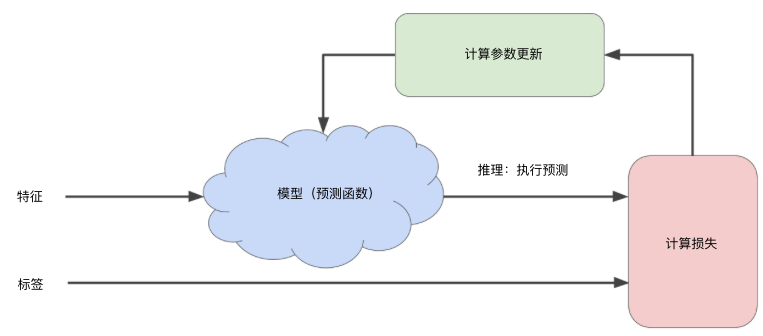
在监督式学习中,机器学习算法通过以下方式构建模型:检查多个样本并尝试找出可最大限度地减少损失的模型;这一过程称为经验风险最小化。损失是一个数值,表示对于单个样本而言模型预测的准确程度。训练模型的目标是从所有样本中找到一组平均损失“较小”的权重和偏差。
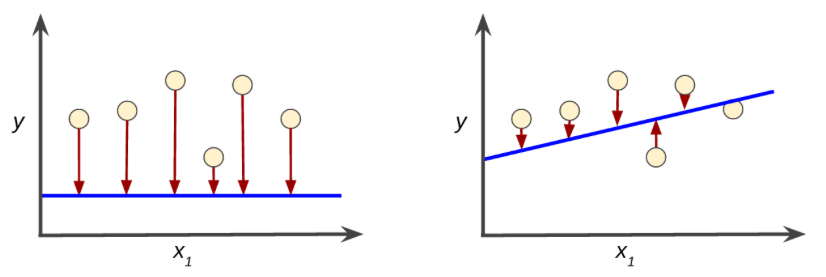
降低损失
刚开始,您会胡乱猜测(“ w1的值为 0”),等待系统告诉您损失是多少。然后,您再尝试另一种猜测(“ w1的值为 0.5”),看看损失是多少。
真正棘手的地方在于尽可能高效地找到最佳模型。
梯度下降法
对于我们研究的回归问题,所产生的损失与 w1 的图形始终是凸形。换言之,图形始终是碗状图。
凸形问题只有一个最低点;即只存在一个斜率正好为 0 的位置。这个最小值就是损失函数收敛之处。
梯度下降法可以快速找到最低点。
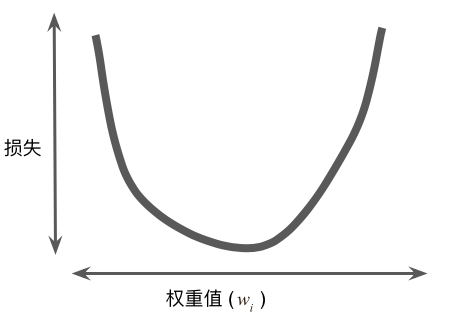
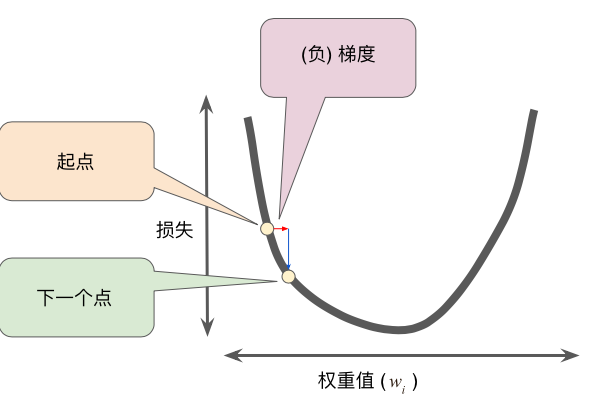
先随机选一个起点。梯度下降法算法会计算损失曲线在起点处的梯度。简而言之,梯度是偏导数的矢量;它可以让您了解哪个方向距离目标“更近”或“更远”。
学习速率
逻辑回归
逻辑回归可以解决分类问题,比如判断是否是垃圾邮件。
S型函数生成的输出值正好落在0和1之间。
y^′=1/1+e^−(z)
其中:
y’ 是逻辑回归模型针对特定样本的输出
z 是 b+w_1x_1+w_2x_2+…w_Nx_N
w是该模型学习的权重,b是偏差
x是特定样本的特征值

支持向量机
支持向量机是一个功能强大并且全面的机器学习模型,它能够执行分类、回归,甚至是异常检测任务。
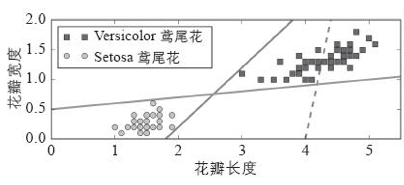
下图显示了三种可能的线性分类器的决策边界。虚线代表的模型表现非常糟糕,其余两个模型的表现在这个训练集上堪称完美,但它们的决策边界与实例过于接近,导致在面对新实例时,表现可能不太好。
下图的实线代表支持向量机的决策边界,这条线不仅分离了两个类别,并且尽可能远离了最近的训练实例。你可以将支持向量机视为在类别之间拟合可能的最宽的街道。
支持向量机
支持向量机也能解决回归问题,其诀窍在于将目标反转一下:尽可能让更多的实例位于街道上。

决策树
决策树也是一种多功能的机器学习算法,可以实现分类和回归任务。决策树同时也是随机森林的基本组成部分。
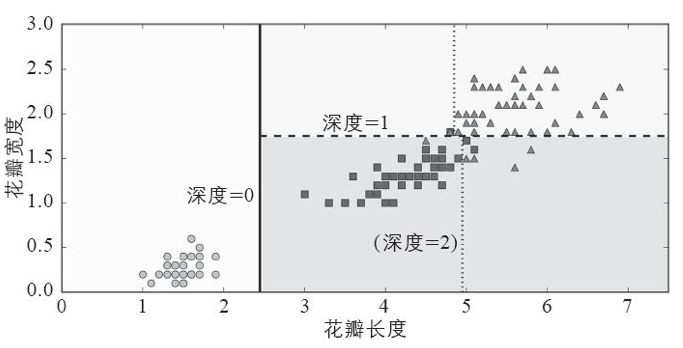
如果你找到了一朵鸢尾花,想要将其归类,那么从根节点(深度0,位于顶部)开始:
花瓣长度是否小于2.45厘米?
花瓣宽度是否小于1.75厘米?
下图是决策树的决策边界。决策树是非常直观的,它们的决策也很容易解释,这类模型被称为白盒模型。
与之相反的,随机森林或是神经网络被认为是一种黑盒模型。它们能做出很棒的预测,但很难解释清楚它们为什么做出这样的预测。而决策树提供了简单好用的分类规则,需要的话,你甚至可以手动应用这些规则。
机器学习的主要挑战
1、训练数据的数量不足
大部分机器学习算法需要大量的数据才能正常工作。即使是最简单的问题,很可能也需要成千上万个示例,而对于诸如图像或语音识别等复杂问题,则可能需要上千万个示例。
2、训练数据不具代表性
为了很好地实现泛化,至关重要的一点是,对于将要泛化的新示例来说,训练数据一定要非常有代表性。
3、质量差的数据
如果训练集满是错误、异常值和噪声(例如,差质量的测量产生的数据),系统不太可能表现良好。所以花时间来清理训练数据是非常值得的投入。事实上,大多数数据科学家都会花费很大一部分时间来做这项工作。
例如:如果某些实例明显是异常情况,要么直接将其丢弃,要么尝试手动修复错误。
如果某些实例缺少部分特征(例如,5%的顾客没有指定年龄),你必须决定是整体忽略这些特征,还是忽略这部分有缺失的实例,又或者是将缺失的值补充完整(例如,填写年龄值的中位数)
4、无关特征
只有训练数据里包含足够多的相关特征,以及较少的无关特征,系统才能够完成学习。一个成功的机器学习项目,关键部分是提取出一组好的用来训练的特征集,这个过程叫作特征工程。
包括以下几点:
特征选择:从现有特征中选择最有用的特征进行训练。
特征提取:将现有特征进行整合,产生更有用的特征。
通过收集新数据创造新特征。
5、训练数据过度拟合
假设你正在国外旅游,被出租车司机狠宰了一刀,你很可能会说,那个国家的所有出租车司机都是强盗。过度概括是我们人类常做的事情,不幸的是,如果我们不小心,机器很可能也会陷入同样的陷阱。在机器学习中,这称为过度拟合,也就是指模型在训练数据上表现良好,但是泛化时却不尽如人意。
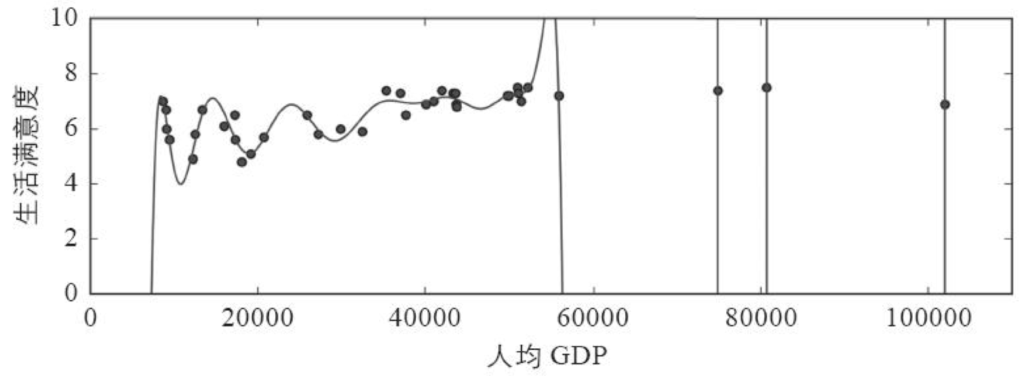
6、训练数据拟合不足
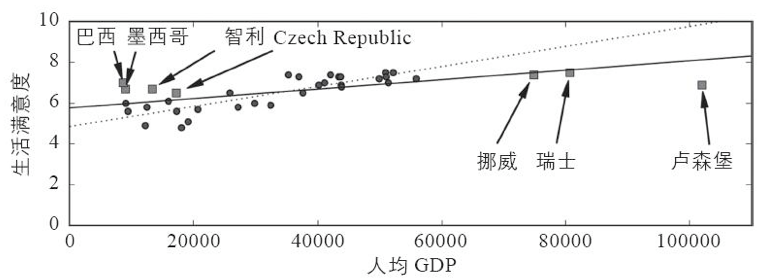
拟合不足和过度拟合正好相反:它的产生通常是因为,对于下层的数据结构来说,你的模型太过简单。举个例子,用线性模型来描述生活满意度就属于拟合不足;现实情况远比模型复杂得多,所以即便是对于用来训练的示例,该模型产生的预测都一定是不准确的。
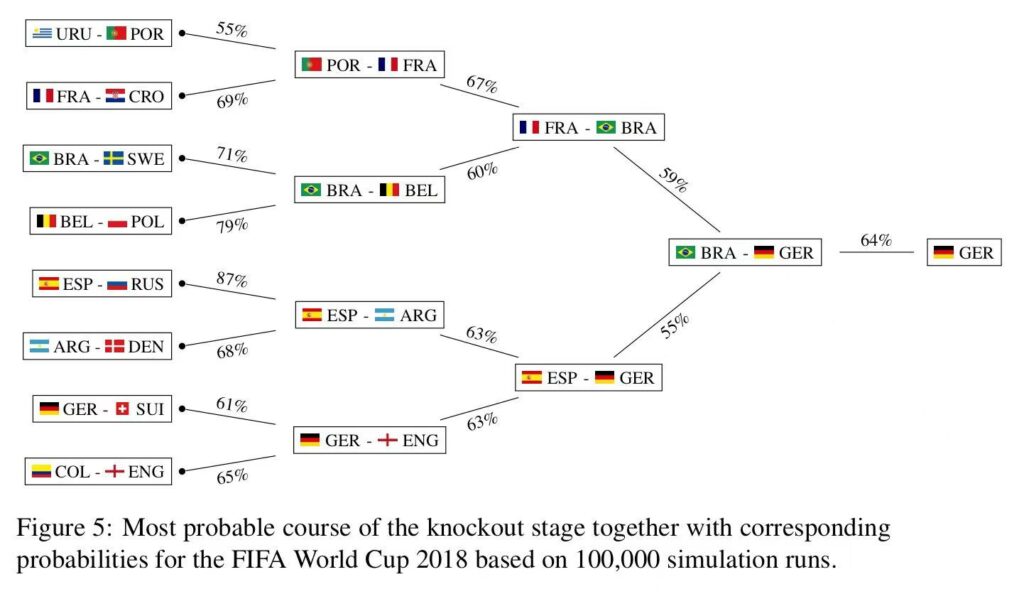
解决这个问题的主要方法有:选择一个带有更多参数、更强大的模型。提供更好的特征集(特征工程)。真实案例——2018年世界杯冠军预测
2018年世界杯的预测——随机森林法,重点评估球队能力参数估计。

评估参数主要考虑到球队的经济因素、运动因素、主场优势。
以及描述团队结构及球队教练的因素。

最终,根据以上参数,预测出2018年德国队获得冠军的几率为64%。
留言
评论
暂时还没有一条评论.