直播平台弹幕分析
直播平台弹幕分析
项目背景
直播平台热度分析项目,通过抓取视频直播平台弹幕,分析弹幕频率、弹幕内容从而快速定位主播精彩视屏时间点,帮助创作者定位监控主播高光时刻,获取短视屏素材,同时通过分析热词弹幕了解主播粉丝趣向,帮助创作者创作出符合粉丝趣味的短视屏并发布到相关短视频平台,从而吸引流量,实现热度短视频引流。
项目步骤概述
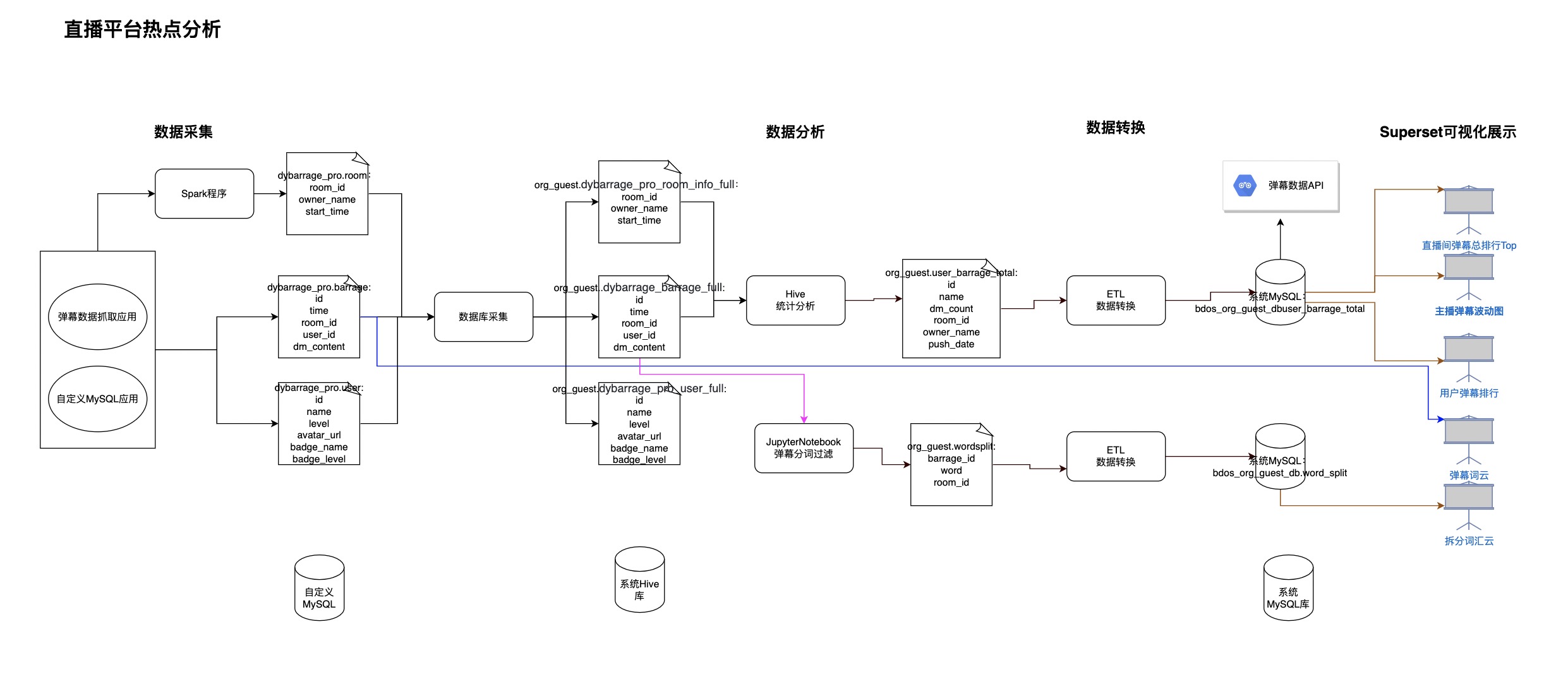
1.发布自定义MySQL应用和自定义数据采集应用,将某直播平台某直播间(指定直播间)的弹幕数据采集到自定义MySQL数据库表里。采集的数据信息包括用户信息、用户发送弹幕信息。(备注:步骤里的API可以给有需要弹幕数据研究的开发者提供弹幕数据)2.通过Spark程序,对MySQL数据进行处理,生成房间信息表3.将自定义MySQL应用的数据采集到Online系统的Hive库表,包括:用户信息表、用户发送弹幕表、直播房间信息表。采集总数据量4万多条。4.Hive数据分析,将用户发送的弹幕进行统计分析,并将结果表导出至Online系统指定的MySQL库,同时把数据发布成数据服务供其他应用调用。5.使用Jupyter对弹幕数据进行清洗及处理,去除无意义的字符,同时进行弹幕分词、统计出高频词汇,并将数据导出至Online系统指定的MySQL库,以便进行BI可视化展示。6.数据图表可视化展示,展示图表如下:
- 直播间弹幕总量排行top
- 主播弹幕数量随时间波动图(分钟级别)
- 用户发送弹幕总量排行
- 弹幕词云
- 分词后的弹幕词云
项目操作步骤
创建项目
点击添加项目,创建个人/机构项目(可通过角色切换,创建个人或者机构类型的项目)
添加步骤
1.1 发布自定义 MySQL 应用
点击【数据应用-Docker应用(通过配置)】,添加Docker应用步骤,并填写配置信息
| 类别 | 名称 | 内容 |
|---|---|---|
| 容器镜像 | 选择通过镜像地址安装 | 镜像地址:bdos-docker-registry.linktimecloud.com/linktime-mysql:0.9.27 |
| 容器参数 | 容器日志目录 | /var/log/mysql/ |
| 网络配置 | 序号0 | 容器端口:3306,Protocol:TCP,勾选负载均衡 |
| 序号1 | 容器端口:9104,Protocol:TCP (不勾选负载均衡) |

通用配置
| 名称 | 内容 | 备注 |
|---|---|---|
| CPU | 0.5 | 单位:核 |
| MEM | 4096 | 单位:MB |
| DISK | 1 | |
| Instances | 1 |

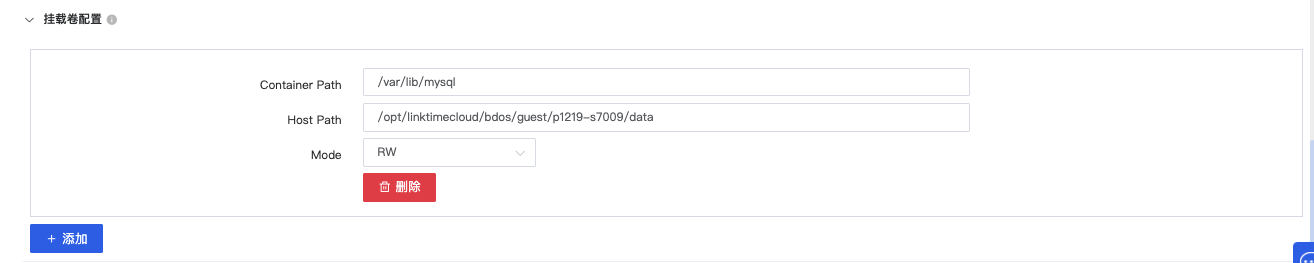
挂载卷配置
| 名称 | 内容 | 备注 |
|---|---|---|
| Container Path | /var/lib/mysql | |
| Host Path | /opt/linktimecloud/bdos/guest/p1219-s7009/data | 根据实际的安全组和应用名称进行修改:<guest>为示例机构名,<p1219-s7009>为该应用的名称 |
| Mode | RW | 读写模式 |
环境变量
| 名称 | 内容 | 备注 |
|---|---|---|
| 键:DATA_SOURCE_NAME | 值:root:123456@(localhost:3306)/mysql | 根据实际发布的MySQL连接配置信息进行修改,本示例中选用的MySQL基础镜像的账密为root:123456 |
| MYSQL_ROOT_PASSWORD | 123456 | 根据实际发布的MySQL连接配置信息进行修改,本示例中选用的MySQL基础镜像的密码为:123456 |

填写完毕后,点击上传并安装,安装完成后,点击启用
发布自定义MySQL应用后,可通过配置进行数据库连接(仅限机构Admin角色和DevOps角色进行表的添加):
通过导航【管理-机构/个人数据源管理】,选择采集和导出数据源-MySQL,点击新建连接
数据源配置
| 名称 | 内容 | 备注 |
|---|---|---|
| 名称 | barrage | 可自定义别名 |
| Driver | 保持默认 | |
| 数据库名称 | dybarrage_pro | 需参照示例进行填写 |
| 主机 | guest-p1219-s7009-svc.guest.svc.cluster.local | 跟进实际情况进行修改:<guest>为机构名,<p1219-s7009>为应用名称 |
| 端口 | 3306 | |
| 用户名 | root | |
| 密码 | 123456 |
点击测试连接后,点击更新
测试连接后,可通过三方工具对发布的MySQL库进行连接,并手动创建MySQL库:dybarrage_pro
1.2 发布直播平台弹幕数据采集应用
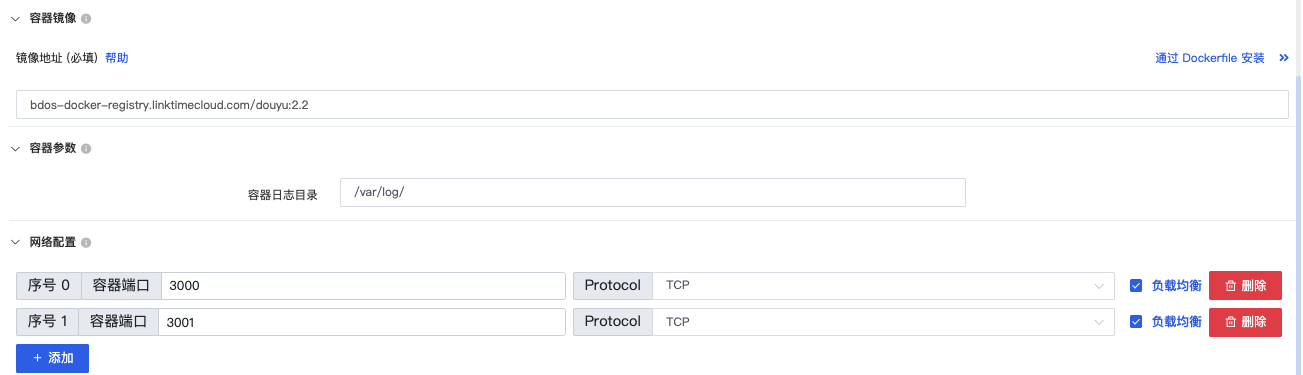
点击【数据应用-Docker应用(通过配置)】,添加Docker应用步骤,并填写配置信息
| 类别 | 名称 | 内容 |
|---|---|---|
| 容器镜像 | 选择通过镜像地址安装 | bdos-docker-registry.linktimecloud.com/douyu:2.2 |
| 容器参数 | 容器日志目录 | /var/log/ |
| 网络配置 | 序号0 | 容器端口:3000,Protocol:TCP,勾选负载均衡 |
| 序号1 | 容器端口:3001,Protocol:TCP ,勾选负载均衡 |
*通用配置8
| 名称 | 内容 | 备注 |
|---|---|---|
| CPU | 0.5 | 单位:核 |
| MEM | 2548 | 单位:MB |
| Disk | 1 | |
| Instances | 1 |

环境变量
| 名称 | 内容 | 备注 |
|---|---|---|
| 键:MYSQL_ADDRESS | 值:guest-p1219-s7009-svc.guest | 根据实际发布应用的机构和应用名称进行修改:<guest>为机构名,<p1219-s7009>为该应用的名称 |

填写完毕后,点击上传并安装,安装完成后,点击启用
2.生成房间信息表
步骤前置工作:创建房间信息表
点击【集成工具-Hue】登陆工具Hue,点击【Notebook-Editor-MySQL】,输入如下代码创建MySQL房间信息表:
CREATE TABLE `room_info` (
`room_id` varchar(25) COLLATE utf8mb4_bin NOT NULL,
`owner_name` varchar(255) COLLATE utf8mb4_bin NOT NULL,
`start_time` datetime NOT NULL,
PRIMARY KEY (`room_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin
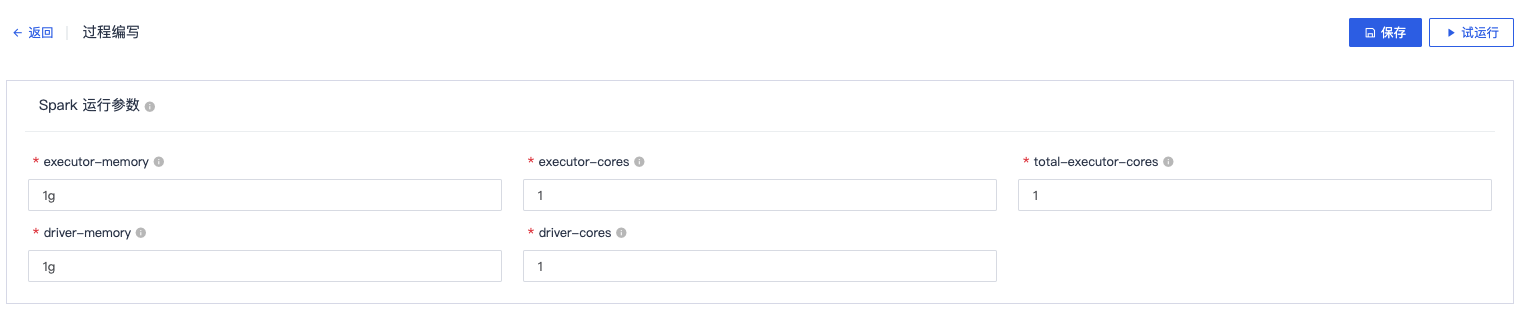
添加【数据分析-Spark程序】步骤
Spark运行参数
| 名称 | 内容 | 备注 |
|---|---|---|
| executor-memory | 1g | 保持默认 |
| executor-cores | 1 | 保持默认 |
| total-executor-cores | 1 | 保持默认 |
| driver-memory | 1g | 保持默认 |
| driver-cores | 1 | 保持默认 |
Spark-Python程序配置

Spark-Python程序配置
填写完毕后,点击保存,点击试运行
3.1 房间信息采集
点击【数据采集-数据库采集】进行步骤添加
采集数据源配置
备注:需要联系BDOS Online运营人员,启动后台数据采集应用
| 名称 | 内容 | 备注 |
|---|---|---|
| 数据源 | barrage | 填写添加自定义MySQL应用所填写的数据库别名 |
| 表 | room_info | 发布直播平台弹幕数据采集应用并进行数据采集后,会自动生成该表 |
| 数据范围 | 全量 |
采集目标配置
| 名称 | 内容 | 备注 |
|---|---|---|
| 是否需要对数据进行分区 | 用户自定义是否勾选进行数据分区 | |
| Hive数据库名称 | 下拉框选择目标Hive库(避免使用公共Hive库:public_project_data | |
| Hive表名称 | 保持默认(也可自定义修改,避免重名) | |
| HDFS存储路径 | 保持默认 |
点击保持后,点击试运行
3.2 用户信息采集
点击【数据采集-数据库采集】进行步骤添加
采集数据源配置
备注:需要联系BDOS Online运营人员,启动后台数据采集应用
| 名称 | 内容 | 备注 |
|---|---|---|
| 数据源 | barrage | 填写添加自定义MySQL应用所填写的数据库别名 |
| 表 | user | 发布直播平台弹幕数据采集应用并进行数据采集后,会自动生成该表 |
| 数据范围 | 全量 |
采集目标配置
| 名称 | 内容 | 备注 |
|---|---|---|
| 是否需要对数据进行分区 | 用户自定义是否勾选进行数据分区 | |
| Hive数据库名称 | 下拉框选择目标Hive库(避免使用公共Hive库:public_project_data | |
| Hive表名称 | 保持默认(也可自定义修改,避免重名) | |
| HDFS存储路径 | 保持默认 |
点击保持后,点击**试运行
3.3 弹幕数据采集
点击【数据采集-数据库采集】进行步骤添加
采集数据源配置
备注:需要联系BDOS Online运营人员,启动后台数据采集应用
| 名称 | 内容 | 备注 |
|---|---|---|
| 数据源 | barrage | 填写添加自定义MySQL应用所填写的数据库别名 |
| 表 | Barrage | 发布直播平台弹幕数据采集应用并进行数据采集后,会自动生成该表 |
| 数据范围 | 全量 |
采集目标配置
| 名称 | 内容 | 备注 |
|---|---|---|
| 是否需要对数据进行分区 | 用户自定义是否勾选进行数据分区 | |
| Hive数据库名称 | 下拉框选择目标Hive库(避免使用公共Hive库:public_project_data | |
| Hive表名称 | 保持默认(也可自定义修改,避免重名) | |
| HDFS存储路径 | 保持默认 |
点击保持后,点击**试运行
4.1 Hive统计分析-生产用户弹幕数据表
点击【数据分析-Hive程序】添加Hive程序步骤
-- 用户需要根据实际情况修改Hive库名:org_<机构名>
use org_guest;
drop table if EXISTS user_barrage_total;
CREATE TABLE `user_barrage_total`(
`id` int,
`name` string,
`dm_count` int,
`room_id` string,
`owner_name` string,
`push_date` TIMESTAMP
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
insert into table user_barrage_total
select ROW_NUMBER()over() as id,t2.name,count(1) as dm_count,t1.room_id,t3.owner_name,cast(from_unixtime(cast(`time`/1000 as int),'yyyy-MM-dd HH:mm:ss') as timestamp)
from dybarrage_pro_barrage_full01 t1,dybarrage_pro_user_full01 t2,dybarrage_pro_room_info_full01 t3
where t1.user_id = t2.id and t3.room_id = t1.room_id
group by t2.name,t3.owner_name,t1.room_id,cast(from_unixtime(cast(`time`/1000 as int),'yyyy-MM-dd HH:mm:ss') as timestamp) ;
点击保存后,点击试运行
4.2 用户弹幕统计表导出到系统MySQL
点击【数据转换-ETL程序】添加步骤
输入源配置
| 名称 | 内容 | 备注 |
|---|---|---|
| 数据源类型 | Hive | |
| 数据库 | 下拉框选择Hive步骤使用的数据库 | |
| 表 | 下拉框选择Hive步骤的输出表 | |
| Query | 保持默认 |
输出源配置
| 名称 | 内容 | 备注 |
|---|---|---|
| 数据源类型 | MySQL | |
| 数据源 | 下拉框选择目标MySQL数据源 | |
| 方式选择 | 可选择创建新表 | |
| 新表名 | 用户自定义 | |
| 设置主键 | 保持默认 | |
| 建表语句 | 点击获取建表语句 | |
| 数据变更 | Update | 保持默认 |
点击保存后,点击试运行
4.3 弹幕数据服务
点击【数据服务-API】,增加API步骤
API信息
| 名称 | 内容 | 备注 |
|---|---|---|
| API路径 | /user/barrage/total | 可自定义修改 |
| 请求方式 | Get |
API访问配置
| 名称 | 内容 | 备注 |
|---|---|---|
| 数据源 | 下拉框选择目标数据源(系统已提供可用的数据服务数据源:DS-ds-<机构名>) | |
| 使用自定义sql | 示例:开启:select * from bdos_org<机构名>db.<MySQL表名> limit 20 | 用户根据实际需要修改SQL进行数据筛选或全量选择 |
API访问控制
如无访问控制的限制,可保持默认
点击保存,点击测试后,点击发布
5.1 创建分词表:word_split
点击【数据分析-Hive程序】,添加Hive程序步骤
-- 用户需要根据实际使用的机构名称进行Hive库名的替换:org_<机构名>
use org_guest;
CREATE TABLE if not EXISTS `word_split`(
`barrage_id` string,
`word` string,
`room_id` string
)
点击保存,点击试运行
5.2 弹幕分词过滤并存储至分词表
点击【数据分析-JupyterNotebook】,添加JupyterNotebook步骤
点击进入Jupyter后,点击pyspark进入代码运行环境
def is_chinese(string):
"""
检查整个字符串是否包含中文
:param string: 需要检查的字符串
:return: bool
"""
for ch in string:
if u'\u4e00' <= ch <= u'\u9fff':
return True
return False
from pyspark.sql import HiveContext
from pyspark import SparkConf,SparkContext
from pyspark.sql import SparkSession
from datetime import datetime, date
from pyspark.sql import Row
import jieba
spark.sql("use org_guest");
# while 1:
df = spark.sql('select id,dm_content,room_id from dybarrage_pro_barrage_full where id not in (select distinct barrage_id from word_split) limit 1');
rows = df.collect()
print(rows)
from pyspark.sql import HiveContext
from pyspark import SparkConf,SparkContext
from pyspark.sql import SparkSession
from datetime import datetime, date
from pyspark.sql import Row
import jieba
spark.sql("use org_guest");
# while 1:
df = spark.sql('select id,dm_content,room_id from dybarrage_pro_barrage_full where id not in (select distinct barrage_id from word_split)limit 1000');
rows = df.collect()
# if rows is None or len(rows)==0:
# break
list = []
count = 1
start = "insert into table word_split values"
sqlList = []
# filterList = (')',' ','?','!','@','#','$','%','&','*','?','。','!','@','#','¥','%','&','*',';','.','"',"“")
for row in rows:
barrage_id = row["id"]
roomId = row["room_id"]
dm_content = row["dm_content"]
arry = jieba.lcut(dm_content)
for word in arry:
if len(word) > 1 and is_chinese(word):
split = "(\"{}\",\"{}\",\"{}\")".format(barrage_id, word,roomId);
list.append(split)
if count % 50 == 0:
if len(list)>0:
sql = start + ",".join(set(list))
sqlList.append(sql)
list.clear()
count = count + 1
if len(list) > 0:
sqlList.append(start + ",".join(set(list)))
for sql in sqlList:
spark.sql(sql);
5.3 导出弹幕分词表到系统MySQL
点击【数据转换-ETL程序】,添加ETL程序步骤
输入源配置
| 名称 | 内容 | 备注 |
|---|---|---|
| 数据源类型 | Hive | |
| 数据库 | 下拉框选择机构Hive数据库:org_<机构名> | |
| 表 | word_split | 下拉框选择分词表:word_split |
| Query | 保持默认,也可根据需要进行筛选 |
输出源配置
| 名称 | 内容 | 备注 |
|---|---|---|
| 数据源类型 | MySQL | |
| 数据源 | FM-ds-<机构名> | 下拉框选择机构MySQL数据库:org_<机构名> |
| 方式选择 | 创建新表 | 创建MySQL表:word_split |
| 设置主键列 | 点击获取建表语句 | |
| 数据变更 | Update |
点击保存,点击试运行
欢迎访问网站,注册体验BDOS Online,网站地址:https://bo.linktimecloud.com/

留言
评论
${{item['author_name']}} 回复 ${{idToContentMap[item.parent] !== undefined ? idToContentMap[item.parent]['author_name'] : ''}}说 · ${{item.date.slice(0, 10)}} 回复
暂时还没有一条评论.