利用Hue玩转Hive
目录
背景介绍
简介
步骤1: 创建hive_demo表, 加载kafka数据
步骤2: 统计 hive_demo 中 name 字段
背景介绍
Hive 是基于Hadoop的一个数据仓库工具, 可以将结构化的数据文件映射为一张数据库表, 并提供简单的sql查询功能, 可以将语句转换为MapReduce任务进行运行. Hue 是一个开源的智能分析工作台. 本教程通过使用Hive处理Kafka数据流水线产生的数据, 来帮助用户了解和使用BDOS平台和Hive.
简介
因为需要Kafka流程抽取MySQL源数据, 写入HDFS, 所以在使用本教程之前, 需要你先按照BDOS平台上部署Kafka数据流水线, 完成HDFS数据的写入. 如果你已经完成上面流程, 请继续本教程.
BDOS平台社区版在集群启动的时候已经预安装了本教程所需要的应用, 你只需要参照以下2个步骤:
- 创建hive_demo表, 加载kafka数据
- 统计 hive_demo 中 name 字段以 A, B, C, D, E 开头的记录数量并存入到Hive的 hive_demo_count 表
步骤1 创建hive_demo表, 加载kafka数据
1.1 进入Hue主页
在BDOS左侧菜单找到菜单当前运行应用->官方应用, 会展示已安装的应用, 如下图
 点击应用名称hue, 进入Hue详情页面, 如下图
点击应用名称hue, 进入Hue详情页面, 如下图

点击首页, 打开Hue管理页面, 需要先创建一个账户dcos, 如下图(输入用户名, 密码即可创建)

点击 Create Account, 创建账户, 创建成功后页面跳转到Hue主页, 如下图
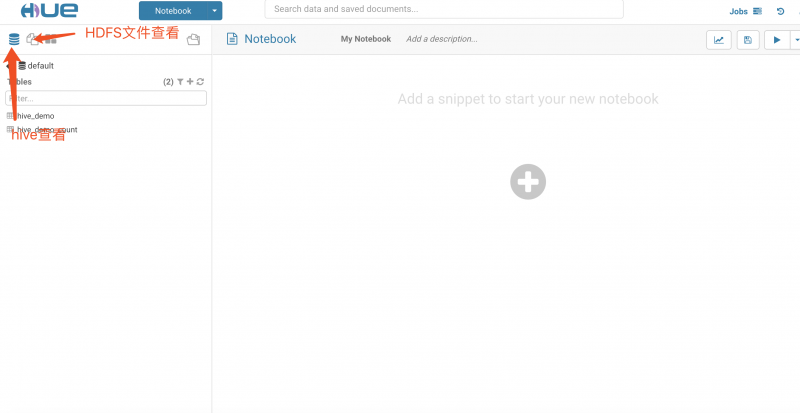
打开Hive操作界面, 如下图
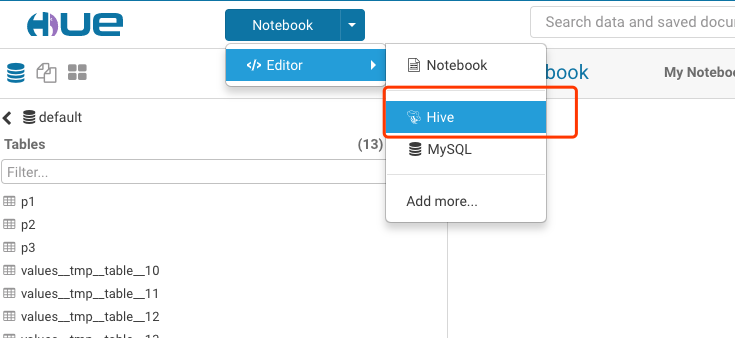
- 目前系统集成的Hue只支持HDFS文件操作、Hive操作、MySQL数据查看
1.2 创建hive_demo
在编辑区填入下面的Hive语句
CREATE TABLE hive_demo
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.avro.AvroSerDe'
STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.avro.AvroContainerInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.avro.AvroContainerOutputFormat'
TBLPROPERTIES ( 'avro.schema.literal'='{"namespace": "com.linktime.hive_demo",
"name": "schema",
"type": "record",
"fields": [
{ "name":"id", "type":"long" },
{ "name":"code", "type":"string" },
{ "name":"name", "type":"string" },
{ "name":"type", "type":"string" },
{ "name":"price", "type":"long" },
{ "name":"excellent", "type":"long" },
{ "name":"create_time", "type":"long" },
{ "name":"creator_id", "type":"string" },
{ "name":"catalogue_from", "type":"string"},
{ "name":"org_name", "type": "string"},
{ "name":"update_time", "type":"long"}
]
}'
)
- 语法解释请参考AvroSerDe
点击运行按钮, 展示如下图

成功以后, 会在左侧列表中展示hive_demo.
1.3 查看kafka文件, 复制文件名称
点击左上角的HDFS图标 , 下面会列出HDFS上的文件目录, 先切换到根目录下, 然后选择文件目录[kafka] -> [topics] -> [mysql] -> [mysql_product] -> [partition=0],然后点击左下方文件列表中的任意文件即可查看它的内容, 文件加载内容出来会消耗一定时间, 如果时间过长, 可以通过复制浏览器地址里的文件名, 直接进行下一步. 展示结果如下图
, 下面会列出HDFS上的文件目录, 先切换到根目录下, 然后选择文件目录[kafka] -> [topics] -> [mysql] -> [mysql_product] -> [partition=0],然后点击左下方文件列表中的任意文件即可查看它的内容, 文件加载内容出来会消耗一定时间, 如果时间过长, 可以通过复制浏览器地址里的文件名, 直接进行下一步. 展示结果如下图

1.4 从HDFS加载kafka数据到hive_demo表
重新打开Hive操作界面, 通过下面Hive语句把目录下的其中一个文件数据加载到hive_demo中
load data inpath '/kafka/topics/mysql_product/partition=0/{{file_name}}' into table hive_demo;
- 用
步骤1.3复制的文件名替换{{file_name}}
点击运行按钮, 展示如下图
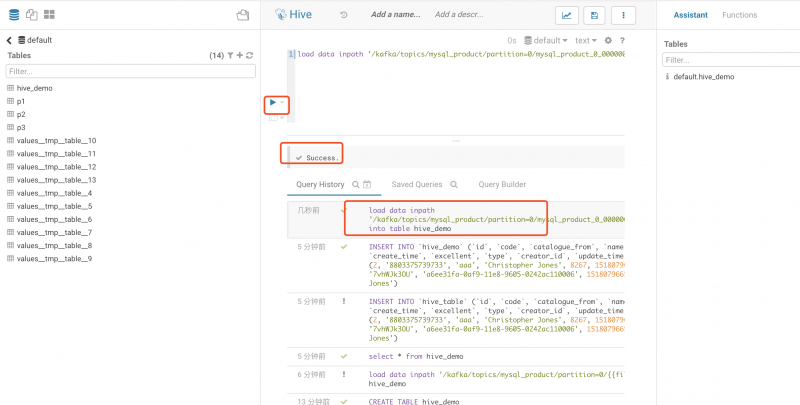
成功以后, 通过下面查询语句查看结果
select * from hive_demo
展示如下图

说明已经加载数据成功.
步骤2: 统计 hive_demo 中 name 字段以 A, B, C, D, E 开头的记录数量并存入到Hive的 hive_demo_count 表
首先创建hive_demo_count表, 输入下面SQL,
CREATE TABLE IF NOT EXISTS hive_demo_count(A INT, B INT, C INT, D INT, E INT);
成功以后, 然后通过下面的SQL统计hive_demo表中的数据
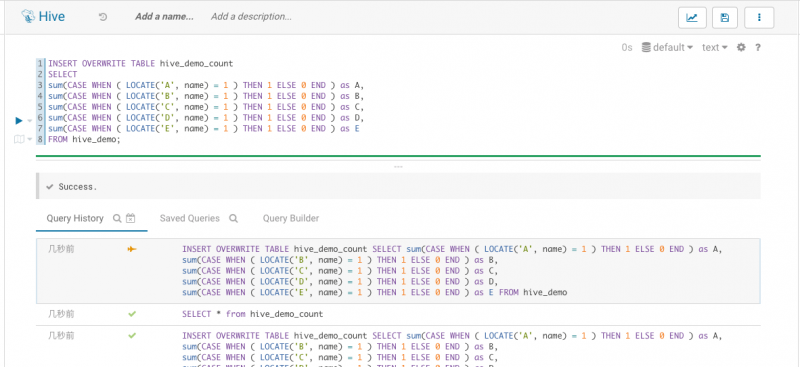
INSERT OVERWRITE TABLE hive_demo_count
SELECT
sum(CASE WHEN ( LOCATE('A', name) = 1 ) THEN 1 ELSE 0 END ) as A,
sum(CASE WHEN ( LOCATE('B', name) = 1 ) THEN 1 ELSE 0 END ) as B,
sum(CASE WHEN ( LOCATE('C', name) = 1 ) THEN 1 ELSE 0 END ) as C,
sum(CASE WHEN ( LOCATE('D', name) = 1 ) THEN 1 ELSE 0 END ) as D,
sum(CASE WHEN ( LOCATE('E', name) = 1 ) THEN 1 ELSE 0 END ) as E
FROM hive_demo;
如下图
成功以后查询统计结果
SELECT * FROM hive_demo_count
如下图

如果有记录查出来, 说明Hive程序已经运行成功.
本文只是简单介绍了如何通过Hive处理数据, BDOS企业版提供的ETL组件支持数据抽取, Hive数据处理, 数据导出等调度功能, 如果要进一步了解相关内容, 请查看Blog ETL Quick Start
如果对教程有任何疑问,请截图发邮件至 admin@linktime.cloud
留言
评论
${{item['author_name']}} 回复 ${{idToContentMap[item.parent] !== undefined ? idToContentMap[item.parent]['author_name'] : ''}}说 · ${{item.date.slice(0, 10)}} 回复
暂时还没有一条评论.