DataOps: A New Discipline
I started using Hadoop in 2008 in my first job at Ask.com when its expensive Oracle cluster couldn’t handle the ever increasing analytics workload and had to switch to Hadoop. In my second job at Twitter as a data engineer, I was in the front line to participate and drive how data enables and empowers almost all Twitter’s products. Since 2008 I have witnessed the power of data, which I prefer to call instead of “big data”, and how it transformed the world. The transformation is not in the slightest sense if you read the articles about how Cambridge Analytics influenced the US election in 2016.
However, after more than 10 years since the buzzword “big data” emerged, big data seems to be used only for a very limited number of companies. Almost all unicorns in silicon valley use big data extensively to drive their success. Companies in China like BAT have also mastered the art of big data, and we have decacorns like Toutiao built primarily on big data technologies. There are many jokes about how big data is so hard to use, but it is a sad truth that, for most of the companies, big data is either still a buzzword or too hard to implement.
Luckily a new discipline is on the rise and is the key to unlock the power of data for the ordinary companies. DataOps, given the obvious similar name to DevOps and also the role similar to DevOps to software development, is the way data engineers want to simplify the use of data and really make data-driven a reality.
Today we will briefly introduce DataOps and why it is important for every company that wants to drive real value from their data.
What is DataOps
The definition of DataOps on Wikipedia is:
DataOps is an automated, process-oriented methodology, used by analytic and data teams, to improve the quality and reduce the cycle time of data analytics.
The page for DataOps on Wikipedia was only created in February 2017, which says a lot about this new discipline. The definition of DataOps surely will evolve over time, but the key goal is very clear: to improve the quality and reduce the cycle time of data analytics.
Simply put, DataOps makes data analytics easier. It won’t make data analytics easy, since good analytics still need a lot of work, like deep understanding the relation of the data and the business, good discipline to use the data, and a data-driven culture for the company. However, it will vastly improve the efficiency people use the data and lower the barrier to use the data. Companies can start using the data much faster, much earlier, much better, and with much less cost and risk.
Problems DataOps Solve
Most of the applications of big data can be categorized as either AI (artificial intelligence) or BI (business intelligence). AI here has a broader meaning that its canonical definition, which includes machine learning, data mining, and other technologies that derive previously unknown knowledge from data. BI applies more statistical methods to summary massive data into simpler data points for a human to understand. Simply put, AI is using various algorithms on data to compute something new, and BI is counting numbers that people can understand.
Writing an AI / ML program is not hard. You could set up a TensorFlow face recognition program in a few hours. Using Matlab to plot some data, or even Excel is not hard either. The problem is that, to actually use the results in production to support user-facing products or to decide your company’s fate based on these magical results, you need a lot more than just the manual work.
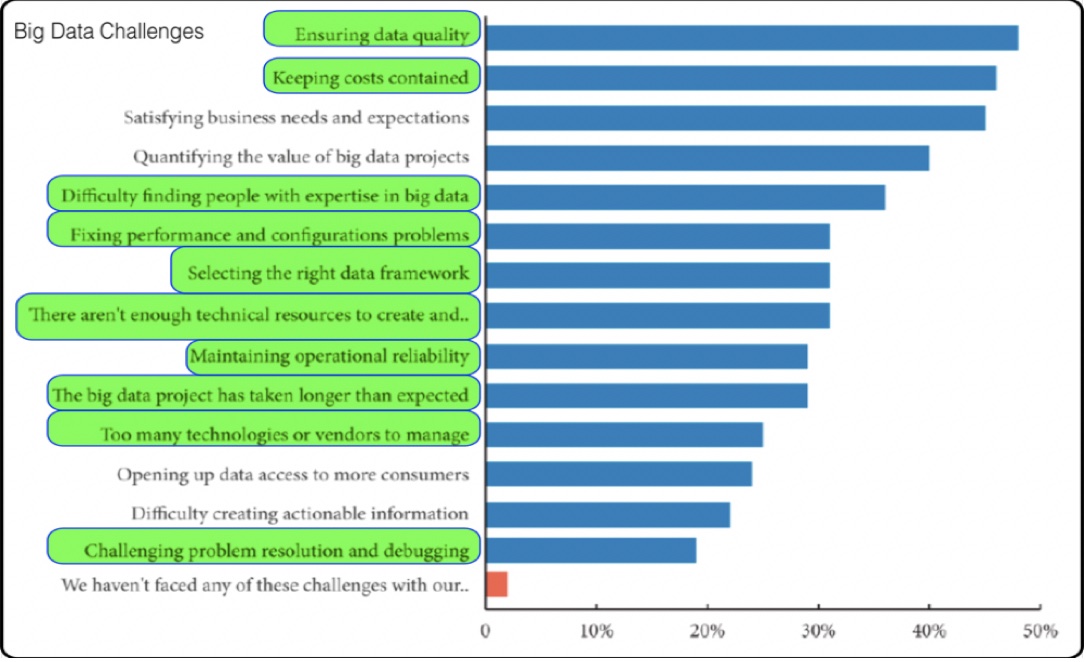
One survey by Dimensional Research found that the following problems are most difficult for companies that want to implement big data applications:
- Ensuring data quality;
- Keeping the cost contained;
- Satisfying business needs and expectations;
- Quantifying the value of big data projects;
- Difficult finding people with expertise of big data;
- Fixing performance and configuration problems;
- Selecting the right data framework;
- There aren’t enough technical resources;
- Maintaining operational reliability;
- The big data project has taken longer than expected;
- Too many technologies or vendors to manage;
- Opening up data access to more consumers;
- Difficulty creating actionable information;
- Challenging problem resolution and debugging.
Another research by Google data analysts found that, for most machine learning projects, only 5% of the time is spent on writing ML code. The other 95% of the time is spent on setting up the infrastructure needed to run the ML code.
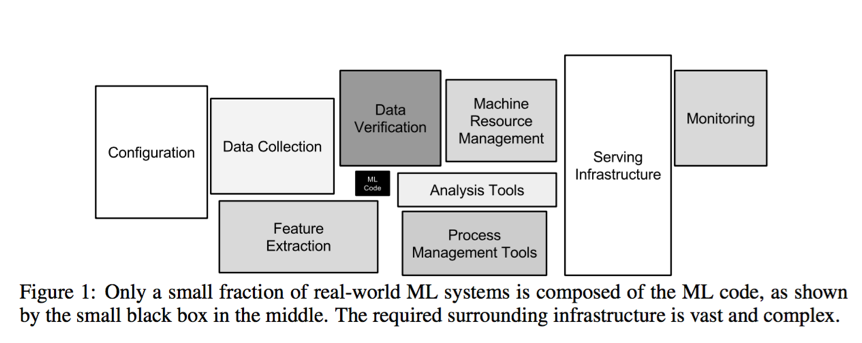
In both types of research, we can easily see that a lot of the hard work is not actually writing the code. Preparations for the whole infrastructure and running the code in production efficiency are costly and risky.
In the Google research, they cited my former colleagues Jimmy Lin and Dmitriy Ryaboy from the Twitter Analytics team that much of the work can be described as “plumbing”. DataOps, actually, is making the plumbing much easier and more efficient.
DataOps Goals
DataOps aims to reduce the whole analytics cycle time. Therefore, from setting up the infrastructure to applying the results, it usually requires to achieve the following goals:
- Deployment: including the basic infrastructure and the applications. Provisioning new system environment should be fast and easy, regardless of the underlying hardware infrastructure. Deploying a new application should take seconds instead of hours or days;
- Operation: scalability, availability, monitoring, recovery, and reliability of the system and the applications. The user should not worry about the operations and can focus on business logic;
- Governance: security, quality, and integrity of data, including auditing and access controls. All data are managed in a cohesive and controlled manner in a secure environment that supports multi-tenancy.
- Usability: the user should be able to choose the tools they want to use for the data and easily run them as they need. Support for different analytics / ML / AI frameworks should be integrated into the system;
- Production-ready: it should be easy to transform analytics programs into production with scheduling and data monitoring; building a production-ready data pipeline from data ingestion to analytics, and then data consumption should be easy and managed by the system.
In short, it is similar to the DevOps methodology: the path from writing the code to deploying to production, including the scheduling and monitoring, should be done by the same person and follow a system-managed protocol. Also similar to DevOps that provided many standard CI, deployment, monitoring tools to enable fast delivery, by standardizing a lot of the big data components, newcomers can quickly set up a production ready big data platforms and put the data to use.
DataOps Methodologies
The main methodologies for DataOps are still under rapid evolution. Companies like Facebook and Twitter usually have their Data Platform team handle the operations and achieve the goals. However, their approaches are mostly integrated with their existing Ops infrastructure and thus usually not applicable to others. We can learn from their successes and build a general big data platform that can be implemented easily by every company.
To build a general platform required by DataOps, we think the following technologies are required:
- Cloud architecture: we have to use a cloud-based infrastructure to support the resource management, scalability, and operational efficiency;
- Containers: containers are critical in the implementation of DevOps, and its role in resource isolation and providing a consistent dev/test/ops environment is still critical in implementing a data platform;
- Real-time and Stream processing: real-time and streaming process is now becoming more and more important in a data-driven platform. They should be the first class citizens of a modern data platform;
- Multiple analysis engines: MapReduce is the traditional distributed processing framework, but frameworks like Spark and TensorFlow are used more and more widely every day and should be integrated;
- Integrated Application and Data Management: application and data management, including life-cycle management, scheduling, monitoring, logging support, is essential for a production data platform. Regular practices for DevOps can be applied to the application management, but extra efforts are needed for data management and the interactions among applications and data;
- Multi-tenancy and security: data security is almost the most important issue in a data project: if the data can’t be secured, it is mostly can’t be used at all. The platform should provide a secure environment for everyone to use the data and have every operation authorized, authenticated, and audited.
- Dev and Ops tools: the platform should provide efficient tools for the data scientists to analyze the data and produce the analytics program, for the data engineers to operate the production data pipelines, and for other people to consume the data and results.
Our Thoughts
The current big data technologies are powerful, but they are still too hard for ordinary people to use. Implementing a production-ready data platform is still a daunting task. For the companies that have already started the journey, their data platform teams are still doing similar things as others have done or reinvented the wheels most of the time.
There are companies that have realized these problems (Qubole, DataMeer, Bluedata, etc) and started to approach a general solution with different methods. Some of them use container-based solutions and some of them build their platforms from a Hadoop-centric point of view.
We (Linktime Cloud) are also working on a new generation data platform. Instead of treating big data application especially, we are using a proven distributed operating system (Apache Mesos) and containerizing most of the big data applications to run on Mesos in a uniform manner. This approach allows us to standardize the management of the application and the data, thus providing the key technologies and achieving the goals as described above.
We believe that, in the near future, instead of just of installing Hadoop and running some Hive queries, companies will use an integrated big data platform to build really big data applications quickly and easily.
留言
评论
${{item['author_name']}} 回复 ${{idToContentMap[item.parent] !== undefined ? idToContentMap[item.parent]['author_name'] : ''}}说 · ${{item.date.slice(0, 10)}} 回复
暂时还没有一条评论.