估值380亿美元,AWS与微软参投,大数据独角兽Databricks凭什么IPO?
当外界还在惊叹280亿美元高额估值数额时,短短7个月,Databricks的估值再升100亿美元。
美国当地时间8月31日,由 Apache Spark 初始成员创立的大数据初创公司 Databricks 宣布获得 16 亿美元 H 轮融资,新一轮融资由摩根士丹利的 Counterpoint Global 领投,此外,该行业的三个顶级云供应商 AWS、微软、以及 CapitalG都参与了此轮投资。本轮融资过后,Databricks的估值已经飙升至380亿美元。也就是说,距离上一轮10亿美元的G轮融资才7个月时间,其估值就已经增加了100亿美元。

“分析与数据管理”投资热潮高涨,Databrick就是典型代表
Databricks联合创始人兼首席执行官 Ali Ghodsi 表示,这轮 16 亿美元的融资证实了他们对任何云上的数据和人工智能的开放和统一方法的愿景,且这笔资金将主要用于加速Data Lakehouse(湖仓一体)的产品创新和市场开拓。

Crunchbase 数据指出,自云服务计算公司 Snowflake 在近一年前成功进行首次公开募股以来,风险资本对分析和数据管理初创企业的投资热潮已经达到了近 170 亿美元。其中有 150 多亿美元是在过去 8 个月里筹集的,而 Databricks 一直是其中的典型代表。
毫无疑问,Databricks 和 Snowflake 引领了一种新的云原生模型分析和商业智能模型。他们从不同的角度来解决问题,Snowflake 是集中式共享模型的缩影,而 Databricks 则强调分布式架构。不过,也有很多分析师认为他们最终的业务发展走向可能会趋于一致。譬如,Snowflake 最近就放弃了”warehouse”一词,而采用了更无定形的”data cloud”。
百亿估值的Databricks,到底是做什么的?
从Databricks官方主页上的标语:“一个 Lakehouse 平台,承载所有数据、分析和人工智能”出发,我们来了解一下Databricks。

从本质上讲,Databricks是一家计算公司,通过解决三个关键问题中的以下两个,提出了一种搭建数据流水线的低代码解决方案:
- 如何使用数据?
- 如何把数据从源头向下游汇集和转化?
Databricks诞生于2013年,创始人来自Apache Spark的创始团队,包括加州大学伯克利分校的专家学者。Databricks以Apache Spark开源技术为基础,创建了一系列蓬勃发展的开源项目,包括Delta Lake、MLflow、Koalas等。截止2020年底,Databricks已经建立了一家拥有1500多名员工的公司,为数千个数据团队提供数据分析、数据工程、数据科学和人工智能方面的帮助。
2020年初,Databricks发表了一篇博客文章,分析了一直观察到的一个趋势:向Lakehouse架构(湖仓一体,即数据湖技术与数据仓库技术结合为一体)迈进。该体系结构基于开放架构,把构建在低成本云对象存储之上的数据湖的灵活性与 ACID 事务、数据模式强制执行和数据仓库相关的性能结合起来;
2019年,Databricks推出了Lakehouse的关键开源技术Delta Lake;
2020年6月,Databricks宣布收购以色列初创公司Redash并基于其技术推出了Lakehouse关键开源技术Delta Engine。同年,Delta Lake、Apache Spark和Databricks统一分析平台的进步,不断提高了Lakehouse架构的功能和性能。
抢滩 Lakehouse 市场,大胆拥抱开源
Ali Ghodsi 认为资本能帮助 Databricks 进一步获得市场领先地位。
“Lakehouse是一个新赛道,我们认为这个赛道中会有很多供应商,所以说这是一场地盘争夺战。我们希望快速构建并完成 lakehouse 赛道的布局。” Ghodsi 强调。
Lakehouse(湖仓一体),简单理解就是把面向企业的数据仓库技术与低廉的数据湖存储技术相结合。数据湖主要是公有云上提供的一种海量的结构化与非结构化数据的存储技术,而数据仓库主要是关系型数据的结构化数据存储与分析技术。两种技术各有其优缺点,当下企业往往分别建数据湖与数据仓库,而如果能够二者合一则可以同时获得两种技术的优点。当然,湖仓一体技术本身并不简单,整个2020年Databricks都在填补Lakehouse的技术空白。
Databricks试图提供完整的“数据流水线”方案——这意味着更多需要处理的数据、更多跑数据的机器、更多的收入。
Databricks看到了数据科学家和分析师们负责数据接入、基础架构、效率提升这些更底层的工作,所以工程师们对灵活度的要求很高,并且完全不介意多写一些代码,或是自己搭方案。
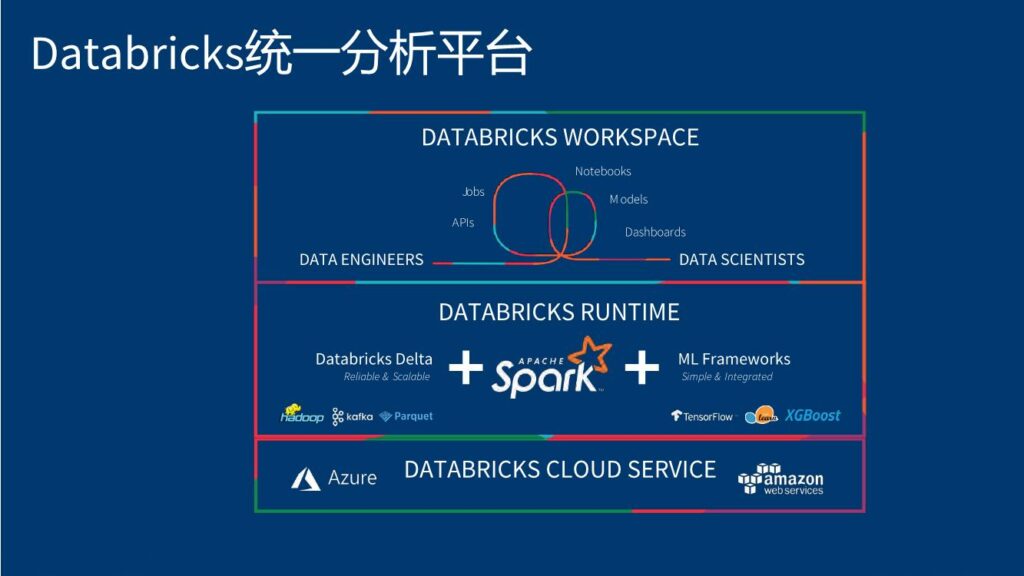
在“数据流水线”上,这些数据工程师们往往占据上游,为了赢得他们的青睐,Databricks采用的策略是拥抱开源,尤其是继Spark之后,推出了Delta Lake——一个开源的数据存储方案。开源的方案给了这些工程师们所需的自由度,使得他们能够更可预期地掌握、挪动数据。Delta的开源,意味着任何人都可以在其方案里使用优秀的“.delta”存储格式,但是这在Databricks的数据本里,有着最为方便的原生支持。与新的功能,比如“Live Table”一起,Databricks平台已经开始赢得一些硬核数据工程师的青睐。
从长远来看,能让所有与数据打交道的人们在同一个平台上协作,就有着巨大的价值。与Databricks试图提供完整的“数据流水线”方案的愿景相似,智领云云原生DataOps同样试图让数据工程师等数据工作者能够用更简洁的工具支持自己的工作与管理。
智领云云原生DataOps的目标即让数据科学家、数据工程师以及数据运维人员等不同群体,能够在一套体系、工具与方法论的支持下,敏捷且高效地从事数据开发、数据管理等工作。
智领云云原生DataOps所做的事情就是为以数据为驱动的企业与数据工作者来做减法,此减法并非删减,而是通过云原生的方式让用户能够更加方便地集成各种工具与应用,然后在上层做出数据安全、数据质量、数据集成等抽象层,从而使用户即便是在使用看起来十分复杂的DataOps技术时,也能够得心应手。
留言
评论
${{item['author_name']}} 回复 ${{idToContentMap[item.parent] !== undefined ? idToContentMap[item.parent]['author_name'] : ''}}说 · ${{item.date.slice(0, 10)}} 回复
暂时还没有一条评论.