成功的数据驱动型公司为什么会采用Data Mesh?
许多企业正在投资下一代数据湖,希望大规模普及数据以提供业务洞察力并最终做出自动化的智能决策。但尽管投入了时间、金钱和精力,数据仓库和数据湖在以当今组织的规模和速度应用时还是会失败,此时Data Mesh或许是更好的选择。
一、模式转变
每隔一段时间,新的解决问题的方式就会出现并改变一切。有时是采取新技术,新的基础架构或者新服务的形式,有时候则是由于市场本身的迫切需求,前者需要工程团队来推动变革,而后者很可能直接从业务中“寻求帮助”,这正是驱动行业发展最强大的力量。
随着数据(管理,处理,治理等)生态系统在过去十年中得到迅速的发展,在早期采用者证明数据可以产生价值之后,越来越多的公司开始投资并转型为数据驱动型公司。这一浪潮推动了我们今天非常了解和使用的所有大数据和云计算技术的开发。
这种“数据淘金热”的重点是打破数据孤岛并将数据集中到平台中,越来越快地向分布式架构、混合云推进,甚至从IaaS过渡到PaaS到SaaS。但是它缺乏对数据所有权、数据质量保证、可伸缩治理、可用性、信任,以及数据发现性等方面的关注,而这些方面是允许客户自己查找,理解和安全使用数据,以提供业务价值的关键因素。
Data Mesh便是这种范式的转变,它起源于现实世界中的数据湖或平台领域。由于它利用了现有技术并且不受特定底层技术的束缚,因此它所承诺的结果具有革命性,至少我们认为是革命性的。
它是一种利用领域驱动(domain-driven)设计的组织和体系结构模式,即设计面向业务而不是面向技术的数据域的能力。我们可以看到这种模式上的数据转换类似于单体Web服务过渡到领域驱动设计的微服务。
二、当Data Lake变成Data Mess
为了更好地理解Data Mesh及其架构原理的主要优势,我们需要退后一步,看看在这种新范式之前,数据管理的最新技术(在大多数情况下仍然是最新技术)。
在过去的几年中,数据管理的主要趋势是创建一个单一的集中式Data Lake(通常在内部构建)以实现集中式数据治理和集中式处理平台。虽然这需要巨大的技术投入,但事实证明是成功的。不过从组织和技术角度来看,这种集中式的Data Lake会因为一些原因而适得其反。
创建Data Lakes时,第一个口号是打破孤岛,这意味着要尽快建立数据管道,以将数据从外部系统导入Data Lake。数据湖的内部数据工程师团队通常负责设计这些流程。集成工作是从系统角度进行的,即让我们了解如何从外部系统中获取数据并将其引入数据湖。这是通过种类繁多的专用或通用ETL(提取,转换,加载)作业或CDC(更改数据捕获)工具做好的。集成后,数据所有权将自动落入数据工程团队的手中,他们通常在数据文档,数据质量等方面与源系统达成一致的过程中并不需要付出太多的努力。
当源系统发生某些变化时,这种基于集成的方法会导致更糟的情况:模式更改,源域规范不断演变,GDPR引入,随便命名……这是一个无法扩展的模型,尤其是对于跨国公司集中来自不同数据的数据而言分支机构/国家/地区和相关法律/法规,因为源系统不了解数据仓库的过程,他们不了解数据消费者的需求,也不专注于为其数据提供数据质量,因为这不是其业务目的。
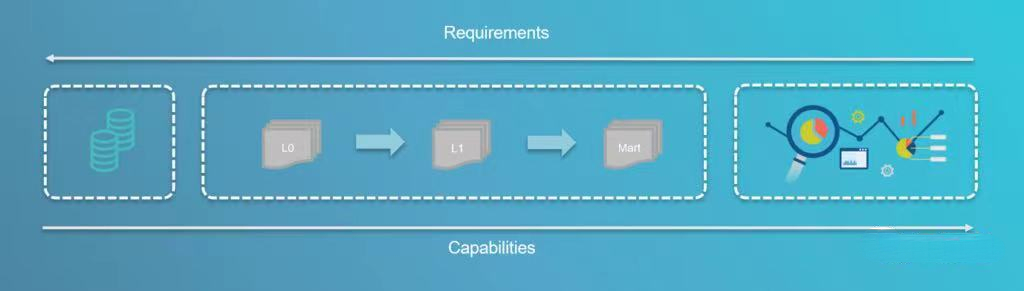
Data Lake的另一个经典问题是分层结构,其中分层通常是技术性的(清理,标准化,协调)。您可以将这些层视为数据和业务需求之间的固定开销,这些开销正在持续减慢价值创造的过程。
三、现代化的Service技术栈(SOA)
如何能构建好一个数据产品呢?一个中心化的团队不可能能够处理好这件事,数据产品必须由拥有数据的团队本身去负责构建,通过一个去中心化的方式;因为他们才是理解数据的那批人。而去中心化则关联到了其他三个Data Mesh原则,正是这里导致了大家对待Data Mesh的很多困惑。为揭开这些原则的神秘面纱,接下来会和现代的面向Service技术栈来做个对比。现代化的Service技术栈有如下几个重要的特征:
- 去中心化的微服务API ownership和架构
- 业务自助的服务基础设施平台
- 联合的服务治理
现代化的Service技术栈普遍都是去中心化的(a)。通常有成百上千不同的服务被几十个或者几百个团队所拥有。每个团队自己负责定义,构建并维护管理自己的API。
这些团队也负责部署和监控自己负责的服务(b)。自行决定部署周期增强了功能迭代的效率:开发人员不再需要等待另一个负责按按钮的团队来统一负责部署变更。同时不再有一个多余的中心化团队来负责部署那些他们根本不理解的服务。
但是,不是所有的应用开发人员都有足够的技术能力去定义好的Service API并且负责处理复杂的部署问题。服务架构团队提供的服务治理(c),DevOps的文化以及嵌入到每个团队中的SRE工程师成为了对这种去中心化模式的一种补充。
中心化的团队负责定义标准的数据序列化格式,服务框架,API模型设计原则和各种兼容性规定。这些“服务架构”或者“服务平台”团队通过构建实现这些标准(以及进行约束)的工具来帮助应用开发者来生成优雅的服务脚手架。同时会出现一个类似“设计审核委员会”的存在来为应用开发者设计API 数据模型进行指导。
相似的,DevOps的文化和嵌入式的SRE工程师的出现帮助应用开发者稳健地部署升级自己的服务。基于DevOps理念中的一系列自动化前置检测工具(比如灰度,小流量,预生产环境,A/B实验等),开发者可以放心地部署自己的服务。高度演化的DevOps团队甚至拥有自动化的rollback(当errorrate过高时)。除此之外,SRE工程师在应用开发团队当中还能协助解决各类operation上的问题并且开发相关工具。
Data Mesh就是要将这些面向Service的最佳实践重新运用在数据层当中。应用开发团队不仅仅需要定义业务逻辑的API(通过Service的方式),也需要定义自己拥有的数据。而这两者所需要的技术架构和组织文化结构基础也是非常相似的。
四、组织文化
只是拥有对应的技术并不足以推动Data Mesh的发生和落地。向去中心化数据流水线(Data Pipeline)和数据仓库(data warehouse)的演变也需要组织内部对应的的文化更迭。
就好像应用开发者不一定有足够的技术能力去定义良好的Service API,他们也许也没有足够的技术能力去定义一个良好的数据产品或者运行一个数据流水线。这是一个和SOA(Service-Oriented Architecture)架构相同的问题,解决方案也是类似的。数据架构团队,DataOps的文化,和嵌入式的数据工程师可以来帮助闭合技能上的不足并且提供规范保障。
我们需要有“数据基础架构团队”或者“数据平台团队”来构建分布式自助式的数据基础平台和能力——这些东西已经在技术架构的章节里说过了。基础架构团队也必须负责去构建DataOps所需要的工具去规范和约束DataOps的最佳实践。使用数据质量检查和监控(Anomalo和BigEye)、测试流水线(schema和data)以及服务部署的最佳实践。DataOps非常关注“敏捷”文化,鼓励工程上的精益求精和最佳实践以及流程上的管控。它的文化内容几乎和工具一样多。
中心化的委员会制来制定标准的数据序列化格式,格式转换框架和数据模型以及兼容性的规则。(数据模型)设计委员会应运而生来为应用开发者设计模型提供指导。我们在LinkedIn大约10年前就有专门的团队负责审核Service API和数据产品并负责提供指导了。
正如SRE嵌入应用程序开发团队一样,数据工程师也可以嵌入。嵌入式数据工程师负责定义数据产品,维护数据管道,并在团队内部负责构建数据相关的工具。
最重要的是,需要让应用开发团队相信“数据”是他们需要投入时间的“产品”。这并不那么容易;因为这不是他们“真正”要做的东西。在组织中寻找Champions可能有用。随着像Stripe的Sigma这样面向用户的数据产品的普遍化,应用开发端将面临和数据仓库团队一样的痛苦。工程师将需要自己开始构建自己的数据产品;但这对他们来说是直观的——这和他们在SOA和Service DevOps中做的事情本质上是一样的。如果一定要定一个Data Mesh MVP对组织文化的需求,有以下几点:
- 应用开发团队认同需要自己负责负责构建自己的数据产品
- 在数据产品和数据基础设施中将过去DevOps的最佳实践运用起来
- 有良好定义的数据产品标准并通过系统化的方式被强制约束起来。
当然,以数据的力量驱动企业价值,尝试与探索新的数据解决方案与工具更为关键。
现在,智领云为大家提供了数据开发平台的在线体验版本,即国内第一个K8s在线大数据平台,即开即用,让数据开发更简单。扫码免费注册,更可以点击 立即体验 ,查看众多创新项目示例(PC端查看)。

材料主要来源于:《成功的数据驱动型公司为何采用Data Mesh》云原生 soundhearer
《基于 Data Mesh 构建分布式领域驱动架构的最佳实践》GRAHAM STIRLING
#智领云公司简介#
武汉智领云科技有限公司成立于2016年8月,专注于云计算、大数据领域前沿技术的研发。公司创始团队成员来自于推特(Twitter)、苹果(Apple)和艺电(EA)等硅谷知名企业,是硅谷最早一批从事云计算和大数据研究与实践的技术专家,拥有十多年的云计算、大数据系统的系统架构和系统开发经验。公司作为拥有云计算、大数据领域核心技术的高科技企业获得了来自硅谷和国内知名投资人和投资机构的投资。公司于2019年4月获得线性资本数千万元pre-A轮融资,2020年7月获得由金沙江联合领投、线性资本跟投的数千万元A轮融资。
公司为企业级客户提供以云原生DataOps为底座的大数据平台数据中台/大数据平台数据中台系统解决方案;帮助企业搭建数据和AI中台实现云原生DataOps,轻松打造业务数据能力闭环,掌握全面、及时、更多维度的业务现状,提升数据驱动应用的迭代和发布速度;实现系统资产(人/资源/数据/应用) 在同一系统中的统一管理,建立数字化运营体系,并最终完成数据驱动的数字化转型。
公司在能源、教育、医疗健康、物联网、金融等行业同国内外很多知名企业和上市公司建立了合作关系,包括:D2IQ、埃克森美孚(中国)、一汽集团、极狐(GitLab中国)、南瑞信通、万达信息股份、中亦安图、深圳智宇、长江云通、湖北楚天云、万方数据股份、天喻教育、广州畅驿、上海和今、南京赛信等。公司与合作伙伴在多个领域中展开紧密的合作,充分利用各自的优势,共同为企业客户提供更有价值的云计算和大数据产品和技术服务。
留言
评论
暂时还没有一条评论.