如何在 K8s 上运行 Spark & Hive?
引 言:随着 Kubernetes 越来越成熟,使用者越来越多,大数据应用上云的需求也越来越迫切。原有的大数据资源管理器 Yarn 很难做到所有应用资源统一控制,完全隔离,带来的主机应用和大数据计算应用互相抢占资源,由此导致的计算任务时间可能经常性抖动,多租户应用互相影响。而在 Kubernetes 上,此类问题天然解决。所有的应用都以 Pod 形式在 Kubernetes 平台上统一管理,在规范的 namespace 管理下,不存在不受控的应用来进行资源抢占。同时,我们可以轻松地实现多租户,资源配额,运行审计计费等功能。在此背景下,客户原有的大数据计算任务如何无缝迁移到 Kubernetes 上,大数据应用如何进行云原生改造,都成了我们最迫切要解决的问题。本篇文章主要针对这两类问题来进行探讨。
Spark 和 Hive 在智领云业务场景中的使用
Spark 和 Hive 是大数据平台中很常用的两个计算引擎。Hive 本身是一个基于 HDFS 的类 SQL 数据库,其 HQL 语句的底层执行引擎可以使用基于 Yarn 的 MapReduce,也可以使用 Spark。Spark 在 2021 年 3 月推出的 3.1 版本中实现了对 Kubernetes 支持的 GA(general availability,意味着生产级的支持)。在这个版本中,Spark 允许用户从命令行(spark-submit)上提交 Spark 任务到 Kubernetes 集群中。但是目前的 Hive 版本中,如果底层使用 Spark,还只能提交任务到 Yarn,而不能支持将 Hive 查询提交到 Kubernetes。
除了从命令行提交 Spark 任务,智领云使用 Hive 和 Spark 相关的业务还有三个场景:第一个、用户创建 Hive 作业进行数据 ETL 任务开发或数仓分层计算工作流创建。第二个、用户应用程序(例如,批处理调度系统)提交 pySpark 文件或者 Spark jar 包到平台,进行数据计算。第三个、用户使用 Jupyterlab Spark kernel 来访问 Hive/Mysql/Hdfs/Glusterfs 等数据源文件进行数据探索、机器学习及人工智能算法开发。这三种场景下的共同点都是需要将计算任务转换成 Spark job 在集群中调度运行(Hive 的缺省引擎已经从 MR 变成了 Spark)。在每个场景下,我们都在 Spark on Kubernetes 的基础上提供了相应的解决方案:
- 在 Kubernetes 平台上使用 Hive,我们使用了 Hive on Spark on Kubernetes。
- 对于 Spark 作业,我们集成了 Spark On Kubernetes Operator。
- JupyterLab 中使用 Spark, 我们集成了SparkMagicKernel 和 Livy。
每种集成方式,都有其独有的优势和缺陷及其适用场景,下面我们来一一讲解。
Hive On Spark On Kubernetes
在类 SQL 数据库中,Hive 是很多 Hadoop 生态系统缺省的选择。虽然 Spark 也提供了 SparkSQL 来支持 SQL 查询,但是 Hive 使用的 HQL 和 SparkSQL 在语法支持上还是存在比较大的差异,对于大型的数据仓库项目,用户可能积累了几千个 Hive 任务,如果此时想要快速地迁移到 Kubernetes 上,那么使用 SparkSQL 存在很大的迁移成本和风险。但是如果我们只更改 Hive 的底层执行引擎,改成 Spark on Kubernetes,那么,我们就能让客户的 Hive HQL 应用,无需修改地快速迁移到 Kubernetes 上。但是由于 Spark on Kubernetes 是最近才达到 GA 状态,和不同的 Hive 版本,Kubernetes 版本,以及很多相关大数据组件之间的适配还没有成熟,我们需要对现有的版本之间进行一些适配才能平滑运行 Hive On Spark On Kubernetes。
首先,我们必须要确定 Hive、Spark、Hadoop(HDFS)以及相关的 Kerberos、Ranger 的版本。对于 Spark 版本的选择,我们开发选型的时候最新版为 3.1.1,目前 Spark 最新版已经到了 3.2.1,Spark 选取最新版本即可,最新版本能够增强对 Kubernetes 的支持。而 Hive 版本选取的主要原则,即查看 Spark-client 模块的代码是否支持 Kubernetes,如果不支持是否容易改造以便支持。而 4.0.0 版本开始,spark-client 模块重构了代码结构,增加了 SparkClient 的抽象类,有该结构支持,增加对 Kubernetes 的支持就容易了很多。这里还有一种选择,就是 Hive 选用 3.1.2 的稳定版本,然后把最新的 master 分支的 spark-client 模块代码 cherry pick 到 3.1.2 版本即可。
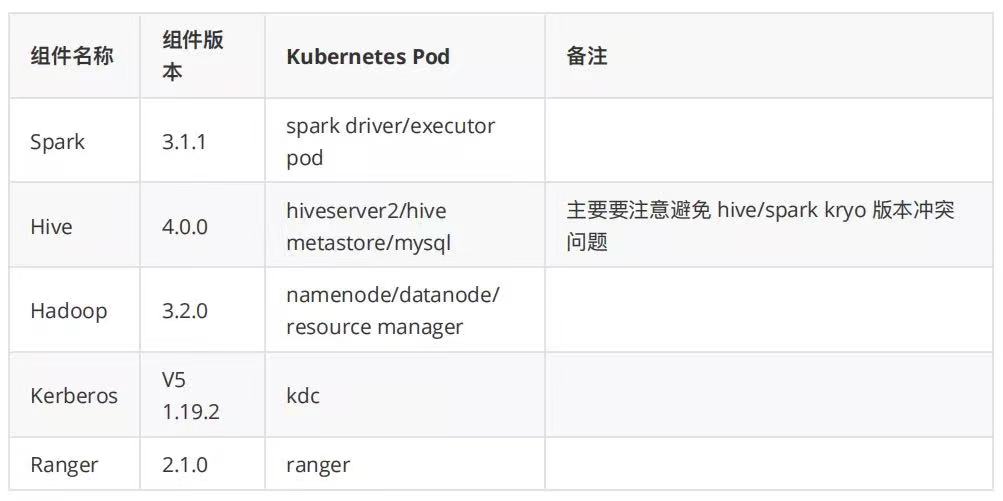
在 Hive 代码中主要改造内容是增加 KubernetesSubmitSparkClient,主要内容是构造 SparkSubmit 向 Kubernetes 提交 Spark 任务的各种参数,包括和 Hive 中 RPC server 通信的配置,提交 Spark 作业后,Spark driver pod 启动后会连接 HiveServer2 中的 RPC server,连接成功后,HiveServer2 会发送相应的 Spark job 到 Spark driver 来进行计算。而 Spark 代码的改动,主要是修改 Spark 中的 hiveShim 模块,增加对 Hive 4.0.0 的支持。
Hive On Spark 在智领云的数据平台,主要作为 Hive 作业/工作流以及 Hue 查询工具的底层执行引擎:调度系统通过 Beeline 来连接 HiveServer2,Hue 通过 JDBC 连接 HiveServer2,客户端发送用户的 SQL 语句到 HiveServer2。HiveServer2 解析完成 SQL 后,会生成一系列的 HQL taskplan,对于这些 HQL 的执行,HiveServer2 会启动一个 RPC server,SparkSubmit 会带上 RPC server 参数,启动一个 Spark Driver Pod 来和 HiveServer2 进行 RPC 通信,这个 Spark Driver Pod 的主要功能就是接收 HiveServer2 发送过来的 SQL Job 进行计算,计算完成后,将结果返回给 HiveServer2 中运行的 RPC server。
在 Kubernetes 平台,SparkSubmit 客户端和 Kubernetes APIServer 通信,Kubernetes 在接收到 Spark 任务请求后,会调用 Scheduler 组件启动 Spark Driver Pod, Spark Driver 在启动完成后,会发送启动 Executor 请求给 Kubernetes APIServer, Kubernetes 再启动 Spark Executor Pod, Spark Driver 和 Executor 建立连接,完成整个 Spark 集群的创建。
整体架构如下图所示:
权限控制方面,我们使用 Ranger 来完成授权和鉴权操作,使用 Kerberos 来完成认证操作。对于 Ranger 鉴权插件, Hive 和 Spark 都有相应的解决方案。Hive 直接通过 Hive Ranger 插件和 Ranger 服务来通信,完成鉴权操作,Spark 则通过 Spark Authorizer 插件再调用 Hive Ranger 插件来完成鉴权。在 Hive On Spark 模式下,我们使用 Spark 对 Kerberos 的支持来完成用户身份认证操作,通过 Hive Ranger 插件来完成鉴权操作。
Spark on Kubernetes Operator
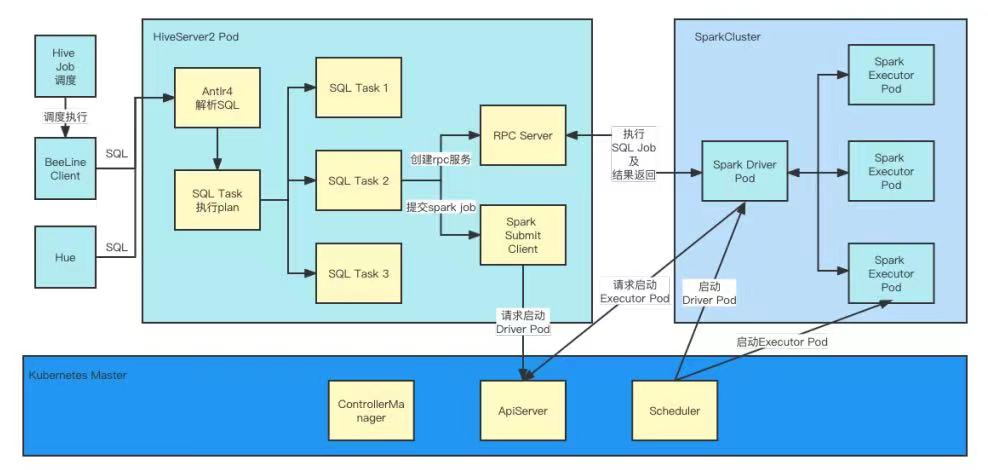
Spark on Kubernetes Operator 项目是 Google 非官方推出的 Spark On Kubernetes 解决方案。它的内部实现是基于 Spark 官方的 Spark On Kubernetes 解决方案之上,更多的利用了 Kubernetes 特性,来增强在 Kubernetes 上使用 Spark 计算引擎的易用性和灵活性以及性能的提升。
它本质上是一个 Kubernetes Operator,所以在该解决方案下,用户提交 Spark 作业只需要通过 Yaml 文件即可,并且可以定制 Kubernetes Schedule。比如,可以配置使用华为提供的针对大数据领域优化过的 Volcano 调度引擎。
在智领云平台上,Spark on Kubernetes Operator 承载了用户提交 Jar 包或者 pySpark 文件类型的所有 Spark/Spark-streaming 作业的底层调度引擎。在 Spark OnKubernetes Operator 成熟之后,Hive on Spark 底层未来也可以增加 Spark On Kubernetes Operator 运行模式的支持,仅仅只需要在 spark-client 模块中增加KubernetesOperatorSparkClient 抽象类的支持即可。
Spark Operator 方案也存在一个弊端,就是 Spark 作业配置 Yaml 的高度复杂化,该 Yaml 需要配置 Spark 作业的所有信息,包括Driver/Executor 的资源控制,包括 Spark 的镜像版本和调度算法。普通用户不需要关注这些配置。在此问题下,我们模仿 Apache Livy 的 API 增加了一个 Spark On Kubernetes Operator Server。该服务负责管理 Spark On Kubernetes Operator Job,提供创建/更新/删除 Job 接口,提供查询 Job 状态及日志请求。用户只需要配置少量Spark Job 参数,后台服务会根据参数完成 Spark Job Yaml 文件渲染,提交到 Kubernetes 集群。
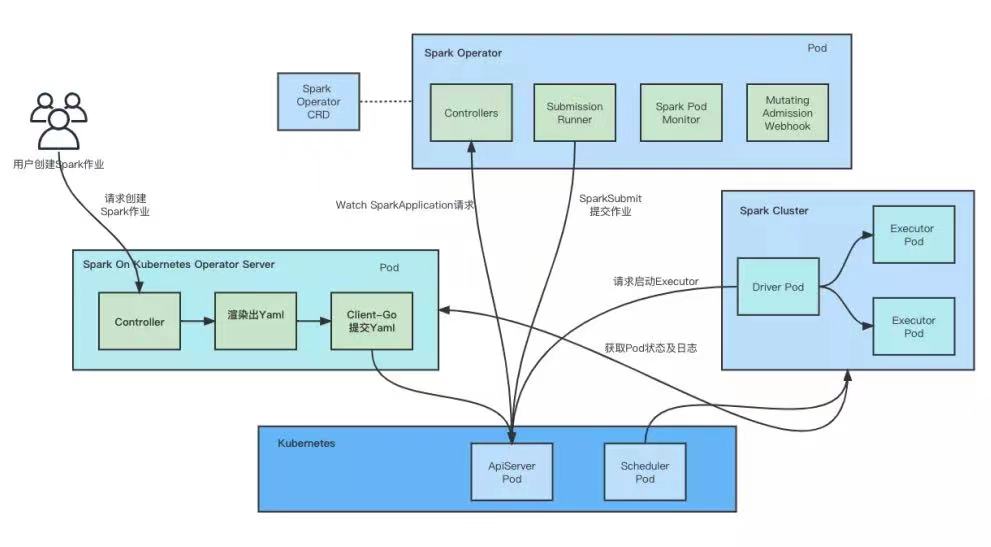
在权限控制这一块,我们可以使用 Spark 相关配置结合 Spark Operator 对 Kerberos 的支持来实现。对 Ranger Hive 插件的支持,我们可以使用 Spark Authorizer 插件来转接适配,不过该插件版本较老,我们需要修改其 POM 文件和相关代码来使其可以支持 Spark 3.1.1 版本。在 Spark Operator 模式下, Spark 作业的相关配置都在 Yaml 中配置,我们可以利用 Spark Operator 对 Sidecar 的支持来完成 Spark Operator 对 Ranger Hive 插件的支持。主要方法就是 Spark 3.1.1 版本的原生镜像不变,将 Ranger 相关的 Jars 通过 Sidecar 共享目录共享给 Spark 主 Container,并配置相关 ClassPath 参数,使 Spark 能够找到 Ranger 和 Spark Authorizer 相关 Jar 包。
JupyterLab On Kubernetes
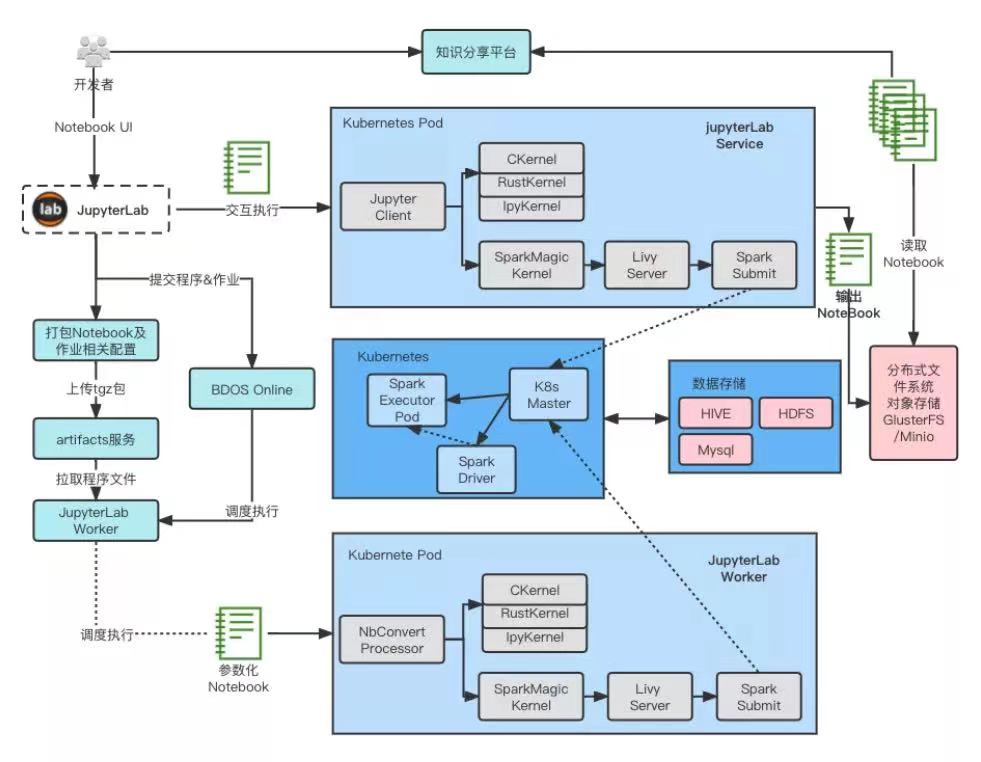
JupyterLab 作为数据科学家首选的 IDE,在数据及人工智能领域应用非常广泛。在智领云平台,我们的主要改造是打通JupyterLab 和我们的调度平台的互相访问,增加 Spark 读写 Hive / HDFS 的支持。这个场景和前两个场景的主要区别在于 JupyterLab Kernel 和 Spark Driver Pod 之间可能有持续的交互,而不是 run to finish。其次,在 UI 界面下的任务需要无需修改的在后台(测试或生产环境下)运行。在此需求之下,我们主要做了几点改动:
- 选取了 SparkMagic Kernel 支持了用户编写测试 Spark 代码。
- 改造 JupyterLab Server 代码,允许用户直接点击开启当前 Spark 任务的 4040 调试页面 UI。
- 改造 JupyterLab Client 代码,允许用户可以直接在 JupyterLab Notebook 内直接引用系统或者用户自定义变量,并能够在调度和调试时生效。
- 增加了 JupyterLab 调度 Worker,使调度平台可以直接调度运行用户的 ipynb 类型的 Notebook 文件。
- 增加 JupyterLab Python 环境管理,允许 JupyterLab 在重启后保持其之前设置的 Python 环境。
SparkMagic Kernel 执行 Spark 任务是利用 Apache Livy 服务来实现任务的提交以及交互Session 的维护。Apache Livy 目前版本对 Kubernetes 并不支持,我们需要添加 Kubernetes client 和状态查询的支持。Apache Livy 实现的对 Kubernetes 的支持实际上是和 Hive on Spark 模式类似,都是创建 RPC Server,然后调用 SparkSubmit 提交 Spark 任务和 RPC Server 通信,来完成 SQL 任务的交互。下图展示了整个流程的架构。
在此种模式下,Hive 的权限控制配置和 Spark Operator 类似,都是使用 Spark Authorizer 和 Hive Ranger 插件来实现。
未来
在智领云平台,我们使用了存储和计算分离的方案,在计算层使用 Spark on Kubernetes 作为主要的计算引擎,底层可以采用 HDFS 兼容现有系统,也可以采用其它支持 HDFS 接口的云原生存储。这样的架构,加上对 Hive 等传统 Hadoop 生态的云原生改造,可以在最大程度的支持现有系统的同时逐步迁移到纯云原生的体系架构下,无缝集成新的大数据和人工智能系统。而基础架构即代码(Infra as Code)方式的使用, CI / CD 全链路的支持,为类似 DataOps,DataMesh 的新型数据应用开发运维范式提供了清晰可行的技术架构支持。而由此带来的业务开发效率的提升,业务管理运维效能的提升,都是质的变化。未来可期。
本文作者:Zery 智领云科技大数据后台开发工程师
#智领云公司简介#
武汉智领云科技有限公司成立于2016年8月,专注于云计算、大数据领域前沿技术的研发。公司创始团队成员来自于推特(Twitter)、苹果(Apple)和艺电(EA)等硅谷知名企业,是硅谷最早一批从事云计算和大数据研究与实践的技术专家,拥有十多年的云计算、大数据系统的系统架构和系统开发经验。公司作为拥有云计算、大数据领域核心技术的高科技企业获得了来自硅谷和国内知名投资人和投资机构的投资。公司于2019年4月获得线性资本数千万元pre-A轮融资,2020年7月获得由金沙江联合领投、线性资本跟投的数千万元A轮融资。
公司为企业级客户提供以云原生DataOps为底座的大数据平台数据中台/大数据平台数据中台系统解决方案;帮助企业搭建数据和AI中台实现云原生DataOps,轻松打造业务数据能力闭环,掌握全面、及时、更多维度的业务现状,提升数据驱动应用的迭代和发布速度;实现系统资产(人/资源/数据/应用) 在同一系统中的统一管理,建立数字化运营体系,并最终完成数据驱动的数字化转型。
公司在能源、教育、医疗健康、物联网、金融等行业同国内外很多知名企业和上市公司建立了合作关系,包括:D2IQ、埃克森美孚(中国)、一汽集团、极狐(GitLab中国)、南瑞信通、万达信息股份、中亦安图、深圳智宇、长江云通、湖北楚天云、万方数据股份、天喻教育、广州畅驿、上海和今、南京赛信等。公司与合作伙伴在多个领域中展开紧密的合作,充分利用各自的优势,共同为企业客户提供更有价值的云计算和大数据产品和技术服务。

留言
评论
暂时还没有一条评论.