薅羊毛神器操作指南
项目背景
在供需两旺的背景下,如何能方便快捷的获取商品优惠信息而不需翻阅优惠网站,无需加入各种福利群组,实现根据用户偏好进行千人前面的个性化优惠商品推荐,并能根据推荐优惠商品的购买情况对模型进行训练使推荐越来越精准。本项目通过BDOS Online,对薅羊毛神器应用进行打造和发布。
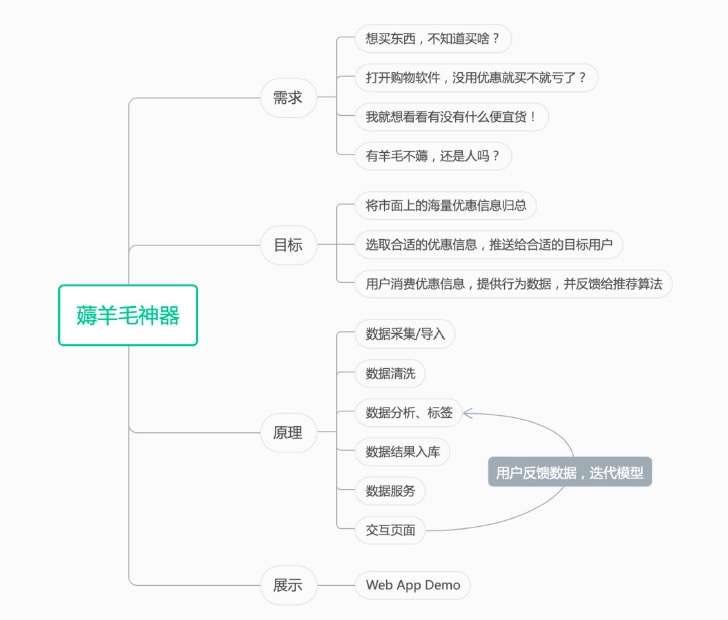
本项目采集了某电商平台的44,672条数据,并对数据进行标签分类后发送给前端应用,前端应用通过采集用户的点击选择等行为数据,对推荐模型进行训练,从而不断优化商品推荐的精准度。
项目可以分为以下几个步骤:
1.发布自定义MySQL应用,对采集的数据进行存储
2.创建Hive表
3.把原始数据从MySQL导出至Hive
4.通过JupyterNotebook的 pyspark对Hive数据进行处理,并把结果存储至发布的自定义MySQL中
5.对MySQL结果表,进行数据服务发布,通过接口的方式提供给下游应用
6.发布实时计算用户标签,提供商品数据的服务
7.发布薅羊毛前端应用
项目架构图如下:
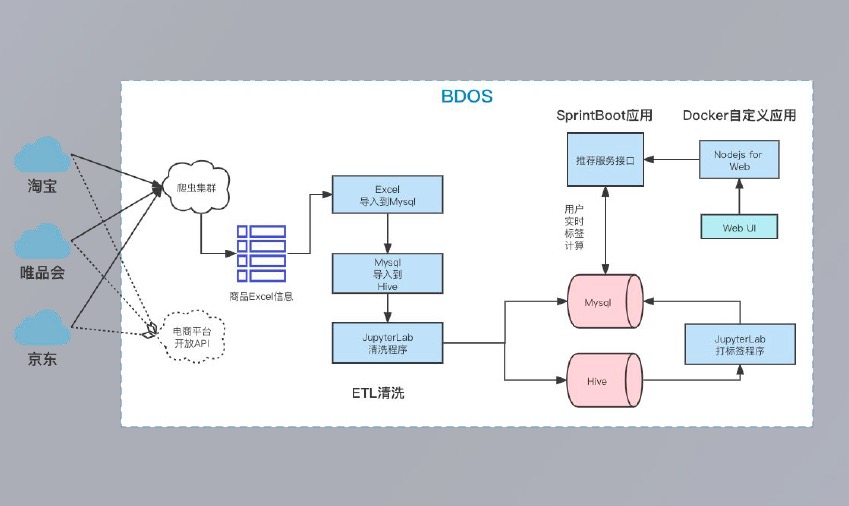
备注:为简化用户对于本项目的操作,数据采集环节已提前为用户准备好Demo数据并更新至指定的MySQL库,用户如需进行Demo数据采集至用户发布的自定义MySQL应用中,可参考如下前置工作说明进行配置。
备注:仅限机构管理员权限用户,通过BDOS Online界面【管理-数据源管理-采集和导出数据源】选择MySQL进行添加
前置工作
- 用户需有BDOS Online guest机构账号
- 用户需为机构管理员角色
- 创建机构/个人项目
| 名称 | 内容 | 备注 |
|---|---|---|
| 名称* | 用户自定义MySQL数据库别名 | |
| 数据库类型 | MySQL | 保持默认 |
| Driver | 下拉框选择 | |
| 数据库名称 | recommend | 填写指定的库名 |
| 主机 | guest-p1176-s6856-svc.guest.svc.cluster.local | 指定的主机地址 |
| 端口 | 3306 | |
| 用户名 | root | |
| 密码 | 123456 |
操作详情
1.发布自定义MySQL应用
添加【数据应用-Docker应用】步骤,参考配置进行自定义MySQL应用的发布
| 类别 | 名称 | 内容备注 | 备注 |
|---|---|---|---|
| 容器镜像 | 镜像地址 | bdos-docker-registry.linktimecloud.com/linktime-mysql:0.9.27 | 系统提供的MySQL镜像 |
| 容器参数 | 容器日志目录 | /var/log/ | 保持默认 |
| 网络配置 | 容器端口 | 3306 | 勾选负载均衡 |
| 通用配置 | CPU:0.6;MEM:512;DISK:1;Instance:1 | ||
| 挂载卷 | Container Path:/var/lib/mysql;Host Path:mysql;Mode:RW | ||
| 环境变量 | MYSQL_ROOT_PASSWORD:123456;DATA_SOURCE_NAME:root:123456@(localhost:3306)/mysql |
填写完成后,点击上传并安装
安装完成后,点击启用
用户需要通过【数据转换-ETL程序】步骤,把项目已准备好的Demo数据同步至发布的自定义MySQL中(参考前置工作对发布的自定义MySQL应用进行连接配置)
输入源:recommend.goods (示例提供的MySQL自定义应用)
输出源:recommend.goods (用户发布的MySQL自定义应用
2.创建Hive表
添加【数据分析-Hive程序】步骤
创建Hive表:org_guest.goods(org_guest为系统指定的guest机构专属库)
drop table if exists org_guest.goods;
create table if not exists org_guest.goods(
`index` bigint,
`goods` string,
`goods_url` string,
`picture_url` string,
`brand_url` string,
`price` DOUBLE,
`market_price` DOUBLE,
`discount` DOUBLE,
`category` string,
`label` string,
`label1` string
)
点击保存后,点击试运行
可通过运行记录查看运行结果
3.把MySQL表导出至Hive
添加【数据转换-ETL程序】步骤
输入源
| 名称 | 内容 | 备注 |
|---|---|---|
| 数据源类型 | MySQL | |
| 数据源 | 下拉框选择前置工作中配置的MySQL库 | |
| 表 | 下拉框选择表:goods | goods表为本项目为用户提前准备的某电商平台的原始Demo数据 |
备注:其他内容保持默认,点击下一步
输出源
| 名称 | 内容 | 备注 |
|---|---|---|
| 数据源类型 | Hive | |
| 数据源 | 下拉框选择org_guest | org_guest为本系统为用户准备的guest机构Hive库,机构成员对该库有读写权限 |
| 表 | 下拉框选择表:goods | goods表为本项目为用户提前准备的某电商平台的原始Demo数据 |
| 数据变更 | Override | 下拉框选择 |
点击下一步后,点击保存,并点击试运行
可通过运行记录查看运行结果
4.数据清洗和计算
添加【数据分析-JupyterNotebook】步骤,点击进入Jupyter后,选择pyspark进入notebook
输入:org_guest.goods输出:
- recommend.goods_label (计算性别、消费等级、折扣等级标签的结果表)
- recommend.category_shop(去除了链接无法访问的商品的结果表)
- recommend.goods_source (数据清洗后的结果表)
清洗第一步,查询必须字段不为空的数据
from pyspark.sql import SparkSession
from pyspark.sql import Row
from pyspark.sql import functions as F
goods_source = spark.sql("select * from org_guest.goods where goods_url!='' and picture_url!='' and picture_url is not null and price is not null and market_price is not null and discount is not null")
goods_source.count()
清洗第二步,增加商品id字段
added_id_goods = goods_source.select('goods', 'goods_url', 'picture_url', 'brand_url', 'price', 'market_price', 'category','discount', 'label1', 'label', F.md5('goods_url').alias('id'))
added_id_goods.count()
清洗第三步,去重数据
distinct_goods = added_id_goods.distinct().dropDuplicates(subset=[c for c in added_id_goods.columns if c in ["id"]])
distinct_goods.count()
清洗第四步,去除商品链接无法访问的商品
valid_url_goods = distinct_goods.filter(distinct_goods.picture_url.endswith('.gif') == False)
valid_url_goods.show(2)
valid_url_goods.count()
数据库连接
备注:根据实际发布的自定义应用的信息,进行MySQL配置内容修改
from pyspark import SparkContext
from pyspark.sql import SQLContext
sqlContext = SQLContext(sc)
goods_category = sqlContext.read.format("jdbc").options(url="jdbc:mysql://guest-p1176-s6856-svc.guest.svc.cluster.local:3306/recommend?characterEncoding=utf8&useSSL=false",
driver="com.mysql.jdbc.Driver",
dbtable="category_shop",
user="root",
password="123456").load()
category_shop_hash = goods_category.select('category', 'shop_name','shop_id')
source = valid_url_goods.join(category_shop_hash, ["category"], "left")
hot_goods = source.filter(F.col('label').contains('爆款') | F.col('label1').contains('爆款'))
factor_source = source.withColumn('factor', F.when(F.col('label').contains('爆款') | F.col('label1').contains('爆款'), 10).otherwise(0)).withColumn('have_picture', F.when(F.col('picture_url').contains('fav-img-loading.gif'), 0).otherwise(1))
factor_source.show(1)
factor_source.count()
保存清洗结果到MySQL中
factor_source.write.format("jdbc").option("encoding", "UTF-8").options(url="jdbc:mysql://guest-p1176-s6856-svc.guest:3306/recommend?characterEncoding=utf8&useSSL=false",
driver="com.mysql.jdbc.Driver",
dbtable="goods_source",
user="root",
password="123456").mode('overwrite').save()
计算性别标签并保存
women_goods = source.select(F.col('id').alias('goods_id'),'goods','category').filter("category like '%.women'").filter("goods not like '%男%' or goods like '%男女%'")
men_goods = source.select(F.col('id').alias('goods_id'),'goods','category').filter("category like '%.men' or goods like '%男女%'")
women_label_goods = women_goods.withColumn('label_id', F.lit(6))
men_label_goods = men_goods.withColumn('label_id', F.lit(5))
gender_label = women_label_goods.union(men_label_goods)
gender_label.write.format("jdbc").options(url="jdbc:mysql://guest-p1176-s6856-svc.guest:3306/recommend?characterEncoding=utf8&useSSL=false",
driver="com.mysql.jdbc.Driver",
dbtable="goods_label",
user="root",
password="123456").mode('overwrite').save()
计算消费等级标签并保存
min_price = source.groupby('category').agg(F.min('price').alias('min_price'))
max_price = source.groupby('category').agg(F.max('price').alias('max_price'))
category_price = max_price.join(min_price, 'category')
price_goods = source.select(F.col('id').alias('goods_id'), 'category', 'goods', 'price').join(category_price, ["category"], "left")
price_label = price_goods.withColumn('label_id', F.when(price_goods['price'] < (price_goods['max_price'] - price_goods['min_price'])/4 + price_goods['min_price'], 1)
.when(price_goods['price'] < (price_goods['max_price'] - price_goods['min_price']) / 4 * 2 + price_goods['min_price'], 2)
.when(price_goods['price'] < (price_goods['max_price'] - price_goods['min_price']) / 4 * 3 + price_goods['min_price'], 3)
.otherwise(4)).drop('price').drop('max_price').drop('min_price')
price_label.write.format("jdbc").options(url="jdbc:mysql://guest-p1176-s6856-svc.guest:3306/recommend?characterEncoding=utf8&useSSL=false",
driver="com.mysql.jdbc.Driver",
dbtable="goods_label",
user="root",
password="123456").mode('append').save()
计算折扣等级标签并保存
min_discount = source.groupby('category').agg(F.min('discount').alias('min_discount'))
max_discount = source.groupby('category').agg(F.max('discount').alias('max_discount'))
category_discount = max_discount.join(min_discount, 'category')
discount_goods = source.select(F.col('id').alias('goods_id'), 'category', 'goods', 'discount').join(category_discount, ["category"], "left")
discount_label = discount_goods.withColumn('label_id', F.when(discount_goods['discount'] < (discount_goods['max_discount'] - discount_goods['min_discount'])/4 + discount_goods['min_discount'], 12)
.when(discount_goods['discount'] < (discount_goods['max_discount'] - discount_goods['min_discount'])/4 * 2 + discount_goods['min_discount'], 11)
.when(discount_goods['discount'] < (discount_goods['max_discount'] - discount_goods['min_discount'])/4 * 3+ discount_goods['min_discount'], 10)
.otherwise(9)).drop('discount').drop('min_discount').drop('max_discount')
discount_label.write.format("jdbc").options(url="jdbc:mysql://guest-p1176-s6856-svc.guest:3306/recommend?characterEncoding=utf8&useSSL=false",
driver="com.mysql.jdbc.Driver",
dbtable="goods_label",
user="root",
password="123456").mode('append').save()
运行完成后,可通过【管理-数据表管理】查看结果表
5.发布推荐信息数据服务
添加【数据服务-API】步骤
用户通过【管理-数据源管理-数据服务数据源】,点击MySQL进行添加,配置信息如下:
| 名称 | 内容 | 备注 |
|---|---|---|
| 名称 | wool_org_ds | 用户自定义 |
| URL | jdbc:mysql://guest-p1176-s6856-svc.guest.svc.cluster.local:3306 | 用户根据发布的自定义MySQL的实际地址进行填写。备注:替换guest-p1176-s6856为实际的应用名称即可 |
| 用户名 | root | |
| 密码 | 123456 |
备注:进行机构管理员权限用户进行添加
连接完成后,进入API步骤API信息
| 名称 | 内容 | 备注 |
|---|---|---|
| API路径 | /online/guest/query | 用户可自定义/query |
| 请求方式 | Get | |
| 数据源 | 下拉框选择:wool_org_ds,自定义SQL:select * from recommend.good | 用户根据自定义填写的名称进行修改 |
API访问控制
- 如无特殊要求,可保持默认
填写完成后,点击保存,点击测试
- 输入:wool_org_ds
- 输出:调用地址:http://kong-svc.admin.svc.cluster.local:8000 (进行系统内部应用进行调用)
6.发布实时计算用户标签,提供商品数据的服务
添加【数据应用-Spring Boot应用】步骤
配置信息如下:
| 名称 | 内容 | 备注 |
|---|---|---|
| 浏览Jar包 | 下载 | 下载地址:http://linktime-public.oss-cn-qingdao.aliyuncs.com/BDOS-Online/readme/%E8%96%85%E7%BE%8A%E6%AF%9B/%E6%96%87%E4%BB%B6%E5%8C%85/hairok-4.0.1.jar |
| CPU | 0.3 | |
| App-mem | 1024 |
备注:其他内容保持默认
点击上传并安装,安装完成后,点击启用
7.发布薅羊毛前端应用
添加【数据应用-Docker应用(通过配置)】步骤
配置信息如下:
| 名称 | 内容 | 备注 |
|---|---|---|
| 镜像地址 | dev-reg-aliyun.linktimecloud.com/sheep-shaver:latest | 系统提供已打包好的薅羊毛前端应用镜像 |
| 容器参数 | /var/log/ | 保持默认 |
| 网络配置 | 容器端口:19999;Protocol:TCP;勾选负载均衡 | |
| 通用配置 | CPU:0.1;MEM:128;DISK:1;Instances:1 | 保持默认 |
| 环境变量 | BACKEND_SERVICE:http://guest-p1176-s6772-svc.guest.svc.cluster.local:8080 | 实际需要根据步骤6中发布的应用地址进行修改。备注:修改guest-p1176-s6772为实际应用名称即可 |
填写完毕后,点击上传并安装,完成安装后,点击启用
同时点击该前端应用的应用入口,例如示例地址:https://2fc9d4e8-dbc7-5e60-b6d3-df4b1bcf18ee-0.online.linktimecloud.com/
即可访问发布的薅羊毛神器应用,用户实际使用时,系统会对用户行为数据进行采集,通过采集的行为数据进行模型训练,以提高商品推荐的精准度。


备注:由于系统采集的数据为非实时采集,因此会出现部分商品访问时已下架的情况。
欢迎访问网站,注册体验BDOS Online,网站地址:https://bo.linktimecloud.com/

留言
评论
${{item['author_name']}} 回复 ${{idToContentMap[item.parent] !== undefined ? idToContentMap[item.parent]['author_name'] : ''}}说 · ${{item.date.slice(0, 10)}} 回复
暂时还没有一条评论.