行业热度分析与预测
本项目展示了一个针对豆瓣图书热度进行的大数据分析实例,通过爬虫数据进行采集、处理、分析及转换/导出等步骤,旨在帮助用户体验大数据分析,帮助用户能够迅速了解到各行业的热度以及对应书籍的排名情况。
前期已通过爬虫程序对豆瓣网的图书情况进行了爬取,存到了机构的Mysql库中
接下来的包括步骤如下:
第一步:数据库采集,采集数据到hive库中
第二步:Hive程序,进行数据处理,清理无关的数据,并将需要的数据进行提取。
第三步:Spark程序,从书籍数、评分、在读已读等维度对数据进行分析
第四步:ETL程序,把数据从数仓导入到指定的MySQL库,对结果数据的可视化展示进行数据准备
第五步:Spring Boot应用,提供发布大屏所需要的服务接口
第六步:docker应用,发布大屏应用展示
第七步:Superset,通过Superset对结果数据进行BI可视化展示
项目步骤介绍
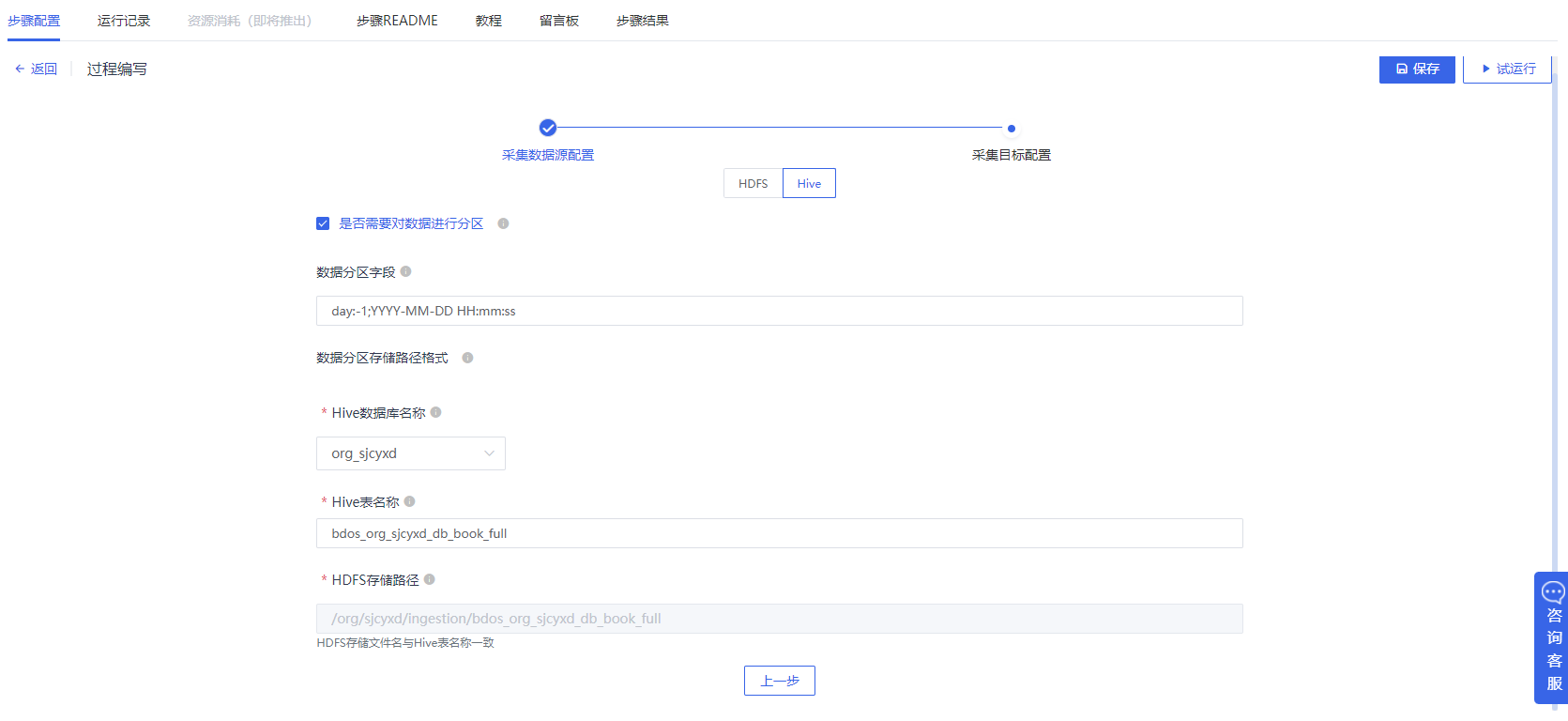
1.数据库采集,采集数据到hive库中
创建项目后,添加【数据采集-数据库采集】,首先为采集数据源进行配置,数据源为机构数据源:sjcyxd_mysql,表名为:book,数据范围:全量

配置完成后,进行采集目标配置,选择输出的Hive库名称,并命名表。
2.Hive程序,数据处理,提取出所需的字段
点击添加【数据分析-Hive程序】步骤,本步骤主要为对上一步输出的Hive表中的数据进行处理
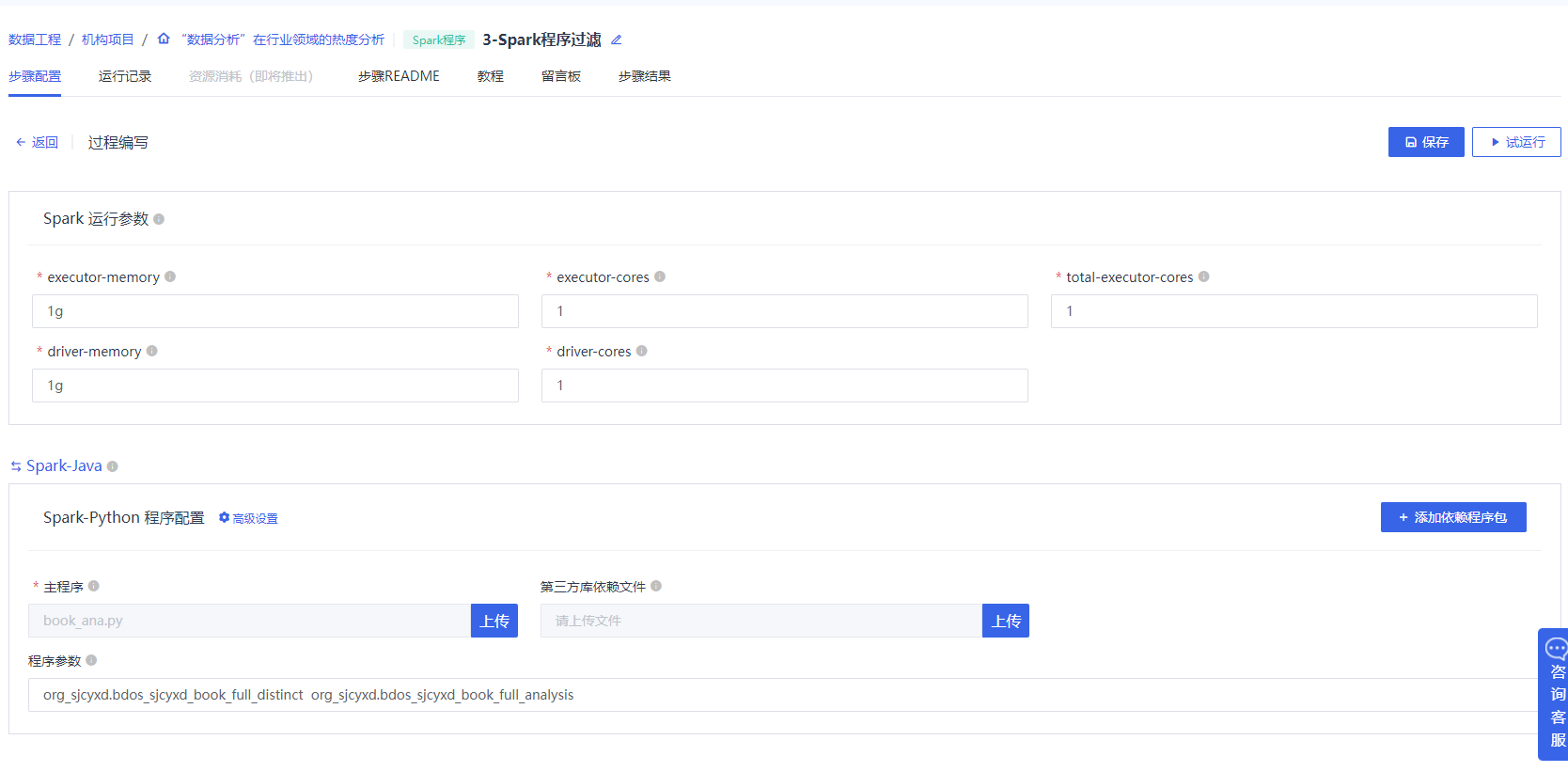
3.Spark程序,从书籍数、评分、在读已读等维度对数据进行分析
点击添加【数据分析-Spark程序】,该步骤主要是通过spark程序进行多维度分析,按照下图进行配置,并上传spark程序包
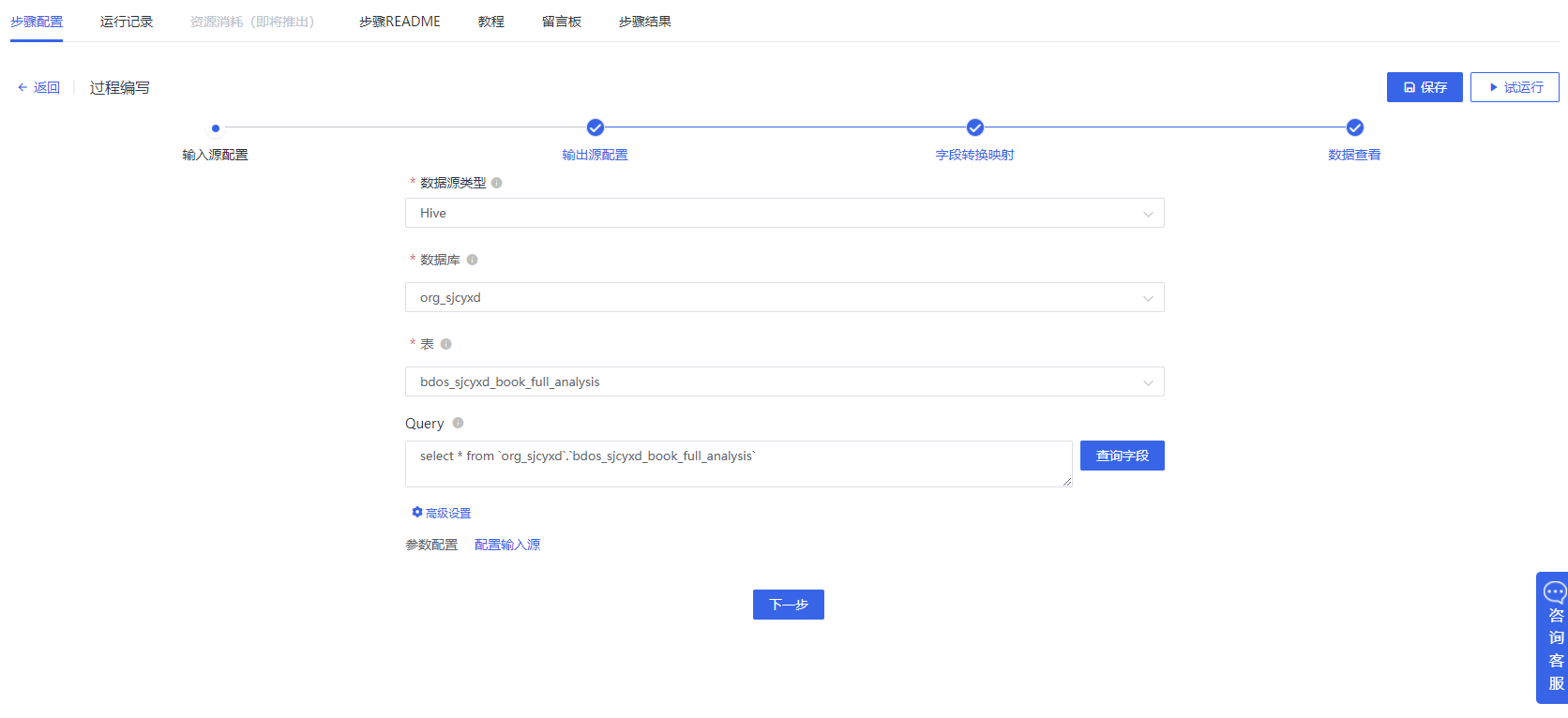
4.ETL程序,把数据从数仓导入到指定的MySQL库
点击添加【数据转换-ETL程序】,配置输入源:选择Hive库:org_sjcyxd,选择表:bdos_sjcyxd_book_full_analysis。
配置输出源:选择Mysql库,存到book_analysis中,数据变更:Update,
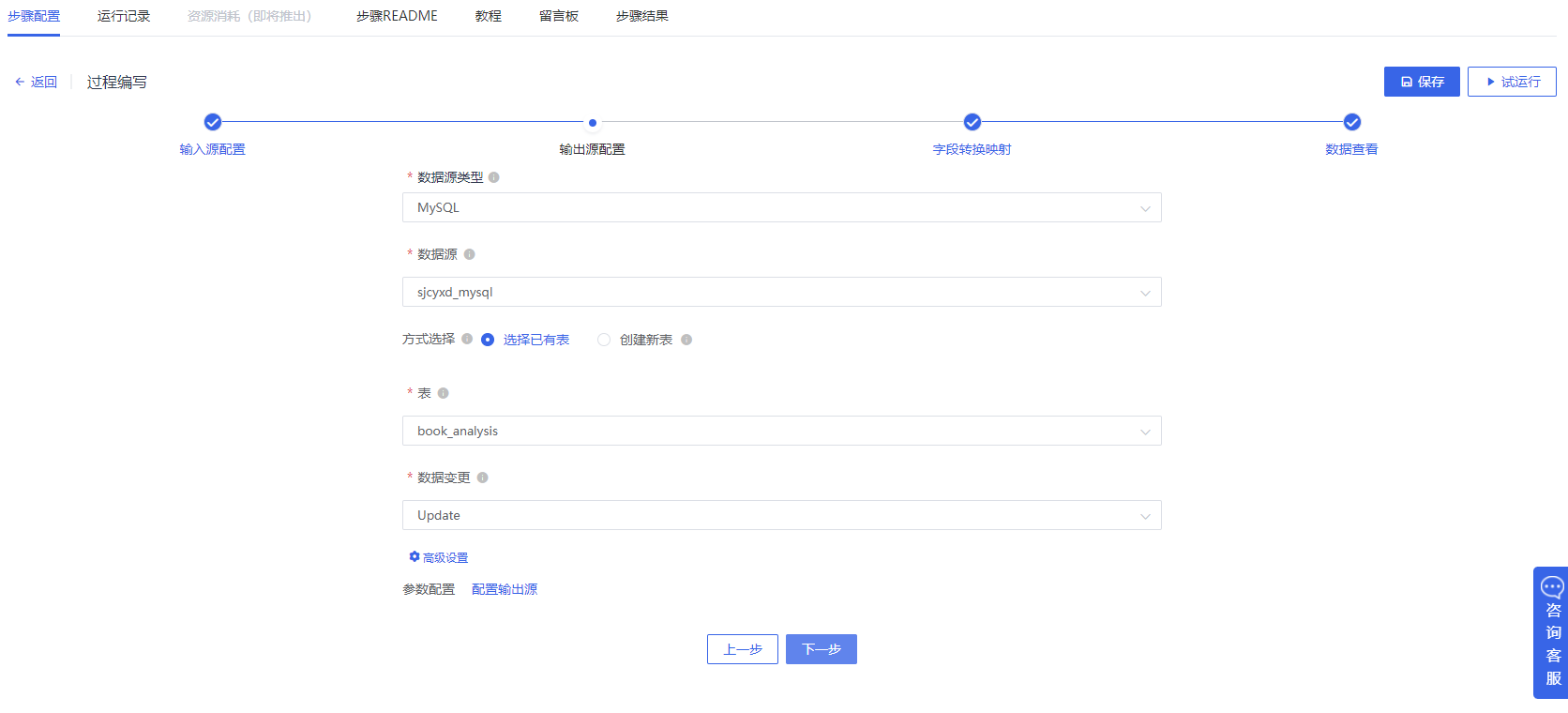
字段映射中开始匹配,确认字段能够对应。

最后可以进行数据查看确认结果。
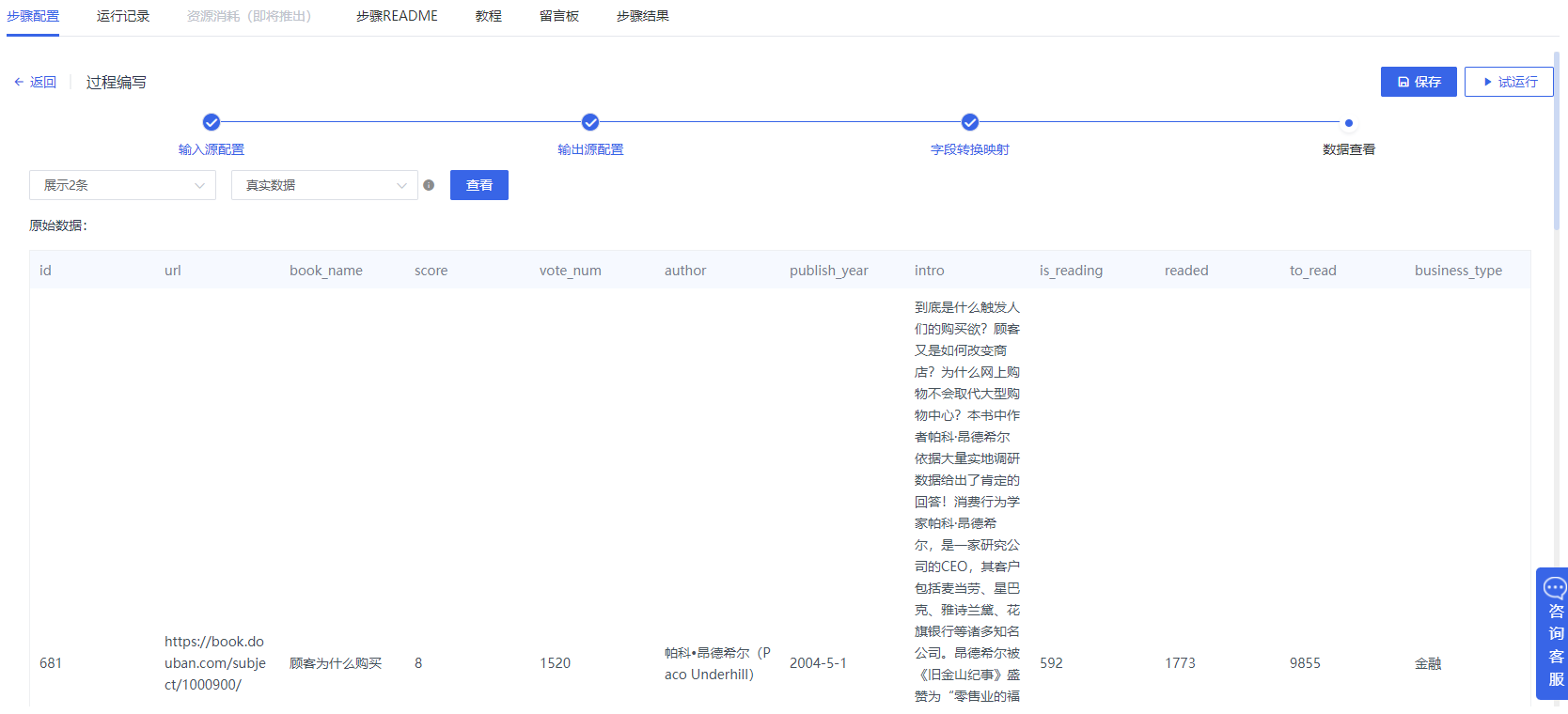
5.Spring Boot应用,提供大屏所需要的服务接口
点击添加【数据应用-SpringBoot应用】,根据指定的数据格式,发布数据接口服务,供前端大屏展示。上传jar包,并按照下图进行配置。[jar包下载地址] http://linktime-public.oss-cn-qingdao.aliyuncs.com/hackweek/sjcyxd/%E8%84%9A%E6%9C%AC%E5%8F%8A%E6%96%87%E4%BB%B6/book-5.0.jar
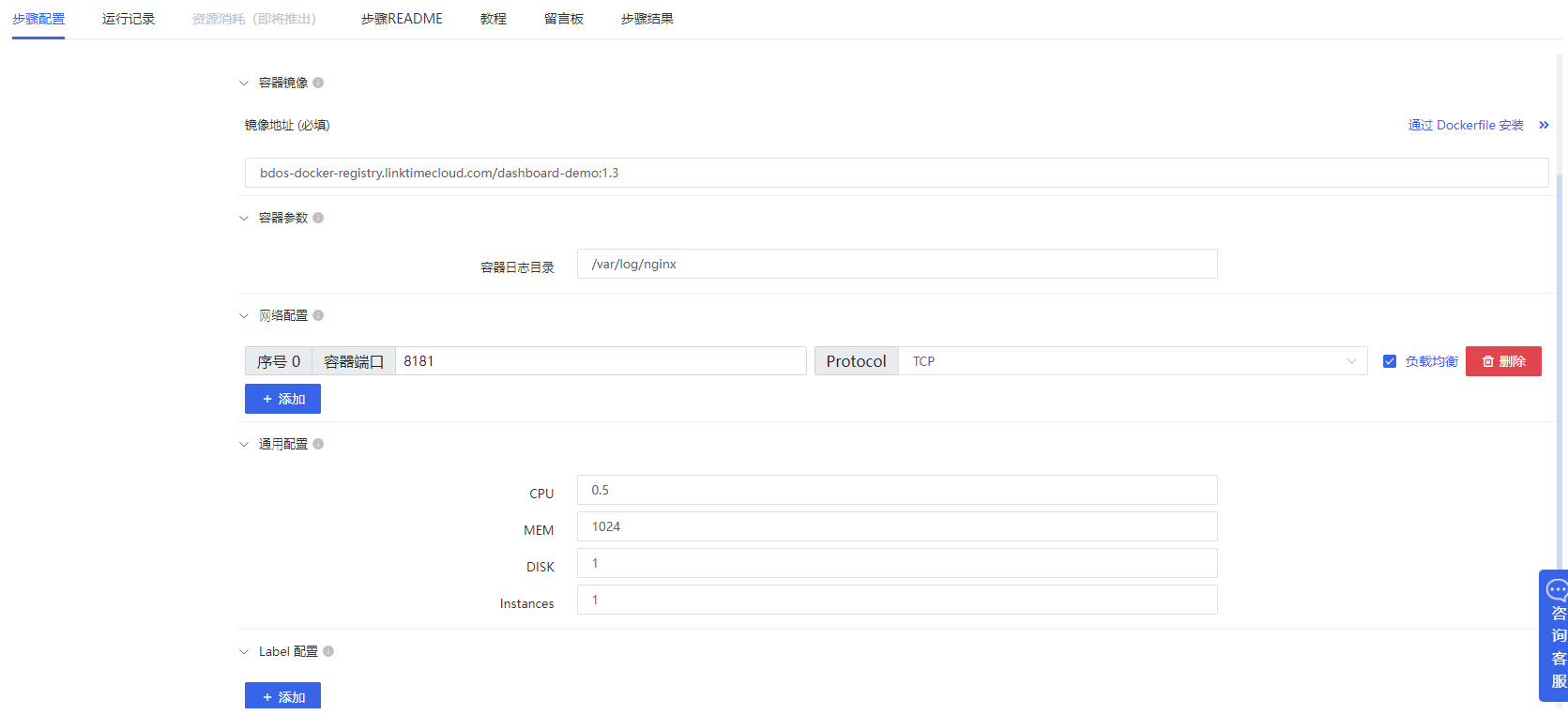
6.docker应用,发布大屏应用展示
添加【数据应用-Docker应用(通过配置)】,通过接口,将分析的数据通过大屏进行展示。参照以下配置进行大屏发布。
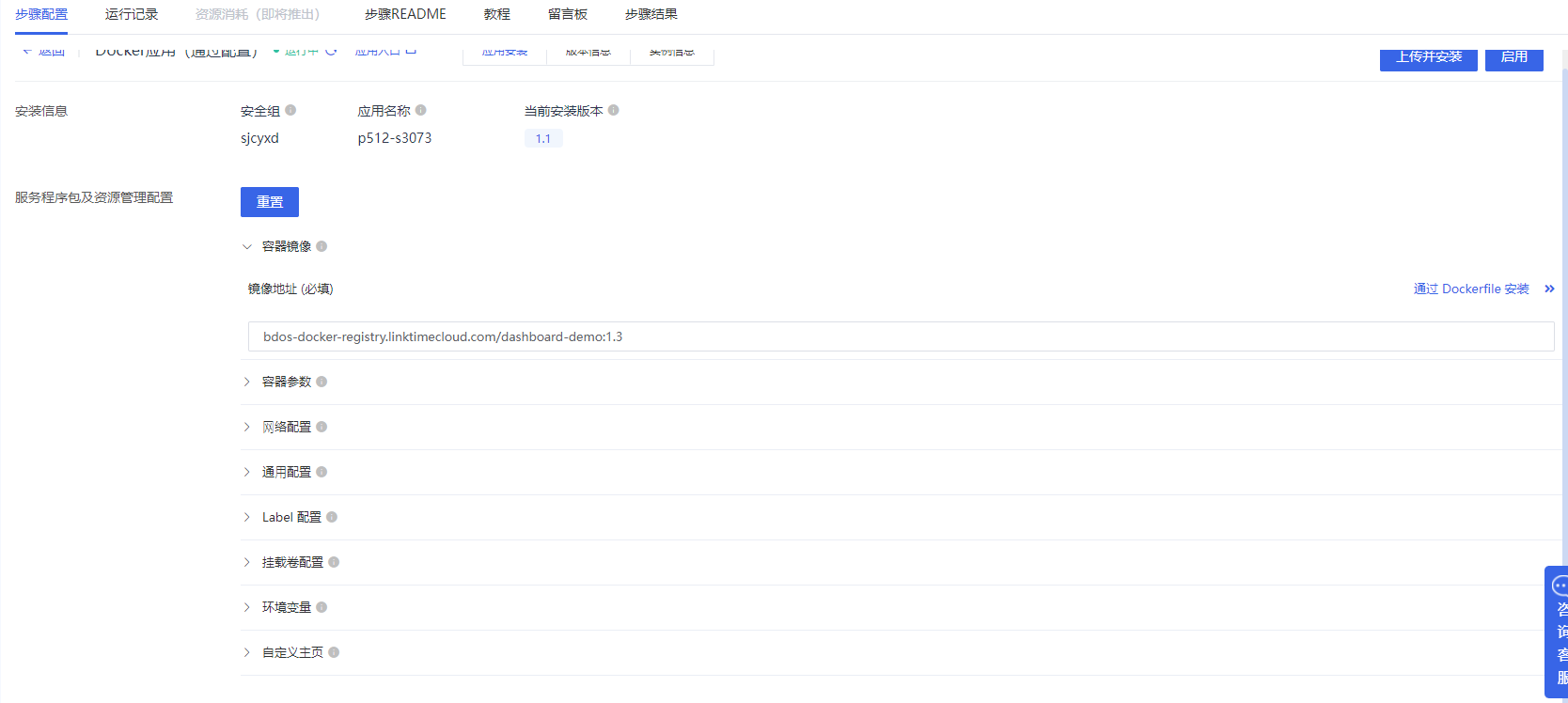
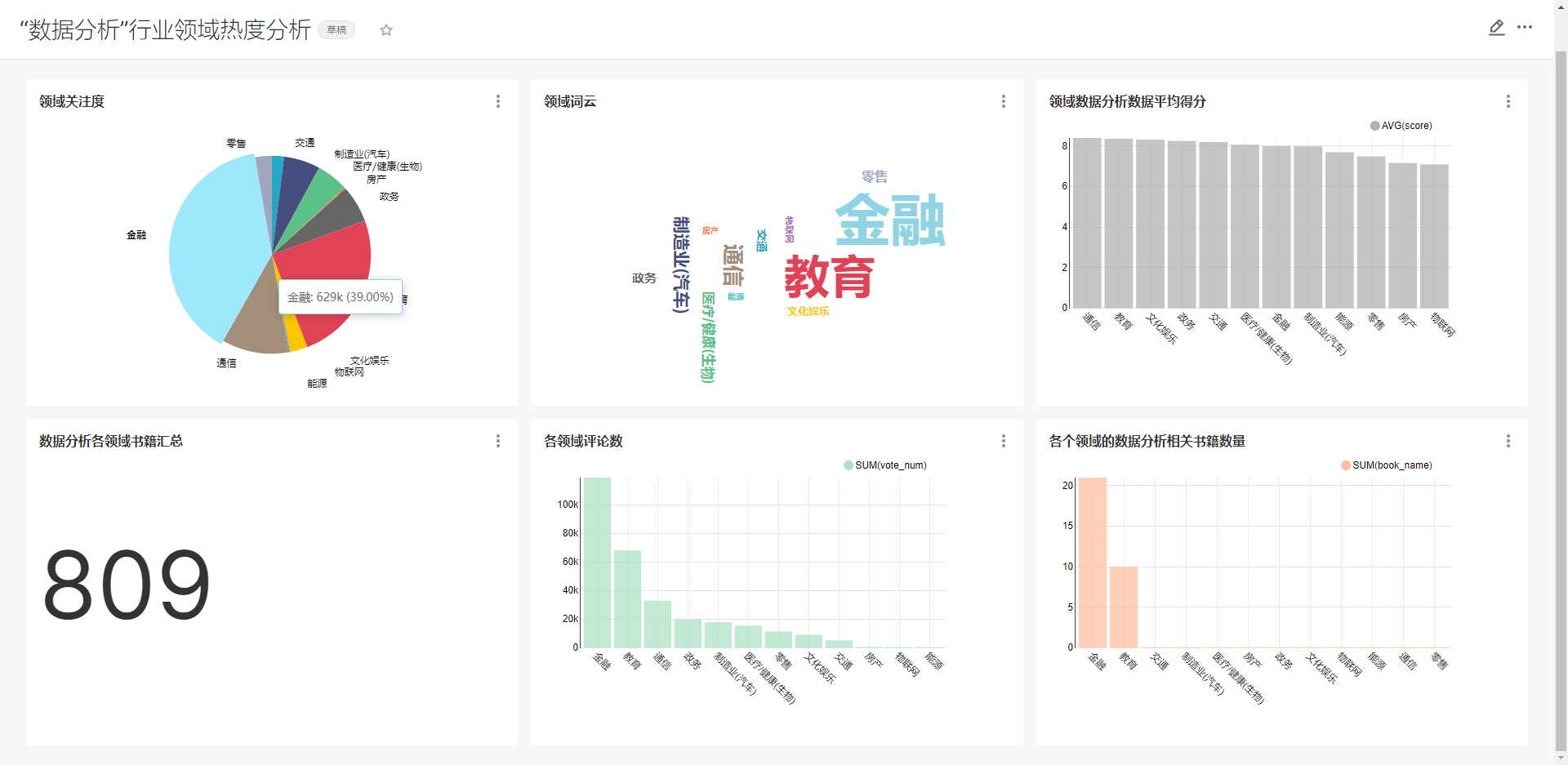
最终大屏展示如下图所示:

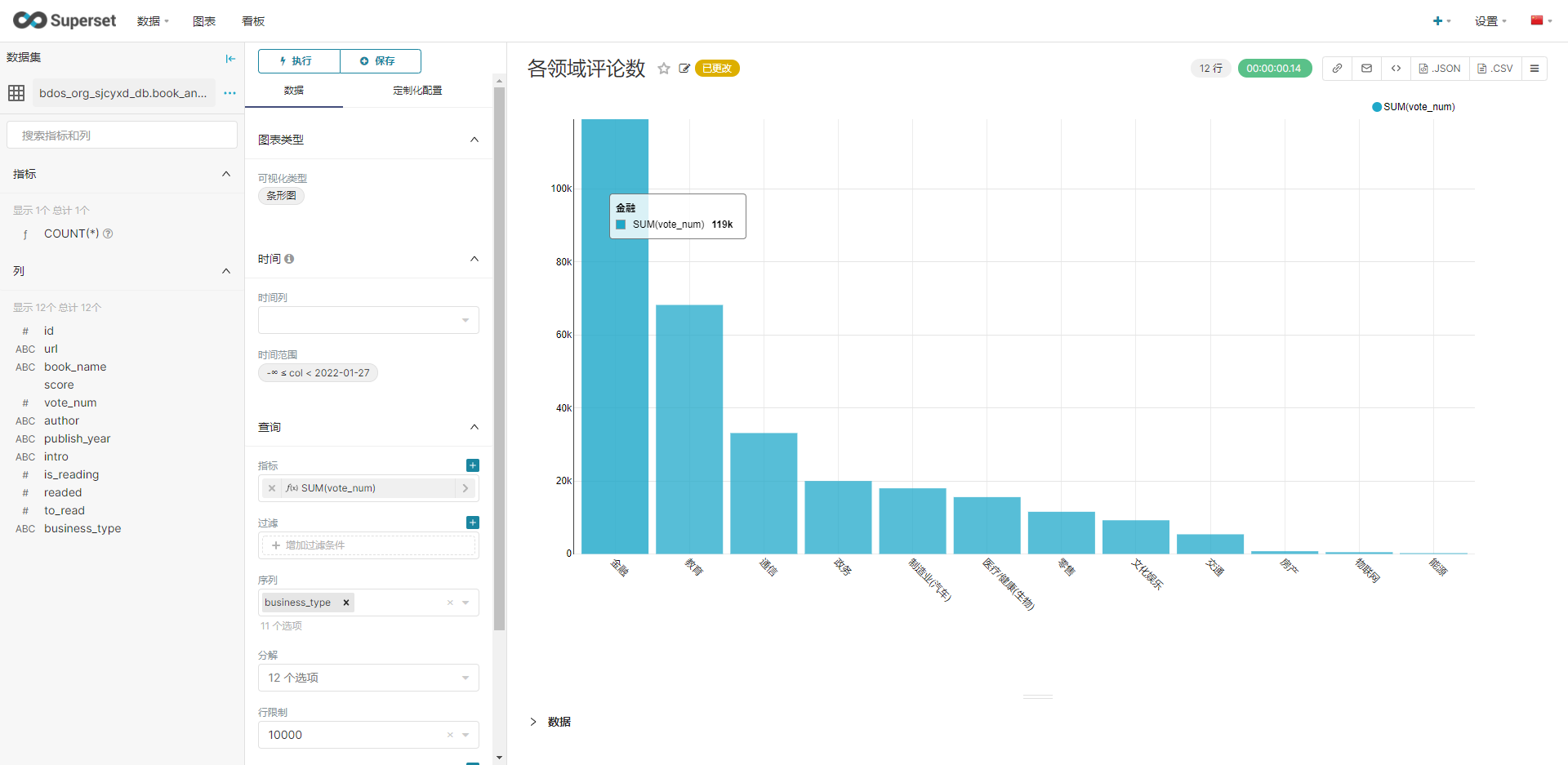
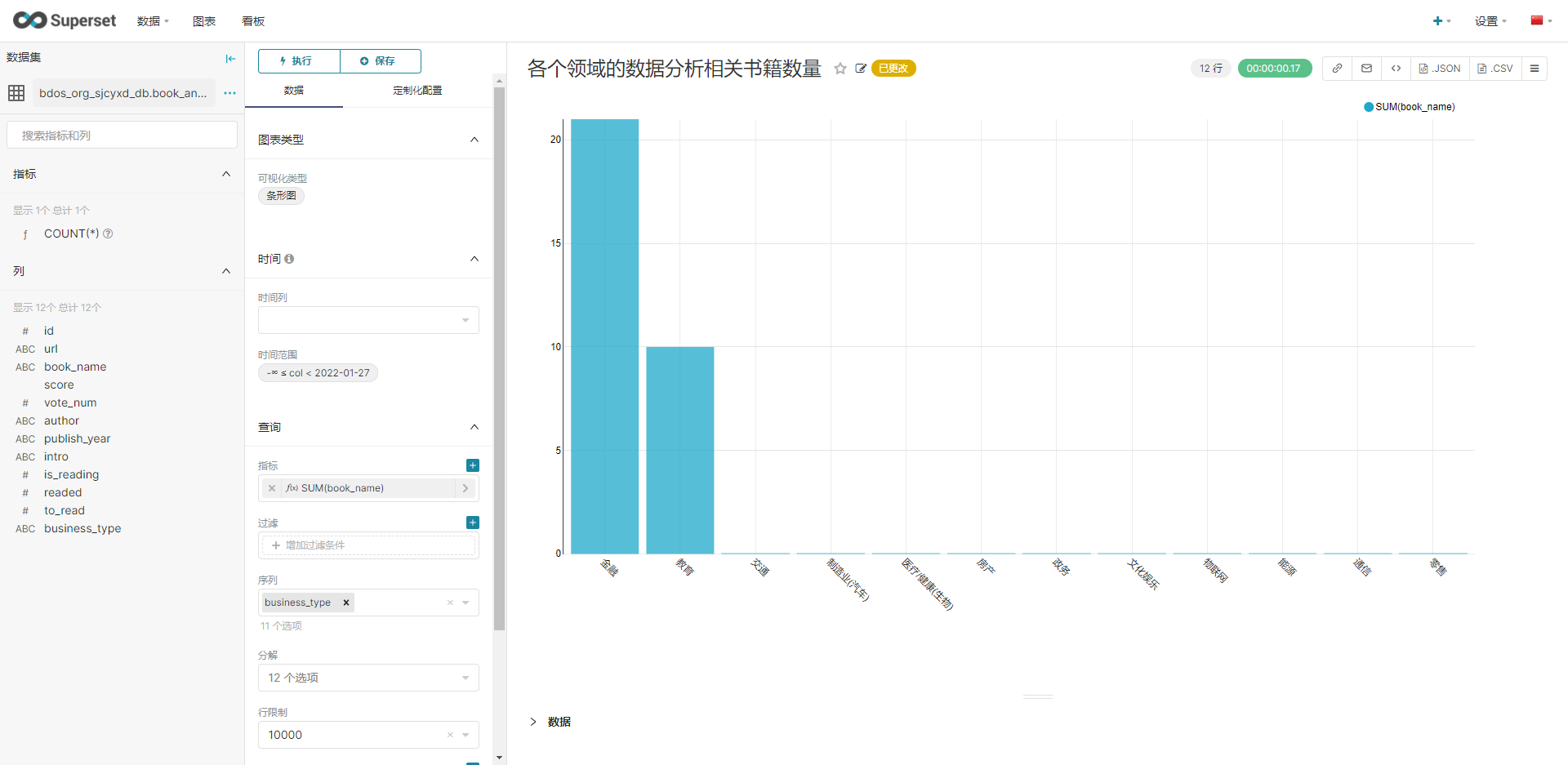
7.Superset,通过Superset对结果数据进行BI可视化展示
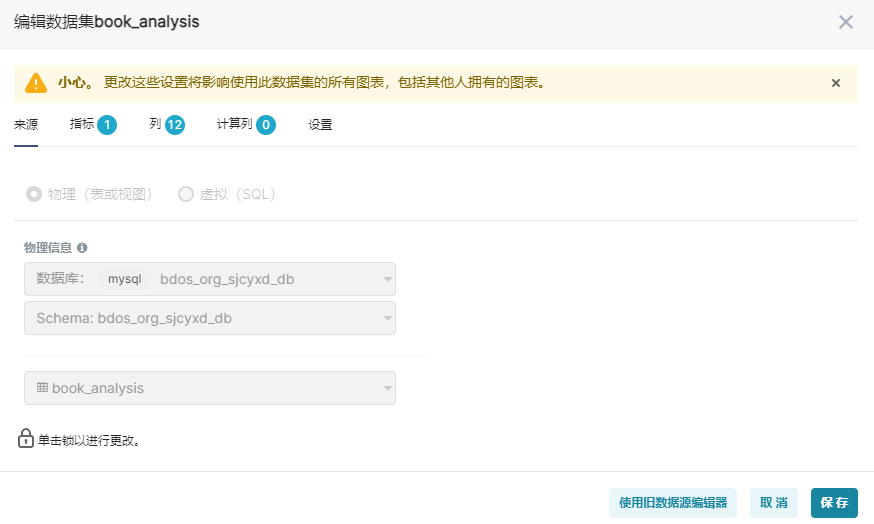
首先在superset中添加数据集,数据库:bdos_org_sjcyxd_db,Schema:bdos_org_sjcyxd_db,表名:book_analysis,具体见下图:
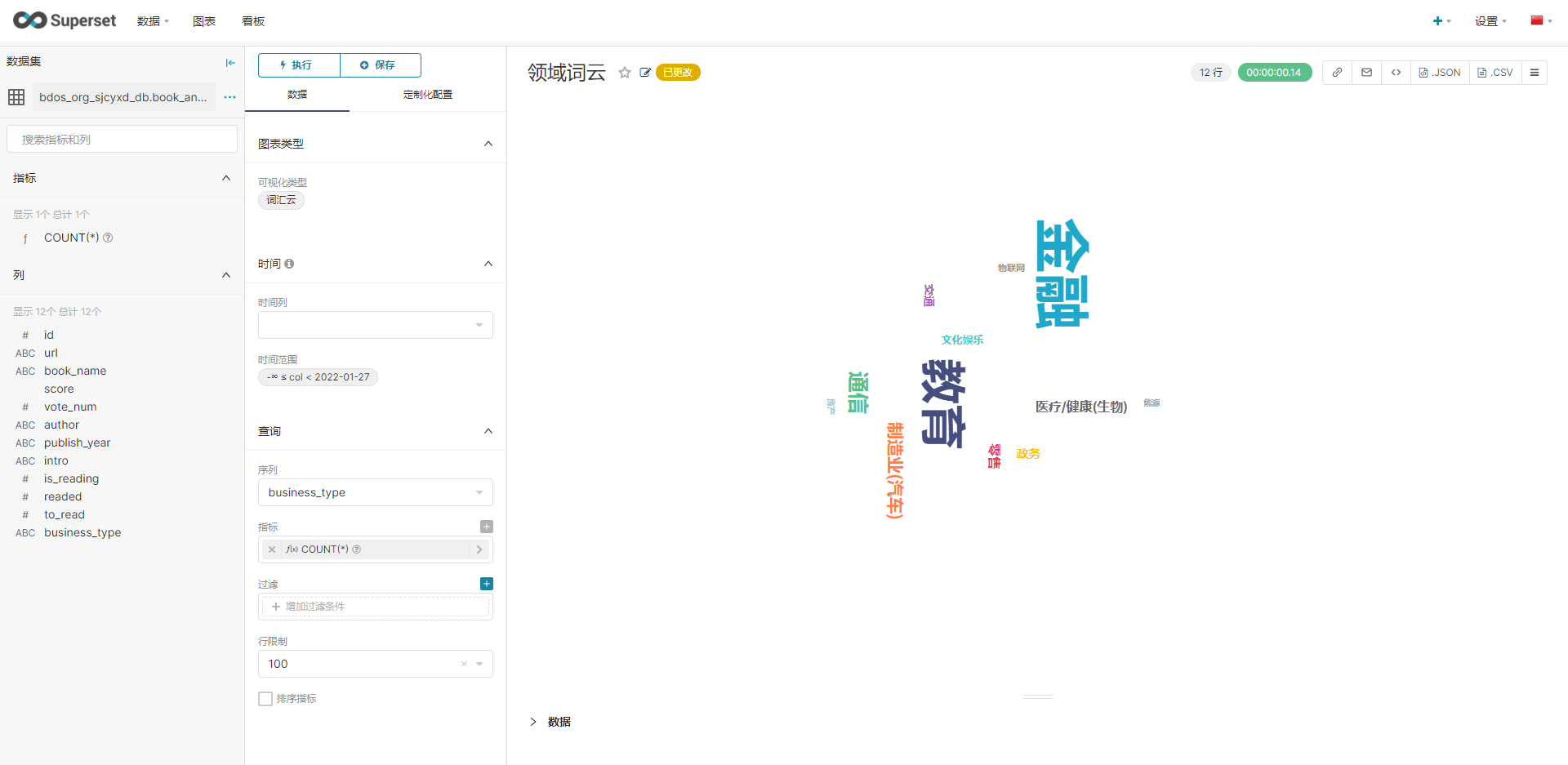
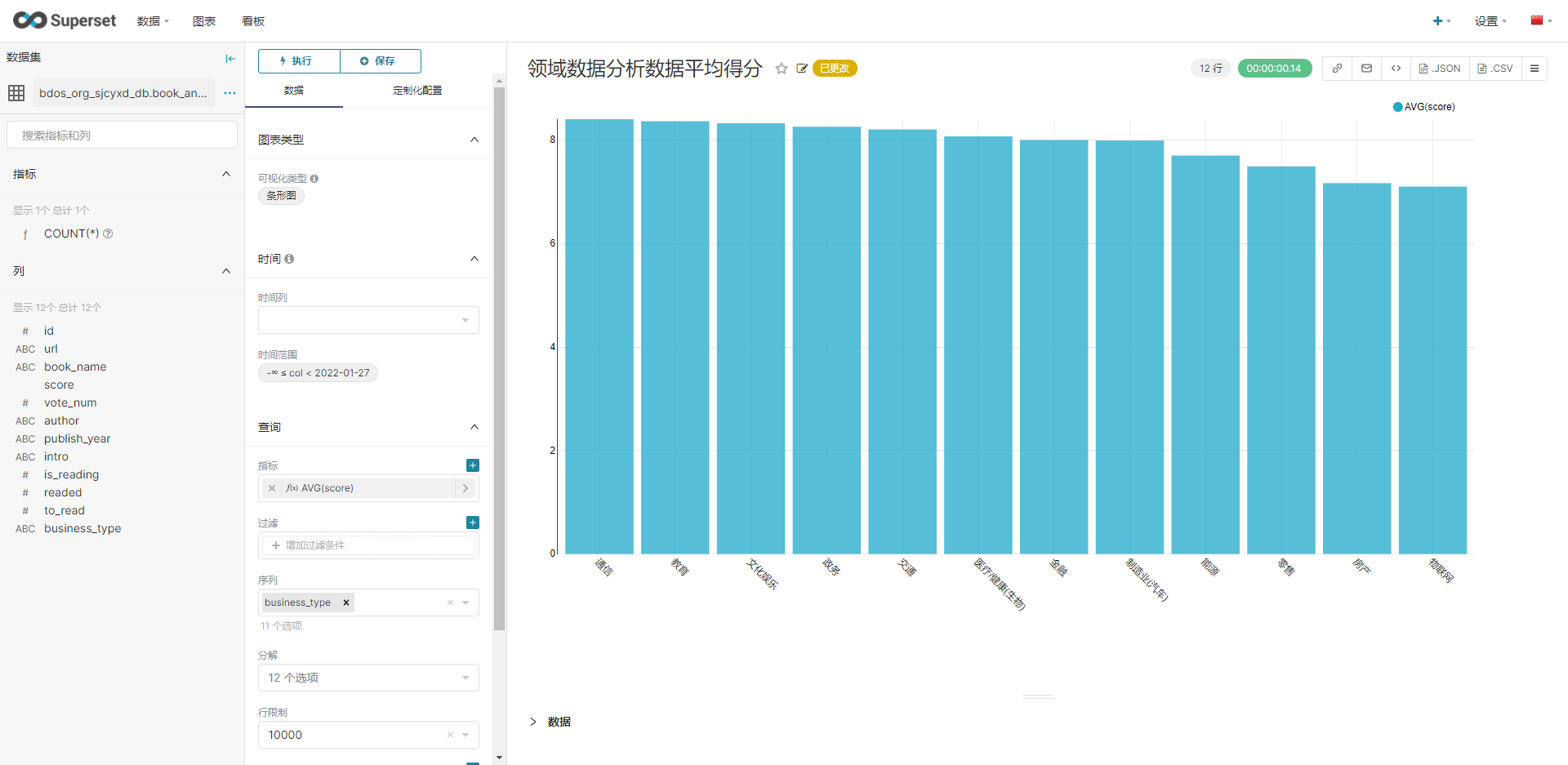
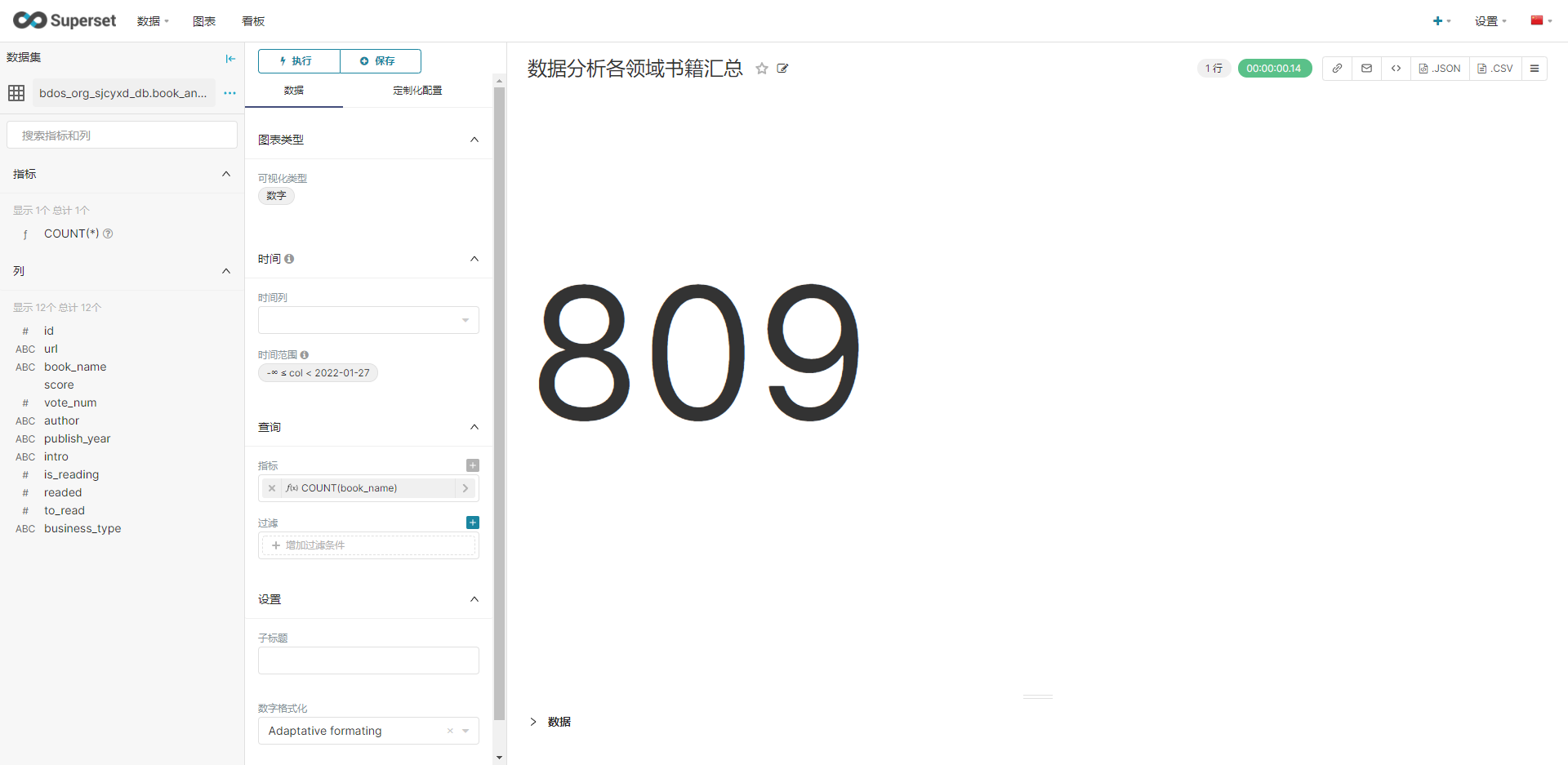
新建看板,然后进行下图配置,分别生成各类图标。

欢迎访问网站,注册体验BDOS Online,网站地址:https://bo.linktimecloud.com/

留言
评论
暂时还没有一条评论.