语言分析实践 | 第十七期社群图文直播
智领云第17次社群图文技术直播文字回放:本次直播由大数据后台开发工程师 Ella,为大家带来了主题分享《语言分析实践》,主要内容包括:了解不同语法的语法树、了解如何根据语法树优化语言、了解语言执行日志中重要的指标、了解语言分析是如何根据语法树和历史数据完成语言的优化。
我们在项目开发和项目上线初期,由于业务数据量相对较少,Hive作业,Spark作业,Hive SQL,Spark SQL等的执行效率对程序运行效率的影响不太明显,而开发人员和运行人员也很难评估其对资源的具体使用和整体程序的影响,因此很少针对性的对作业和SQL进行调整,而随着时间的积累,业务数据量的增多,作业和SQL的执行效率对程序的运行效率的影响逐渐增大,此时对作业和SQL进行语言分析非常有必要。
另外外网也有很多关于SQL和各种类型作业优化的教程,使用者学习成本比较高,而且是针对单一的作业或者SQL,无法做全局的分析,因此需要一个全局的作业统计分析,从而减少相同逻辑的多次处理。
什么是语言分析
在项目中,我们有各种类型的作业和SQL,我们想知道这些作业,SQL之间是否有关联,具体的执行情况,哪些阶段耗时、耗资源,是否可以优化。
我们以一个Spark SQL作业为例:
- SQL完成了功能上的需求,但是很复杂,是否可以优化
- 资源要如何配置
- 前一段时间运行正常,突然运行时间成倍增长
- 对于跨度时间长,又有很多作业都需要使用的数据,能否预计算
语言分析是对作业,SQL的执行计划和执行日志进行分析,根据分析结果,给出资源,并行度,重复计算等方面的优化和推荐,从而减少响应时间,提高资源使用率。
语言分析提供功能:
- 作业执行分析(计划和日志),优化推荐
- 整库血缘分析
- 整库优化建议
- 全局常用的聚合计算
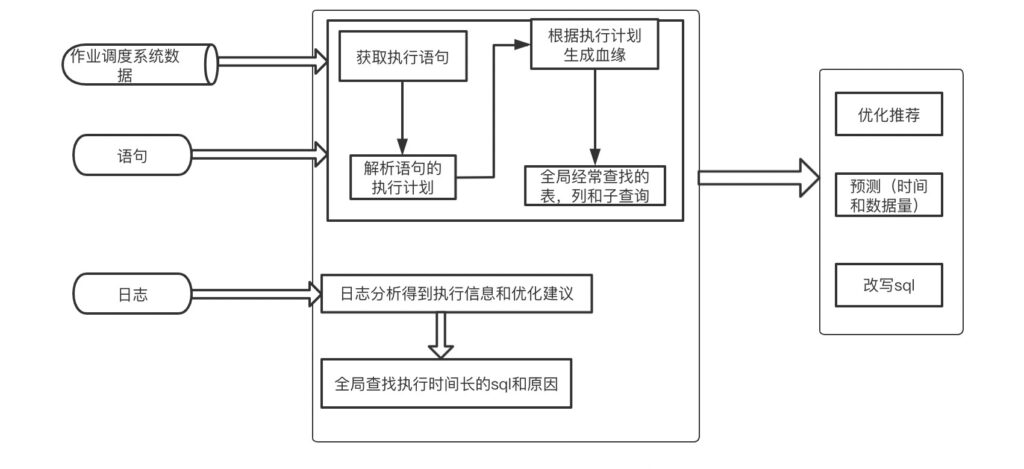
语言分析中主要以Hive 和 Spark SQL为例。
什么是Hive
Hive最初是Facebook为了满足对海量社交网络数据的管理和机器学习的需求而产生和发展的, 是建立在 Hadoop 基础上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制(数据存储在HDFS上,数据计算用Map Reduce)。Hive 定义了简单的类 SQL 查询语言,它允许熟悉 SQL 的用户查询数据。同时,这个语言也允许熟悉 Map Reduce 开发者的开发自定义的 Mapper 和 Reducer 来处理内建的 Mapper 和 Reducer 无法完成的复杂的分析工作。
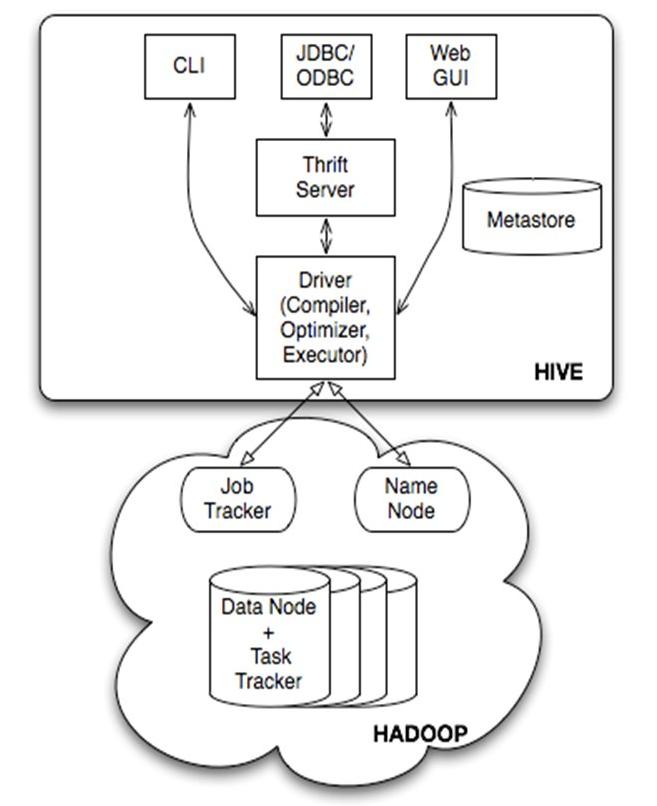
Client 三种访问方式
1、CLI(hive shell)、Command line interface(命令行接口)2、JDBC/ODBC(Java访问Hive),3、WEBUI(浏览器访问hive)
Meta store 元数据存储
元数据包括:表名、表所属的数据库(默认是Default)、表的拥有者、列、分区字段、表的类型(是否是外部表)、表的数据所在的目录等;默认存储在自带的Derby数据库中,推荐使用采用MySQL存储Metastore。
ThriftServers:
提供JDBC和ODBC接入的能力,它用来进行可扩展且跨语言的服务的开发,Hive集成了该服务,能让不同的编程语言调用Hive的接口。 Driver包含:解析器、编译器、优化器、执行器。
1、解析器:将SQL字符串转换成抽象语法树AST,这一步一般都用第三方工 具库完成,比如Antlr;对AST进行语法分析,比如表是否存在、字段是否存在、SQL语义是否有误(比如select中被判定为聚合的字段在group by中是否有出现);
2、编译器:将AST编译生成逻辑执行计划;优化器,对逻辑执行计划进行优化;
3、执行器:把逻辑执行计划转换成可以运行的物理计划。对于Hive来说,就是MR/TEZ/Spark;
Hive Explain
Hive提供了Explain命令来展示一个查询的执行计划。语法如下

使用EXTENDED参数,会打印出有关运算符的更多的信息,比如文件名等。
一个Hive查询被转换为一个由一个或多个stage组成的序列(有向无环图DAG)。这些stage可以是mapreduce stage,也可以是负责元数据存储的stage,也可以是负责文件系统的操作(比如移动和重命名)的stage。Explain的输出包含以下三部分:
- 查询的抽象语法树
- 执行计划中的不同stage的依赖关系
- 每个stage的细致描述
这些stage自身的描述包含了一系列运算符,以及与这些运算符相关联的元数据。元数据可能包含filter operator的filter表达式信息,或是select表达式信息,或是File Sink Operator运算符的输出文件名等信息。 stage的依赖图:描述各个stage之间有依赖关系
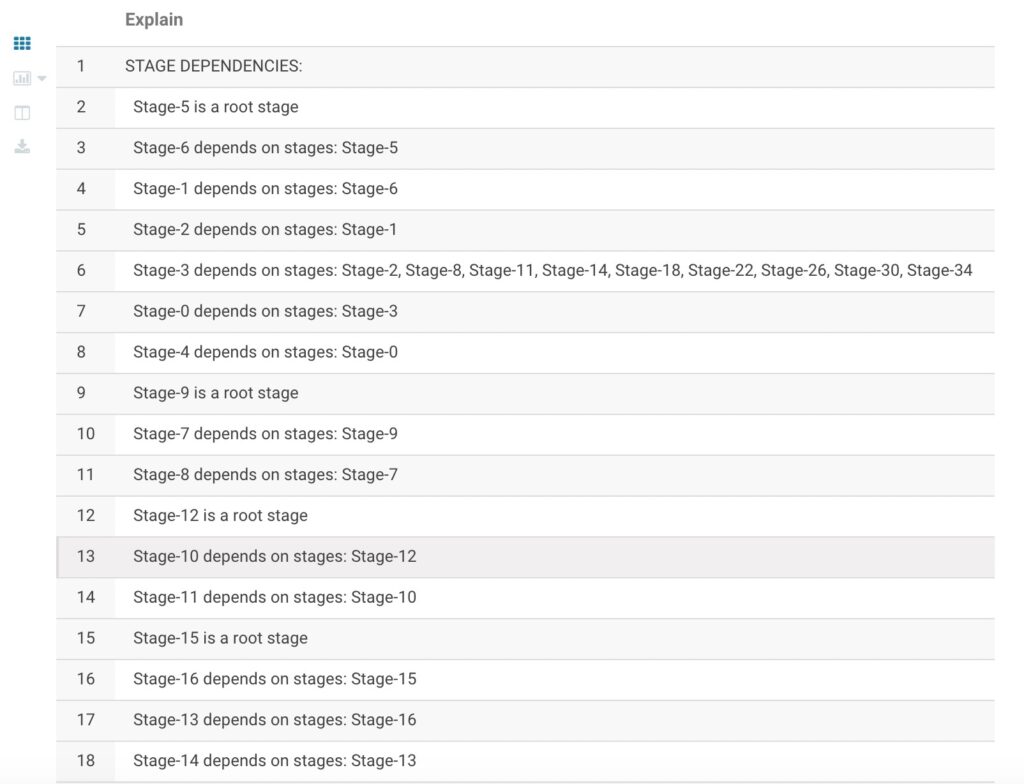
Stage的详细信息:
TableScan //from加载表,描述中有行数和大小等
Filter Operator // where过滤条件筛选数据,描述有具体筛选条件和行数、大小等
Select Operator // 筛选列,描述中有列名、类型,输出类型、大小等
Group By Operator // 分组,描述了分组后需要计算的函数,keys描述用于分组的列,outputColumnNames为输出的列名,可以看出列默认使用固定的别名_col0,以及其他信息
Reduce Output Operator // map端本地的reduce,进行本地的计算,然后按列映射到对应的reduce
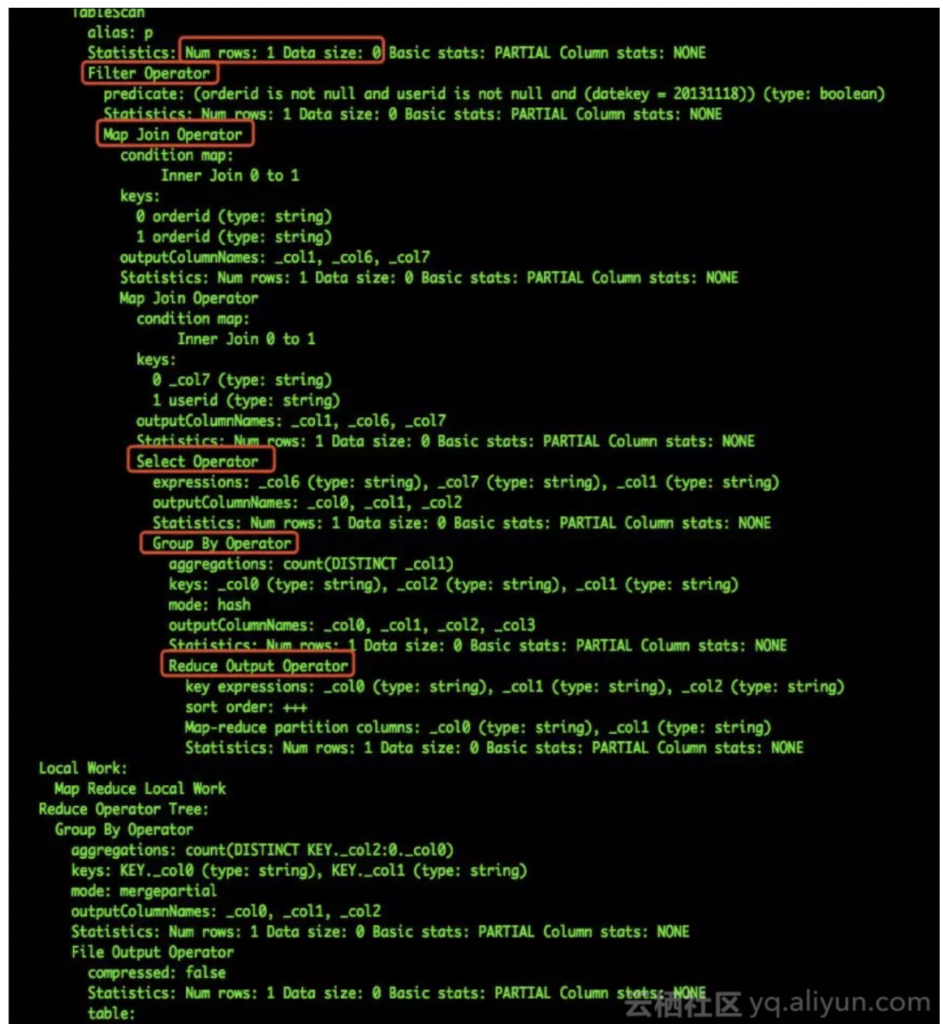
语言分析根据stage的依赖关系和stage的详细信息,收集不同类型的Operator,并提炼出需要聚合的算子。
Hive优化推荐
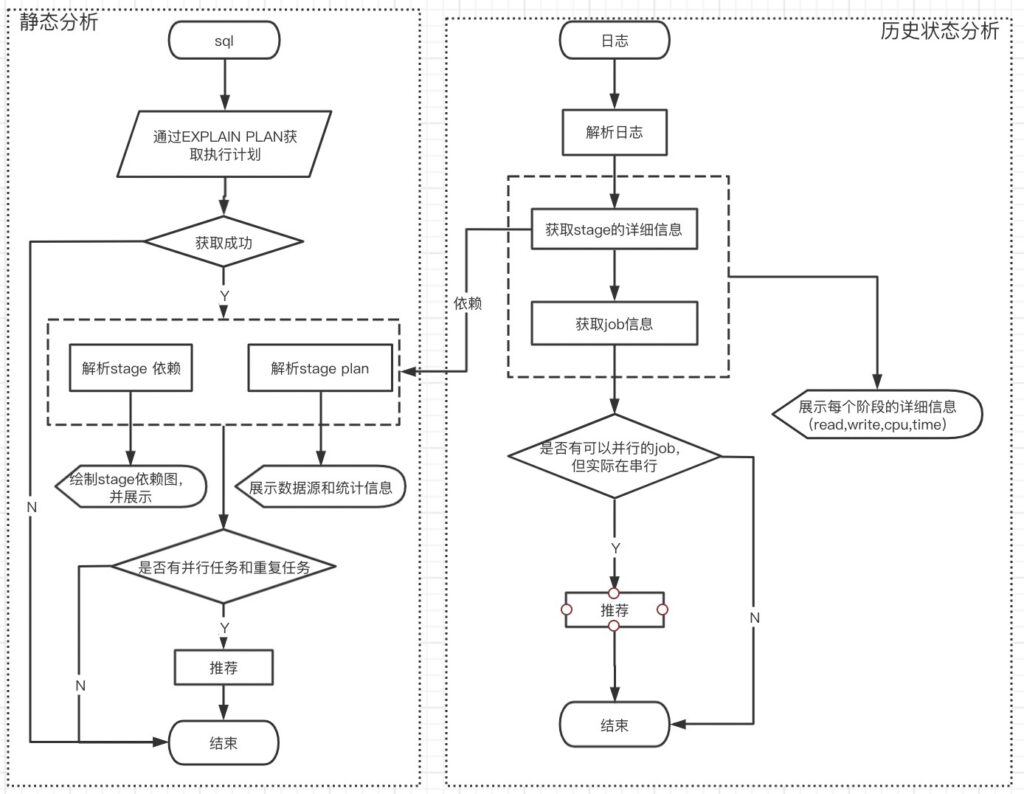
通过stage的依赖图,可以获取root stage的个数,从而判断是否需要开启hive的并行度;
每个stage详细信息中有关于数据行数和数据量的大小,从而可以预估需要使用的资源;
分析每个Hive作业/Hive SQL的日志,可以拿到每次job ,map,reduce个数,读写数据量和cpu的时间,从而可以推测随着时间推移,其读写的数据量和运行时间;
结合explain和日志中job的运行情况,可以给出并行度的推荐;
结合日志中job中map,reduce个数,读写的数据量,可以判断是否存在小文件;
什么是Spark
Spark 是UC Berkeley AMP lab 开发的一个集群计算的框架,类似于 Hadoop,但有很多的区别。最大的优化是让计算任务的中间结果可以存储在内存中,不需要每次都写入 HDFS,更适用于需要迭代的 MapReduce 算法场景中,可以获得更好的性能提升。Apache官方对Spark的定义就是:通用的大数据快速处理引擎。
目前,Spark 已经发展成为包含众多子项目的大数据计算平台。BDAS 是伯克利大学提出的基于 Spark 的数据分析栈(BDAS)。其核心框架是Spark,同时涵盖支持结构化数据 SQL 查询与分析的查询引擎 Spark SQL,提供机器学习功能的系统 MLBase 及底层的分布式机器学习库MLlib,并行图计算框架 GraphX,流计算框架 Spark Streaming,近似查询引擎 BlinkDB,内存分布式文件系统 Tachyon,资源管理框架 Mesos 等子项目。这些子项目在 Spark 上层提供了更高层、更丰富的计算范式。
现在已经有很多大公司正在生产环境下深度地使用Spark作为大数据的计算框架, 包括 eBay、 Yahoo!、 BAT、 网易、 京东、 华为、 大众点评、 优酷土豆、 搜狗等等。
Spark同时也获得了多个世界顶级IT厂商的支持, 包括IBM、 Intel等。
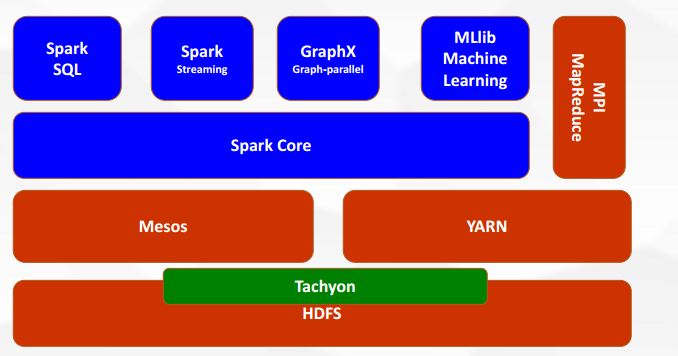
- Spark Core,spark的核心,用于离线计算
- Spark SQL用于交互式查询
- Spark Streaming用于实时流式计算
- Spark MLlib用于机器学习
- Spark GraphX用于图计算
- Mesos和yarn 作用一样,资源调度平台,用yarn的比较多
- Tachyon:内存当中hdfs(内存中的分布式存储系统,加快spark在内存中读取和处理速度);在不同应用程序之间实现数据共享
Spark基本概念
1. RDD(resillient distributed dataset): 弹性分布式数据集。通过 Spark 的 转换 API 可以将 RDD 封装成一系列具有血缘关系的 RDD,也就是 DAG。只有通过 Spark 的动作API 才会将 RDD 及其 DAG 提交到 DAGScheduler。RDD 的祖先一定是一个跟数据源相关的 RDD,负责从数据源迭代读取数据。
2. DAG(Directed Acycle Graph): 有向无环图。Spark 使用 DAG 来反映各 RDD 之间的依赖或血缘关系。
3. Partition: 数据分区,即一个 RDD 的数据可以划分为多少个分区。Spark 根据 Partition 的数量来确定 Task 的数量。
4. NarrowDependency: 窄依赖,即子 RDD 依赖于父 RDD 中固定的 Partition。NarrowDependency分为OneToOneDependency 和 RangeDependency 两种。
5. ShuffleDependency: Shuffle 依赖,也称为宽依赖,即子 RDD 对父 RDD 中的所有 Patition 都可能产生依赖。子 RDD 对父 RDD 各个 Partition 的依赖将取决于分区计算器(Partitioner)的算法。
6. Job: 每个action计算就是一个job。当 RDD 及其 DAG 被提交给 DAGScheduler 调度后,DAGScheduler 会将所有 RDD 中的转换及动作视为一个 Job。一个 Job 有一个到多个 Task 组成。
7. Stage: Job 的执行阶段,根据shuffle划分,即RDD的宽窄依赖。DAGScheduler 按照ShuffleDependency 作为 Stage 的划分节点对 RDD的 DAG 进行 Stage 划分(上游的 Stage 将为 ShuffleMapStage)。因此一个 Job 可能被划分为一到多个 Stage。Stage 分为 ShuffleMapStage 和 ResultStage 两种。
8. Task: 具体执行任务,默认有多少个partition就有多少个task。一个 Job 在每个 Stage 内都会按照 RDD 的 Partition 数量,创建多个 Task。Task 分为 ShuffleMapTask 和 ResultTask 两种。ShuffleMapStage中的 Task 为 ShuffleMapTask,而 ResultStage 中的 Task 为 ResultTask。ShuffleMapTask 和 ReduceTask 类似于 Hadoop 中的 Map 任务和 Reduce 任务。
9. Shuffle: Shuffle 是所有MapReduce 计算框架的核心执行阶段,Shuffle 用于打通 Map 任务(在 Spark 中就是 ShuffleMapTask)的输出与 reduce 任务(在 Spark 中就是 ResultTask)的输入,map 任务的中间结果按照指定的分区策略(例如:按照 key 哈希)分配给处理某个分区的 reduce 任务。
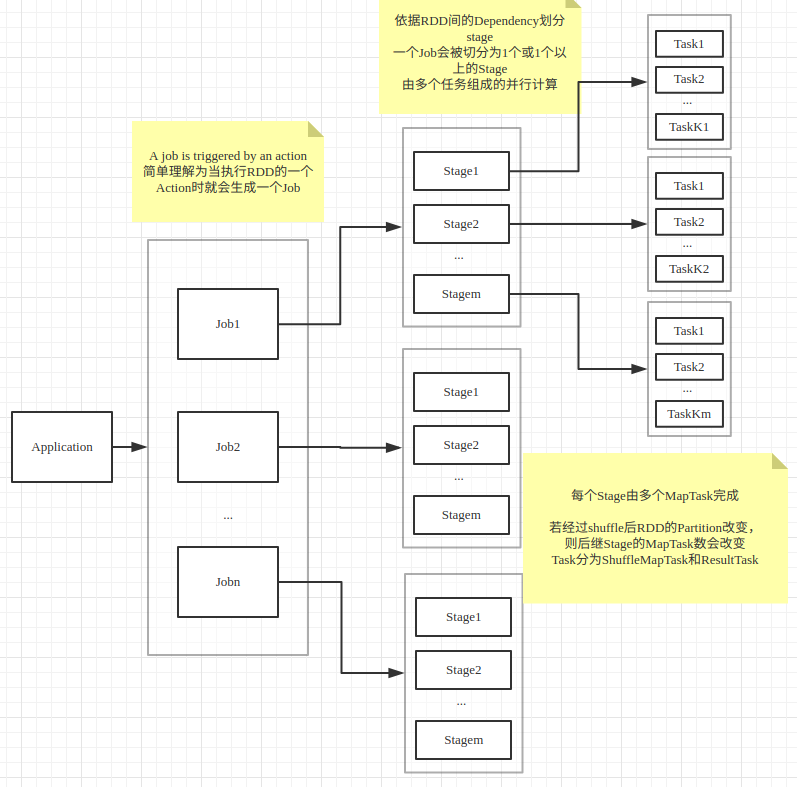
Spark优化推荐
Spark主要是分析运行的历史日志,分别从以下几个方面获取运行指标:
- 每个stage中task的个数以及task处理的数据量
- 数据的本地性(本地/同一个机架/跨机架)
- 数据倾斜
- 广播小表(spark默认10M以内的都是小表)
- 资源配置和使用情况
- 集群资源
- 重复计算
- executor是否移除
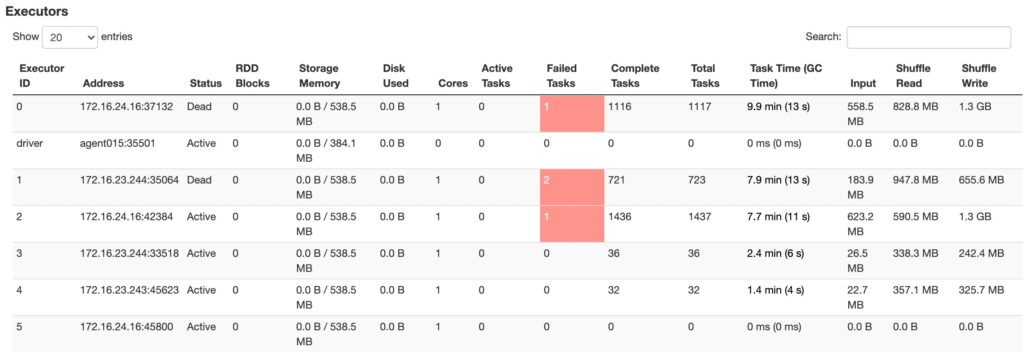
上图可以看到executor有dead,有失败的作业,个别executor处理的task和数据量明显比其它多,GC时间长,处理的数据量也不均衡。
语言分析Spark支持推荐

语言定时分析
定时从FM获取需要语言分析需要解析的运行记录信息,根据作业类型,对其分析,将每条记录的分析结果写入库表,再通过连表查询,得出报表信息。 定时分析分为数据采集模块,历史分析模块,优化建议模块和分析报表模块
- 数据采集模块,通过调用FM接口,获取需要分析的记录,将记录存在collect_data表
- 历史分析模块,从collect_data表获取需要分析的记录,对日志文件进行分析
- 优化建议模块,分析结果匹配优化建议规则,如果符合规则则生成优化建议
- 分析报表模块,统计不同规则的作业量,作业id

语言分析定时从FM中采集需要分析作业,对采集数据进行转换,并存储到collect_data表;
从collect_data表中获取该批次需要分析的数据,判断作业类型,如果是Hive作业,则对Hive的Explain和日志同时分析,得到优化建议;如果是Spark作业,则直接分析Spark的历史日志,得到优化建议;根据建议和规则,生成统计报表;如果在分析阶段,出现异常,则将失败记录写入faild_record,便于分析失败原因和补跑; 具体的实现流程如下图所示:
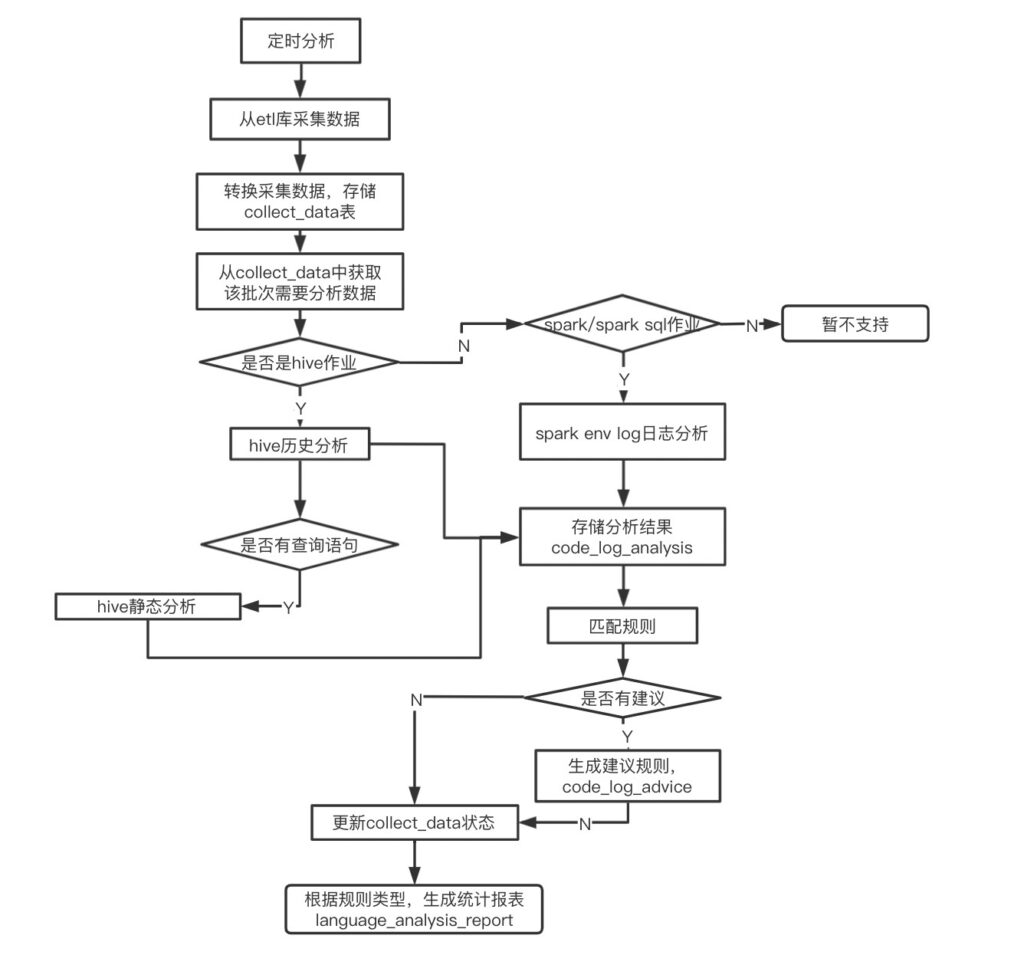
语言分析-报表
collect_data:记录所有需要运行作业,analysis_status为0表示未分析(默认),1分析成功,-1分析失败
language_analysis_report:记录定时分析生所的结果,即所有作业的分析建议,可以通过调用api来查看这个表里的数据
faild_record:记录语言分析时失败的记录,is_delete为0,表示运行失败,is_delete为1,表示失败任务补跑成功
advice_type:规则类型
advice_param:规则对应的阀值
code_log_analysis:分析结果
code_log_advice:分析建议
语言分析在衣邦人项目中,通过分析所有的Hive作业,Spark作业和Spark SQL,给出资源,数据倾斜,task不合理,并行度,重复计算等问题,使得整体资源使用减少50%,运行时间时间减少20%。
留言
评论
暂时还没有一条评论.